写博以供备份。
之前看到 ijcai2019 的一篇论文 Out-of-sample Node Representation Learning for Heterogeneous Graph in Real-time Android Malware Detection。在这篇文章中,运用异构图对提取出来的特征进行了处理,具体来说提取的特征为五种节点和六种关系,在构建异构图后,作者使用 random walk 和 skip-gram 算法,对图中的节点进行了向量的表示,对于新的恶意软件,使用 k-order neighbour 算法进行新的恶意软件的表示的学习以达到实时检测恶意软件的效果,最后设计了一个分类器进行软件分类。在他的参考文献中,提到了两篇基于异构图的恶意软件检测我很感兴趣,阅读之后发现这两篇居然是同一位作者所写,分别发在 kdd2017 和 kdd2018 上,其提出的框架名分别为 HinDroid 和 Scorpion,同时,在下文中,我将用 ijcai2019文章中提出的 AiDroid 框架来代指 Out-of-sample Node Representation Learning for Heterogeneous Graph in Real-time Android Malware Detection 这篇文章。
阅读后显然发现,随着年份的不同,这三篇文章显然存在着递进的关系,所提出的框架越来越精进。
首先在 HinDroid 中,作者使用最普通的异构图对所提取的特征进行构图,并通过建立元路径来表示了 app 之间的关联,最后直接使用 multi-kernal 算法计算每条元路径的权重后,直接使用一个公式来对新的 app 进行分类以判别是否为恶意软件。在这篇文章中,作者在得到或者说建立了元路径后,并未对元路径再进行处理,只是进行赋了权重就完成了分类。
在2018年的 Scorpion 中,作者对自己去年的框架提出了一些改进,具体表现在两点:1.提出了 Meta-Graph 这个从元路径中衍生出来的概念,能够更好的表现软件之间更丰富的关系 2.提出了 Metagraph2vec 算法,主要是用来解决在 HinDroid 中直接用元路径赋权重就进行分类从而导致计算量和消耗资源巨大的问题,在 Metagraph2vec 中,作者用低维向量表示 HIN 中的节点,同时能够保留节点之间的结构和语义关系,降低了计算量和所需时间,最后使用 SVM 进行分类,无疑是一个较大的改进。
最后则是一开始阅读的这篇2019的 AiDroid,首先同样用异构图表示节点和他们之间的关联并定义了元路径,然后同样是用一种节点表示的方法保留了节点间结构和语义的关联,在这个过程中使用了 random walk 和 skip-gram 算法,和 Scorpion 有异曲同工之妙。接着便是 AiDroid 的独特之处,在前人的两篇文章中,都是静态的异构图设计,对于一些未知的恶意软件,没有样本外的节点表示,从而无法进行分类。在这篇文章中,提出了对应的样本外节点表示学习算法,即使用了 k-order neighbours 算法,可以在面对样本外的一些恶意软件时,能够自主学习对应的节点表示,从而可以达到实时检测的目的而无需频繁的进行训练。最后,AiDroid 还改进了分类算法,即使用了 CNN 和 Inception 结合的分类方法,较之间的 SVM 等也有所提升。
关于 HinDroid 的阅读笔记和 Scorpion 的阅读笔记均在下文给出,对 AiDroid 的笔记则在之前的博客中有。
论文标题分别是:HinDroid: An Intelligent Android Malware Detection System Based on Structured Heterogeneous Information Network, kdd2017 和 Gotcha - Sly Malware! Scorpion: A Metagraph2vec Based Malware Detection System, kdd2018
Hindroid (基于异构图信息网络的智能安卓恶意软件检测系统)
现有的大多是基于现有的 malware 库的方法识别恶意软件
本文:
同时使用 API calls 和 API 调用之间的高级语义关系来提高检测能力
构建 HIN (heterogeneous information network),然后使用元路径来表示 app 之间的高级语义关联 (即相似性),并通过 multi-kernel learning 计算,给每条元路径赋权重来进行预测。用于预测是否为 malware 的是由不同元路径定义的不同相似性的聚合。
本文中定义的高级语义关联包括:
-
API 之间的高级语义关联:
- API calls 来自同一代码块
- API calls 有相同的包名
- API calls 有相同的 invoke 方法
-
还有 API 与 app 之间的关系,app 之间的关系
方法
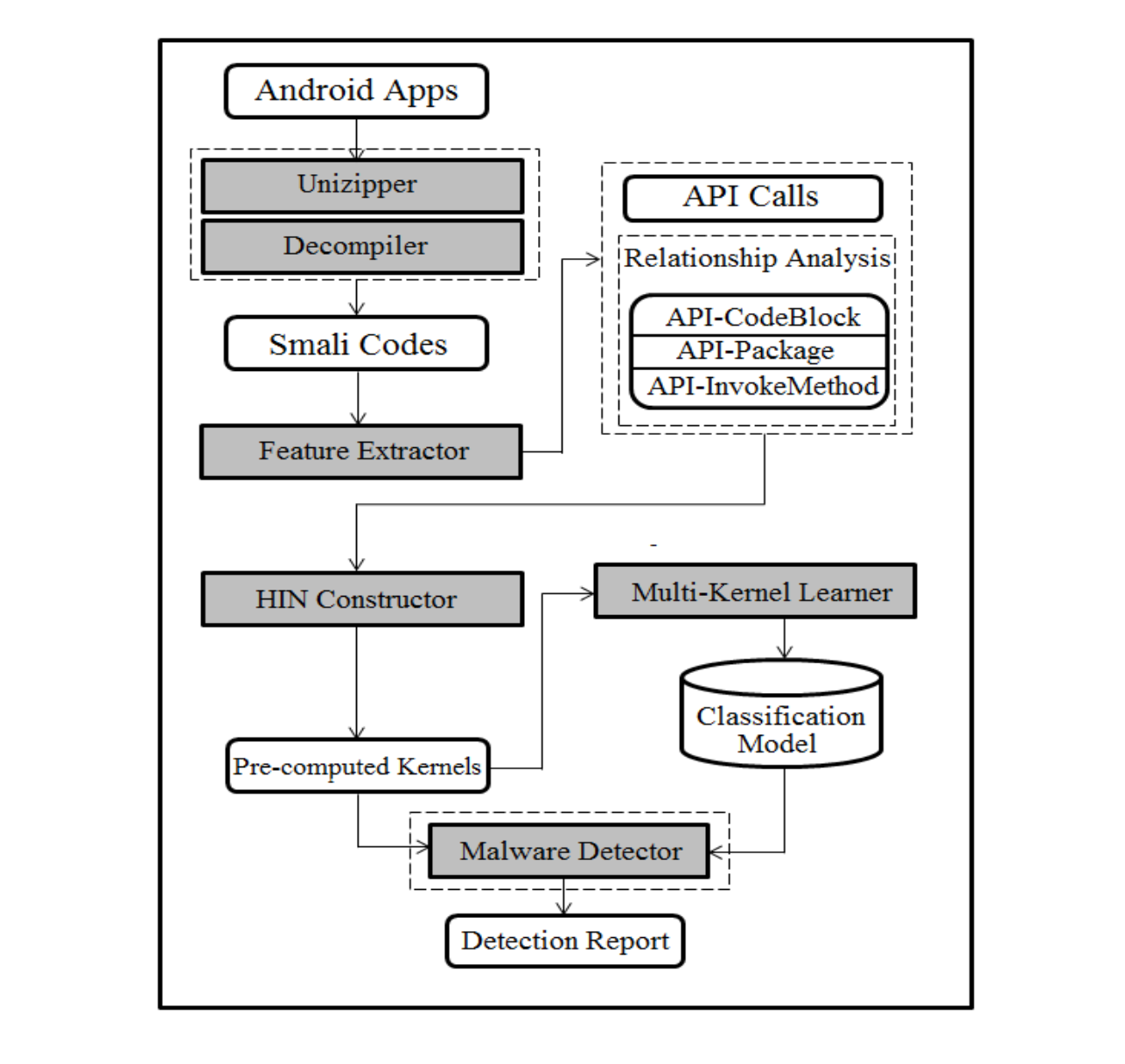
(1)特征提取 (API calls & relationships among them)
-
解压缩和反编译
使用 APKTool 将 dex 文件反编译为 smali code (Java 和 DalvikDM 的中间形态,可读性强)
-
从 smali code 中提取 API calls,并将这些 API calls 转换为一组全局整数 IDs,通过数字表示静态执行顺序 (即给这些 API calls 编了一个号,个人感觉本文中没有其他特殊意义)并定义了4种语义关系
-
R0, 矩阵 A: app i 包含了 API j,则对应的 aij = 1,其余为0
-
R1, 矩阵 B ( API-CodeBlock matrix B ): API calls 在同一个 smali code block 中,当第 i 个 API calls 和第 j 个 API calls 同在一个 code block 中时,对应的 bij = 1,其余为0
其中,code block 的定义为:smali code 中一对 ".method" 和 ".endmethod" 之间的代码定义为一个代码块
-
R2, 矩阵 P ( API-Package matrix P): API calls 在同一个 package 中,当第 i 个 API calls 和第 j 个 API calls 同在一个 package 中时,对应的 pij = 1,其余为0
-
R3, 矩阵 I (API-InvokeMethod matrix I): API calls 由同一种方法 invoke,当第 i 个 API calls 和第 j 个 API calls 由同一种方法调用时,对应的 iij = 1,其余为0
其中,invoke API calls 的五种方法:
- invoke-static:使用参数 invoke 静态方法
- invoke-virtual:使用参数 invoke 虚拟方法
- invoke-direct:invoke 带有参数的方法但没有虚拟方法的 resolution
- invoke-super:invoke 直接父类的虚拟方法
- invoke-interface:invoke 接口方法
-

(2)HIN 构建
有两种节点 (app 和 API calls) 和四种关系 (上述的4种语义关系 R0 到 R4)
使用元路径来建立节点之间的高级语义关联 (主要是两个 app 之间的关联,即元路径的两端均为 app),使用可交换矩阵 (commuting matrix Mp)来计算一条具体的元路径表示的尸体相似性 (本文中即两个 app 的相似性,Mp 由一系列邻接矩阵相乘表示,在本文中邻接矩阵为上述四种语义关系的矩阵,即 A, B, P, I)
在本文中共定义了16种元路径:

简单举例,第一条元路径即为元路径两端的 app 包含了同一个 API,第二条元路径即为元路径两端的 app 包含了同一个代码块中的 API,以此类推。
(3)学习各条元路径的权重
使用 multi-kernel 方法计算每条元路径的权重
对于 k 条元路径,将每个可交换矩阵 Mpk 视作一个 kernel,然后使用线性组合的方法得到一个新的 kernel M:
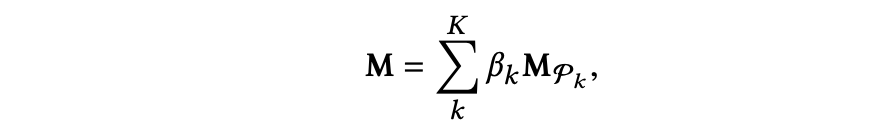
其中,权重 βk大于等于0且所有 βk 的和为 1,βk 用来表示对应的第 k 条元路径的重要程度
需要求得的参数为 βk 和 Wk
假定有 n 个标签数据 { xi, yi }, 其中 xi 为 一个 ID,yi 取值为 +1 和 -1,使用 p-norm multi-kernal learning, 其中,目标函数为
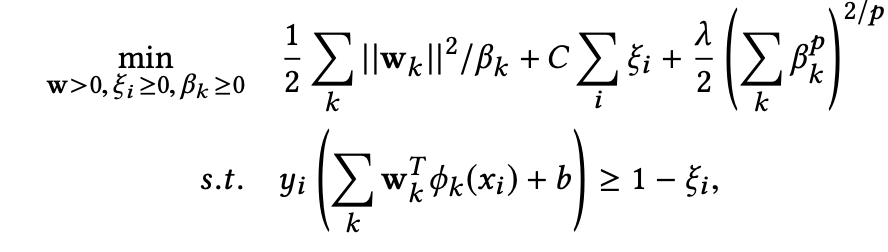
其中, Wk 为参数向量 (即要求的值),ξi 为 slack parameter 来允许错误分类,φk ( xi ) 为定义 kernel 的非线性映射且 φk ( xi )T φk ( xi ) = Mpk ( i, j ),有 Wk = ∑i [αi·φk ( xi )]
使用 p-norm 来寻找合适的 βk,并且在本文中,p = 2,其中 p-norm 为:
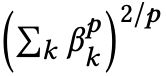
对于一个新的 app x,最后用 ∑k Wk·φk(x)+b 来判断是否为 malware
Scorpion (一个基于 Metagraph2vec 的恶意软件检测系统)
本文与之前一篇 HinDroid 为同一个作者,分别为 kdd2017 和 kdd2018 的论文,都使用了异构信息图 HIN 进行恶意软件检测,存在的不同是,上一篇检测的为安卓恶意软件,本文检测的为 Windows 中的恶意软件,此外,本文对上一篇最大的提升为,提出了 Meta-Graph 和 Metagraph2vec,能够更丰富的表达 HIN 中节点 (在本文中即为两个 PE files)之间的关系,并且使用低维表示 HIN 中的节点并最大程度上的保留用于检测的恶意软件的结构和语义信息,以减少计算时间和存储空间。
方法:
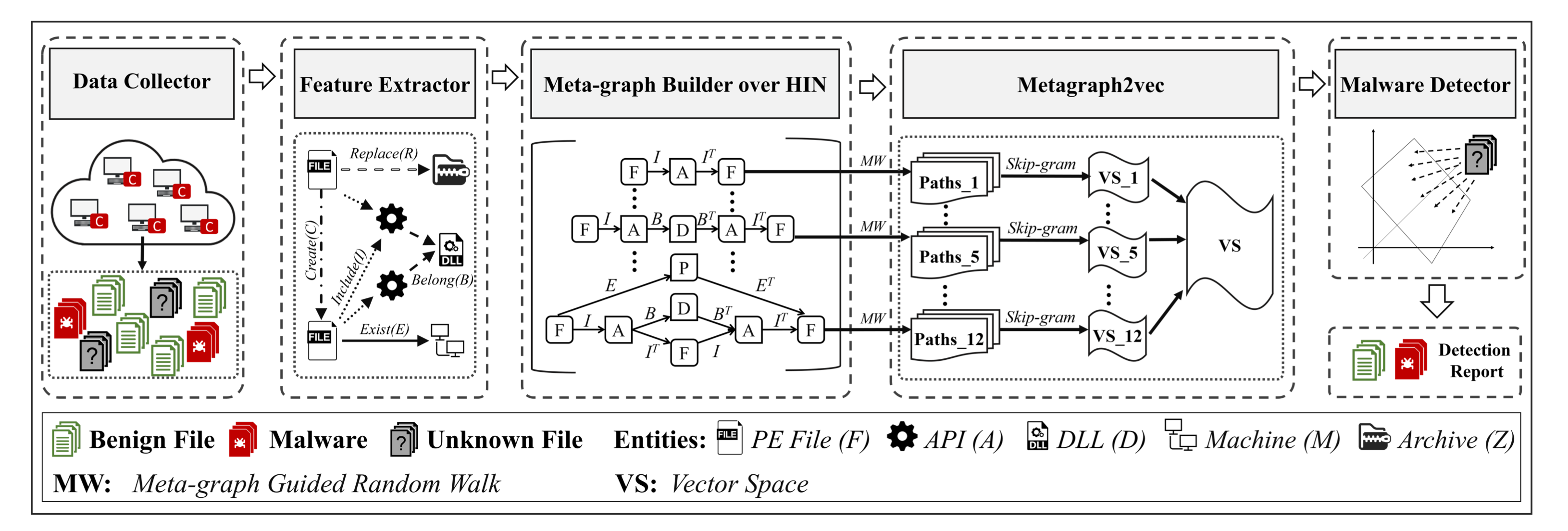
(1)数据收集和特征提取
下载 PE 文件,并从其中的 Import Tables 文件中提取 API calls
所提取的特征为 content-based features:API calls 和 relationships
定义了5种实体:File (F), Archive (Z), Machine (M), API (A), DLL (D)
定义了5种关系:
- R1: file-replace-archive matrix R, rij = 1 当 file i 在 archive j 中被替换,否则为0
- R2: file-exist-machine matrix E, eij = 1 当 file i 在 machine j 中,否则为0
- R3: file-create-file matrix C, cij = 1 当 file i 创建了 file j,否则为0
- R4: file-include-API matrix I, iij = 1 当 file i 中包含了 API j,否则为0
- R5: API-belongto-DLL matrix B, bij = 1 当 API i 属于 DLL j,否则为0
(2)HIN 构建和基于 HIN 的 Meta-graph 的构建
HIN 的网络架构如下图:
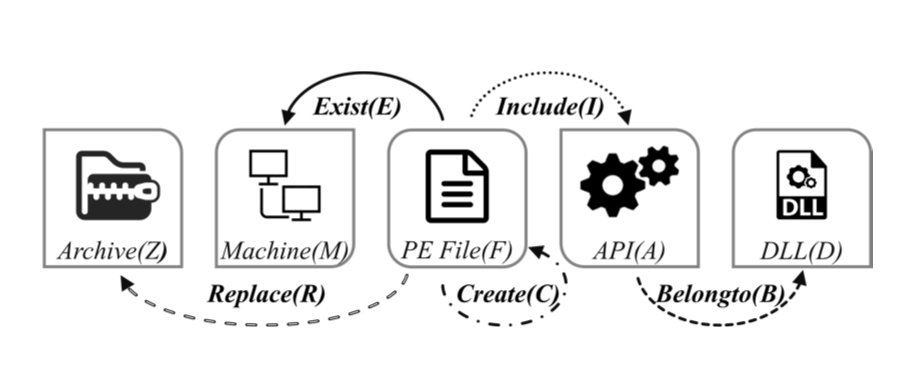
使用元路径表达节点之间的关系 (即 R1 到 R5)后,即又提出了 Meta-Graph 来更丰富的表现节点之间的关系。值得注意的是,Meta-Graph 为一个有向无环图,可以简单点理解为,一个 Meta-Graph 是由一个或多个元路径组成的,只不过他们两端的节点,即 PE file 是一样的,从而构成了 Meta-Graph。
在本文中,定义了12个 Meta-Graph:

可以看到 MID1 到 MID6 作为 Meta-Graph 的特殊情况,其实就是一个元路径,对于 MID7,其意义为两个 PE files 不仅在同一个 machine 上,而且在同一个 archive 中被替换,其余5个可以以此类推。
(3)Metagraph2vec (本文核心)
传统的 HIN 主要集中于分解计算邻接矩阵来生成潜在的维度特征,如上一篇 kdd2017 一样,但这样耗费许多计算成本,并且可能存在统计性能上的缺陷,为了解决这个问题,提出了 Metagraph2vec,字面意思看,即将 Meta-Graph 转化为一个低维的向量。
1. HIN Representation Learning (使用向量空间表示每个 Meta-Graph 的过程)
作为 Metagraph2vec 的第一步,其作用是将 HIN 中的节点转化为一个 d 维向量,其中,d 远小于节点数目,但能尽可能保留节点之间的结构和语义关系。
使用基于 Meta-Graph 的 random walk 和异构的 skip-gram (word2vec 中概念)
- 基于 Meta-Graph 的 random walk:将一个 text corpus 中 word-context 的概念映射到 HIN 中,即将 text corpus 中的句子对应于 sampled path,将单词对应于一个 node,提出两个 random walker u 和 v 来遍历整个 HIN,在第 i 步的转移概率为:
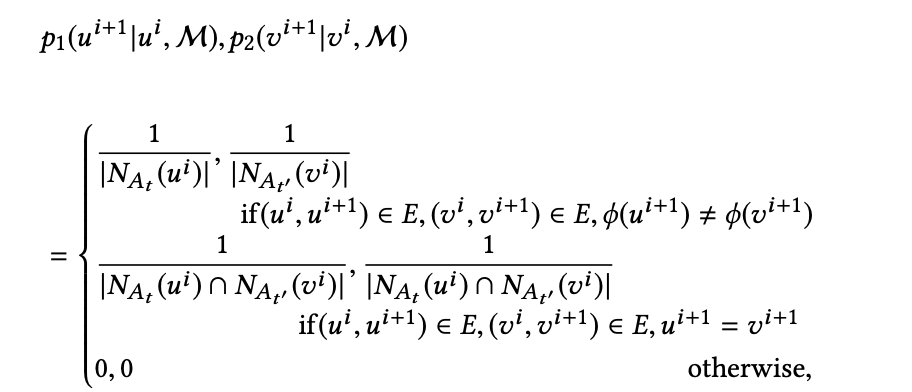
其中,φ 为节点类型映射函数,NAt (ui) 和 NAt' (vi) 分别表示节点 ui 和 vi 邻居的类型 At 和 At'。其中,如果当 u 和 v 是同一个时,基于 Meta-Graph 的 random walk 即为基于元路径的 random walk。使用这样的方法有助于保留节点之间的结构和语义关联,并且有助于下一步:将 HIN 结构转换为 skip-gram。
- skip-gram:将 skip-gram 应用于路径,来最大化一个节点在当前表示下,在窗口范围 w 内观察到领域的概率,目标函数为:
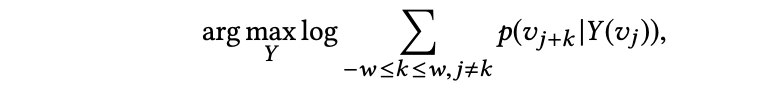
其中,Y (vj) 为 vj 的表示向量,p (v(j+k) | Y (vj)) 由 softmax 函数定义并用 hierarchical softmax 进行优化,并用随机梯度下降训练 skip-gram。
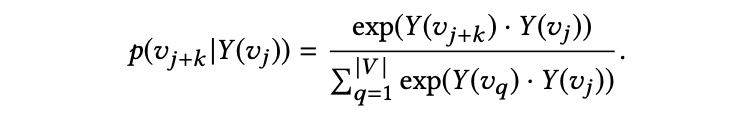
2. Multi-view Fusion (计算权重的过程)
不同的 Meta-Graph 有不同的语义关系,在判断一个软件是否为 malware 时,给基于每个 Meta-Graph 的节点表示赋一个权重。
使用 multi-view fusion 方法,合并基于不同 Meta-Graph 学习的不同的节点表示。
在本文中,有12个 Meta-Graph,从而产生了12中节点表示,用 Yi 表示,权重用 ai 表示,最后合并出的节点表示为 Y' = a1 · Yi
通过测量表示的向量之间的几何距离,在本文中,所有的12个向量空间维度均为 d ,向量空间 Yi 和 Yj 之间的夹角满足:
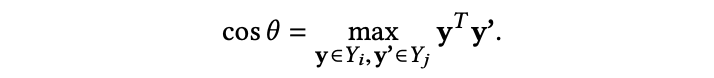
其中,θ 为锐角,每两个向量空间之间,共有 d 个夹角 θ1, θ2, ...,θd。则向量空间 Yi 和 Yj 之间的几何距离为:
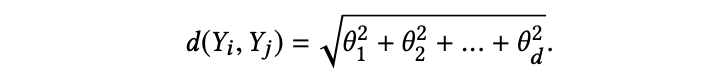
定义权重 ai 为:
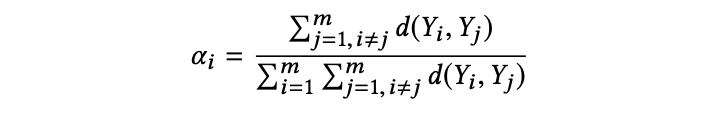
(4)检测
使用 SVM,具体的是使用其中的 LibSVM