冷启动推荐介绍
冷启动又分用户冷启动、物品冷启动、文章冷启动等,本文主要是以在没有用户行为数据的情况下进行物品的推荐;即实现基于区域物品推荐
案例数据
用户ID 物品ID 经度 纬度
1,WP1,116.676381,23.36102
如何进行新注册用户物品推荐,主要以kmeans聚类算法进行实现,kmeans典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大;
聚类可以应用到很多的场景: 冷启动, 用户画像(兴趣画像), 区域热榜
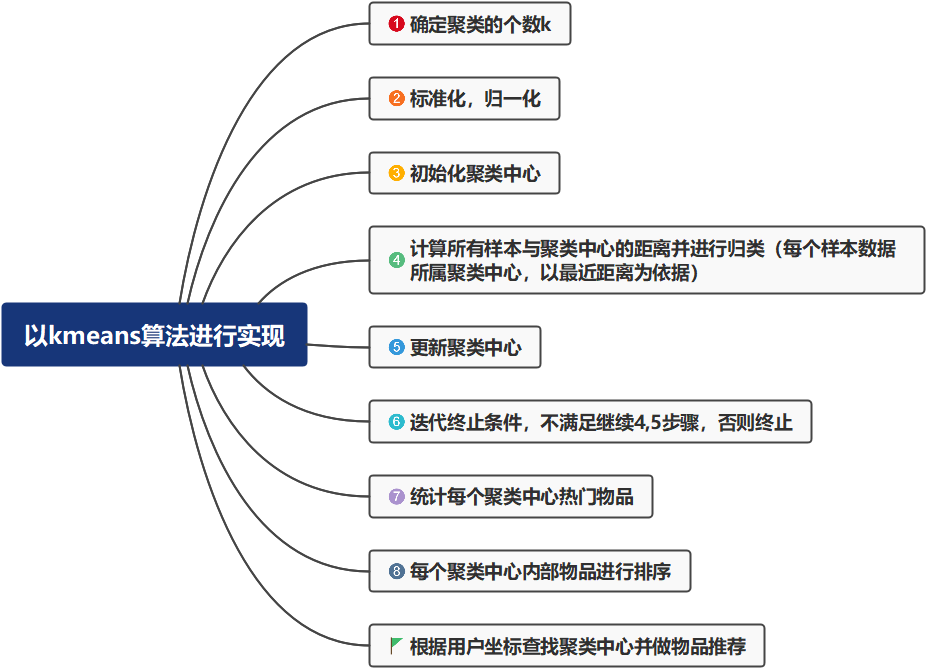
实现方式和对应实现步骤
-
确定聚类的个数K
- 聚类的个数可以跟产品或者运营
- 轮廓系数: 评价聚类个数的好坏
当文本类别未知的时候,可以选择轮廓系数作为聚类性能的评估指标,聚类系数的取值范围是[-1, 1]. 取值越接近1说明聚类的性能越好。相反-1.会更差
-
标准化,归一化
归一化可以消除量纲对最终结果的影响,如:两个人的体重相差10KG, 身高相差0.5cm,在衡量两个人的差别的时候,是不是把身高的差距完全遮盖了
归一化:把数据映射到[0,1] (x-min)/(max-min)
问题:最大值或者最小值很容易受到异常点的异常点的影响,所以效果会出现问题
标准化:z-score (x-均值)/方差
该方法适用于样本的最大值和最小值未知的情况,或者说超出取值范围的离群数据
以上需要注意异常数据 -
初始化聚类中心(如何优化聚类中心需要进一步思考)
1、随机选100个用户作为初始的聚类中心(可以通过mapduce进行实现)
2、kmeans++算法优化随机初始聚类中心,核心初始的聚类中心之间的距离尽量可能的远 -
计算所有样本与聚类中心的距离并进行归类(可以通过mapduce进行实现)
1、每一个样本数据需要与每个聚类中心进行计算(样本经度-聚类中心点经度)平方,(样本维度-聚类中心点维度)平方取最近为距离聚类中心ID(以最近距离为依据) -
更新聚类中心
1、通过mapduce进行计算样品数据所属每个聚类中心ID平均值
2、更新聚类中心数据,聚类中心数量不变量 -
迭代终止条件,不满足继续4,5步骤,否则终止
1、新聚类中心与旧聚类中心相差值是否达到预设阀值
2、迭代次数是否满足设定阀值 -
统计每个聚类中心热门物品
1、通过mapreduce进行计算样本数据以聚类中心id进行汇总 -
每个聚类中心内部物品进行排序
1、通过mapreduce进行每个聚类中心内部物品排序
2、可以把每个聚类中心数据对应物品进行存储到关系型数据等 -
推荐数据应用(冷启动)
1、根据用户经度、维度坐标查找聚类中心最近并做物品的推荐