1.散列表
- 散列表是实现字典操作的一种有效数据结构,基本的字典操作只需要O(1)的时间。
- 最坏情况下散列表中查找一个元素的时间与链表中查找的时间相同,达到了θ(n),在一些合理假设下,在散列表中查找一个元素的平均时间是O(1)。
- 散列表是普通数组概念的推广。散列表使用一个长度与实际存储的关键字数目成比例的数组来存储,实际存储的关键字数目比全部的可能关键字的数目要小。这个数组称为直接寻址表,其中的每个位置称为槽。不是直接把关键字作为数组的下标,而是根据关键字计算出相应的下标,
- 冲突:指多个关键字映射到数组的同一个槽中。
- 冲突了肯定不行了,散列函数是解决冲突的办法。通过散列函数通过关键字k计算出槽的位置。
- 散列方法的平均性能依赖于所选取的散列表函数h将所有的关键字集合分布在m个槽位上的均匀长度。
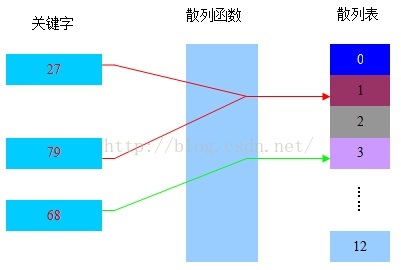
- 关键字、散列函数和散列表的关系如下:
2.常用处理冲突的方法
(1)链接法和
(2)开放寻址法
(3)在散列法
(4)建立一个公共溢出
容我在研究研究。。。。