在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数据点。插值是离散函数逼近的重要方法,利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值。曲面插值是对三维数据进行离散逼近的方法,MATLAB中的曲面插值函数有Triscatteredinterp,interp2,griddata等。我们以griddata为例讲解曲面插值及其交叉验证的过程。
一、 gridata曲面插值
gridata不仅可以对三维曲面进行插值,还能对四维的超平面进行插值。griddata的调用方法:ZI = griddata(x,y,z,XI,YI,method);[XI,YI,ZI] = griddata(x,y,z,XI,YI,method)。插值方法有'linear'以三角形为基础的线性内插、'cubic'以三角形为基础的三次方程内插,'natural'自然邻近插值,'nearest'最近邻近插值,'v4'由MATLAB提供的插值方法,默认值为'linear'。三角形为基础,就是按Delaunay方法先找出内插点四周的3个点,构成三角形,内插点在三角形内。然后线性内插,或三次方程内插。 'cubic' 和 'v4' 插值结果构成的曲面较光滑。
我们可以用griddata函数来求得未知点的Z值,进而绘制曲面的大致图像,代码如下
[X,Y]=meshgrid(min(x):0.1:max(x),min(y):0.1:max(y)); %确定网络坐标 Z=griddata(x,y,z,X,Y,'cubic'); %在网格点位置插值求Z surf(X,Y,Z) %绘制曲面 title 'Points to Surface by griddata'
所得的结果如下
二、 拟合精度指标
做完曲面插值后,如何对曲面插值模型的拟合好坏进行评判是我们应该考虑的问题。MATLAB曲面拟合工具箱cftool中无论曲面插值还是函数拟合都用拟合优度R-squared来评判拟合效果的好坏。其公式为

其中,y为实际值, y^为预测值, y*为y的平均值。
个人觉得函数拟合可以用此指标评判,但曲面插值用此指标有些不妥。故介绍一个新的评判插值效果的指标,公式为

符号含义与上式相同,虽然R-squared有很多很好的数学性质,但对于前提假设不明确的模型来说,用拟合度指标r显得更直观些,即1扣除残差平均占实际平均的比例。
下面我们来对比两个指标随样本点增加的变化情况,代码如下
function r=FitLevel(y0,y1) %拟合度指标的公式。y0为真实值,y1为预测值
%r=sum((y1-mean(y0)).^2)/sum((y0-mean(y0)).^2);%拟合优度R-squared
r=1-sqrt(sum((y1-y0).^2)/sum(y0.^2)); %拟合度指标
%绘制拟合度指标随样本数增加的变化图
step=1;
I=1000:1000:length(x)
for i=I
Z=griddata(x(1:i),y(1:i),z(1:i),x(1:i),y(1:i));
r=FitLevel(z(1:i),Z); %求拟合度指标
R(step)=r;
step=step+1
end
plot(I,R)
title '拟合度-样本点数'
拟合优度和新的拟合度随样本点增加的变化情况图如下
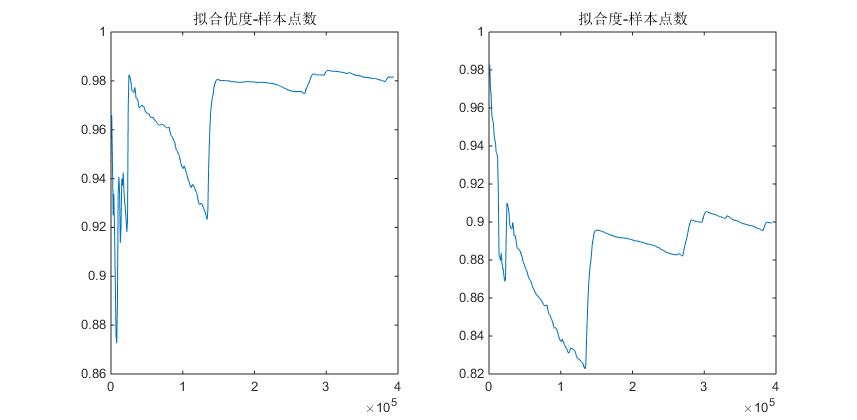
虽说这两幅图曲线的形状有点类似,但拟合优度那副比较平稳,新的拟合度波动幅度较大,从数值上分析,还是新的拟合度指标较为合理的。在交叉验证那节还可发现用拟合优度去检验预测效果值大于1,超出它的取值范围,故若要用交叉验证算法检验插值效果还是得用新的拟合度指标的。
三、 交叉验证
常用的精度测试方法主要是交叉验证,交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。在此基础上,反复的做训练、测试以及模型的选择。包含简单交叉验证,K折交叉验证,留一验证,Holdout 验证等。结合业务场景,本文将把K折交叉验证和简单交叉验证结合使用。
K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次。10折交叉验证是最常用的。由于本次业务场景的数据并非空间数据,而是时序数据,所以并没有重复验证K次,而是用前K-1份样本用于训练模型,第K份样本用于测试模型。
四、应用实例
本次使用交叉验证的目的主要是为了在已测得足够量数据的情况下,寻找出适用于该样本的最优插值模型和该模型对应的最优样本量。
设训练模型的拟合度为r_train,理想阈值为train;测试模型的拟合度为r_test,理想阈值为test;整体拟合效果为:
r_total=weight*r_train+(1-weight)*r_train
其中weight为训练数据拟合度占整体拟合度重要程度的百分比,默认值0.5。求某一插值方法对应最优或理想样本量的算法如下:
1)建模次数step=1,步长为stepsize。当前训练样本量i
2)对(1,i)的所有数据进行插值,求出模型的拟合度r_train。
3) 对(i,(K/K-1)*i)的所有数据进行检验,求出检测的精度r_test。
4)判断r_total(step)> r_total(step-1),若是,则记录样本数i。
5)判断r_train>train且r_test>test,若是,则记录样本数i。
6)Step=step+1;i=i+stepsize;返回2),直到循环结束。
通过以上算法即可求出整体情况最优时的样本数和人工调节阈值时的样本数序列。根据此算法设计了CrossValidation函数,详细内容参见函数源文件,其输入输出的完整参数如下:
[Result,R_total]=CrossValidation(x,y,z,train,test,weight,method,stepsize,folder)
我们先输入一些参数看看函数的输出结果
Result=CrossValidation(x,y,z,0.89,0.7,0.6,'cubic',1000)
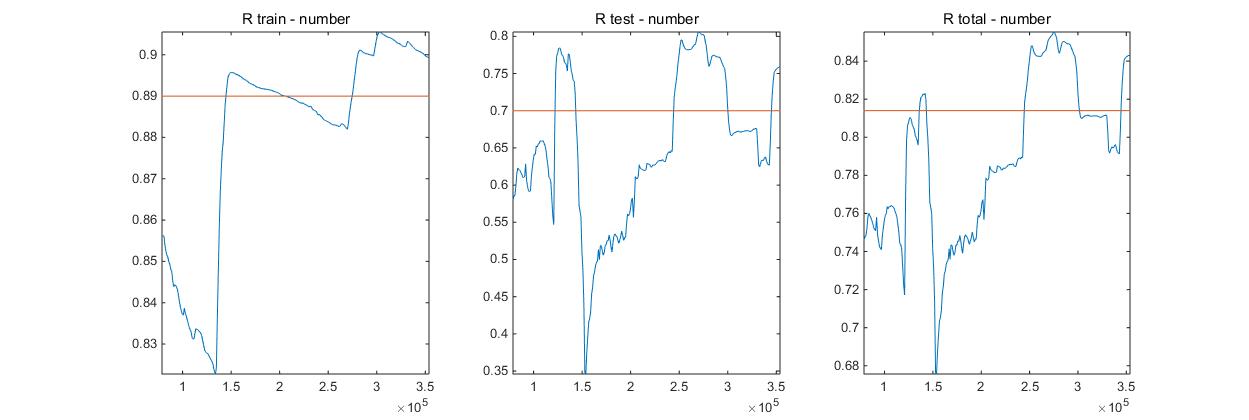
最终打印出了训练模型拟合度指标r_total随样本数增加而变化的图形、测试数据精度指标r_test随样本数增加而变化的图形和总体拟合效果随样本数增加而变化的图形。

还返回了一个Result矩阵,第一行为样本数i,第二行为训练模型拟合度r_train,第三行为测试拟合度r_test。第一列为总体拟合效果最大时返回的值,第二列及之后的列是r_train>train且r_test>test时返回的值。可见,275000左右的样本数就能很好的用于该插值模型了。
该函数还可以输出整体拟合指标序列R_total,可用于对比不同方法对该样本的拟合水平。通过判断sum(R_total1>R_total2)/length(R_total1)是否大于0.5来判断谁优谁劣,若大于0.5,则说明输出R_total1序列的方法拟合水平较高。下面是一段对比的实例。
[R1,r1]=CrossValidation(x,y,z,0.89,0.7,0.6,'nearest',10000); [R2,r2]=CrossValidation(x,y,z,0.89,0.7,0.6,'linear',10000); [R3,r3]=CrossValidation(x,y,z,0.89,0.7,0.6,'natural',10000); [R4,r4]=CrossValidation(x,y,z,0.89,0.7,0.6,'cubic',10000); sum(r1>r2)/length(r1) %返回0,说明r2所有值都大于r1 sum(r3>r2)/length(r2) %返回1,说明r3所有值都大于r2 sum(r4>r3)/length(r3) %返回0,说明r3所有值都大于r4
可见,自然邻近插值法拟合精度高于其他几种方法,比较适用于该样本。不过对比R1、R2、R3、R4后发现这四种方法都能找出相同的最优样本点,应该是拟合度指标变化趋势相同的原因。
以上论述已实现求理想样本点和理想插值方法的需求。由于我使用的工程数据具有保密性,不便附上源数据,可自己随机生成数据进行测试,下面附上对插值模型进行交叉验证的函数源码。
function [Result,R_total]=CrossValidation(x,y,z,train,test,weight,method,stepsize,folder)
% CrossValidation:曲面插值交叉验证。把样本分为训练数据和测试数据,并对训练数据
% 进行曲面插值,求出起训练集拟合精度,用该模型对测试数据进行预
% 测,求出测试集的拟合精度。最终求出或人为判断出该样本较为合理
% 的用于拟合插值模型的样本数。
%
% usage #1: [Result,R_total]=CrossValidation(x,y,z);
% usage #2: [Result,R_total]=CrossValidation(x,y,z,train,test);
% usage #3: [Result,R_total]=CrossValidation(x,y,z,train,test,weight);
% usage #4: [Result,R_total]=CrossValidation(x,y,z,train,test,weight,method);
% usage #5: [Result,R_total]=CrossValidation(x,y,z,train,test,weight,method,stepsize);
% usage #6: [Result,R_total]=CrossValidation(x,y,z,train,test,weight,method,stepsize,folder);
%
% Arguments: (input)
%x,y,z - 输入向量
%train - 训练数据拟合度的理想阈值,范围(0,1),默认值0.8
%test - 测试数据拟合度的理想阈值,范围(0.1),默认值0.7
%weight - 训练拟合度相对于测试拟合度的权重,范围(0.1),默认值0.5
%method - 插值所用的方法,默认值'lineat',可选范围如下:
% 'nearest' - Nearest neighbor interpolation
% 'linear' - Linear interpolation (default)
% 'natural' - Natural neighbor interpolation
% 'cubic' - Cubic interpolation (2D only)
% 'v4' - MATLAB 4 griddata method (2D only)
%stepsize - 步长,子样本每次增加的数目,默认值为5000。
%folder - K折交叉验证的折数,默认值10.意味着把样本数分为10份,拿1份去验证。
%
%Result:返回一个Result矩阵和一个整体拟合效果队列R_total;一副训练数据随点数增
% 加的拟合效果图R_train-number,一副测试数据随点数增加的 拟合效果图
% R_test-number,一副整体情况随点数增加的拟合效果图R_total-number。
%
% Result = [ i(m) i(n) ...
% R_train(i(m)) R_train(i(n)) ...
% R_test(i(m)) R_train(i(n)) ... ]
% 第一列为整体拟合效果最大时对应的点数、训练数据拟合度,测试数据拟合度。
% 第二列及之后所有列为训练数据大于理想训练数据阈值train且测试数据大于测
% 试数据理想阈值test时的样本点数、训练数据拟合度,测试数据拟合度。
%
%
%Author: 小江同学
%e-mail: 842419386@qq.com
%设置参数默认值
if nargin==3
train=0.8;test=0.7;weight=0.5;method='linear';folder=10;stepsize=5000;
elseif nargin==5
weight=0.5;method='linear';folder=10;stepsize=5000;
elseif nargin==6
method='linear';folder=10;stepsize=5000;
elseif nargin==7
folder=10;stepsize=5000;
elseif nargin==8
folder=10;
end
%去除输入向量的空值
k = isnan(x) | isnan(y) | isnan(z);
if any(k)
x(k)=[];
y(k)=[];
z(k)=[];
end
%变量初始化
step=1; %循环次数
r_col=2; %返回Result矩阵的列数
r_max=0; %r_total的最大值
R_train=[]; %训练拟合度序列
R_test=[]; %测试拟合度序列
Result=[]; %返回结果
h1=plot(0,0); %动画初始化
hold on
h2=plot(0,0);
total=weight*train+(1-weight)*test; %整体拟合效果阈值
I=round(0.3*length(x)):stepsize:round((1-1/folder)*length(x)); %循环范围及步长
%交叉验证及寻找最优或理想样本数
for i=I
Z=griddata(x(1:i),y(1:i),z(1:i),x,y,method); %x(1:i),y(1:i),z(1:i)建模,预测x,y所对应的z值
z_temp=z;
N=find(isnan(Z)); %去除预测向量中的空值
Z(N)=[];z_temp(N)=[];
r_train=FitLevel(z_temp(1:i),Z(1:i)); %求训练模型拟合度
r_test=FitLevel(z_temp(i+1:i+round((1/(folder-1))*i)),Z(i+1:i+round((1/(folder-1))*i)));%测试模型的拟合度
R_train(step)=r_train;
R_test(step)=r_test;
r_total=weight*r_train+(1-weight)*r_test; %整体拟合度
R_total(step)=r_total;
Total(step)=total; %绘制R_total随样本数变化的动态图
set(h1,'xData',[1:step],'yData',R_total);
set(h2,'xData',[1:step],'yData',Total);
drawnow;
pause(0.1)
if r_max<r_total %寻找最优样本点
r_max=r_total;
Result(1,1)=i;
Result(2,1)=r_train;
Result(3,1)=r_test;
end
if r_train>train & r_test>test %寻找理想样本点列
Result(1,r_col)=i;
Result(2,r_col)=r_train;
Result(3,r_col)=r_test;
r_col=r_col+1;
end
step=step+1
end
%绘制返回结果图形
subplot(1,3,1) %训练拟合度—样本数
plot(I,R_train)
hold on
plot([I(1),I(length(I))],[train,train])
axis([I(1),I(length(I)),-inf,inf])
title 'R train - number'
subplot(1,3,2) %测试拟合度—样本数
plot(I,R_test)
hold on
plot([I(1),I(length(I))],[test,test])
axis([I(1),I(length(I)),-inf,inf])
title 'R test - number'
subplot(1,3,3) %整体拟合度—样本数
plot(I,R_total)
hold on
plot([I(1),I(length(I))],[total,total])
axis([I(1),I(length(I)),-inf,inf])
title 'R total - number'
format bank
%以下是几点程序说明
%(1)次函数运行还伴随着整体拟合度r_total随样本数增大而变化的动态效果,把它注释掉也不会影响程序运行结果。
%(2)我选拟合度指标不一定是最优的,如果还有更好的指标,可在FitLevel函数中修改。
%(3)交叉验证是一种验证模型精度的思想,不仅可用于检测插值模型精度,还可用于回归、分类、判别等模型中。
%(4)用K-1份数据建模,对第K份进行验证会导致最后K份数据无法加入最优样本数的选举中,可以通过增加折数
% 和减小步长改进,不过这样会减缓程序速度。