论文查重
- 先上链接:GitHub链接
再附上我代码的整体流程图
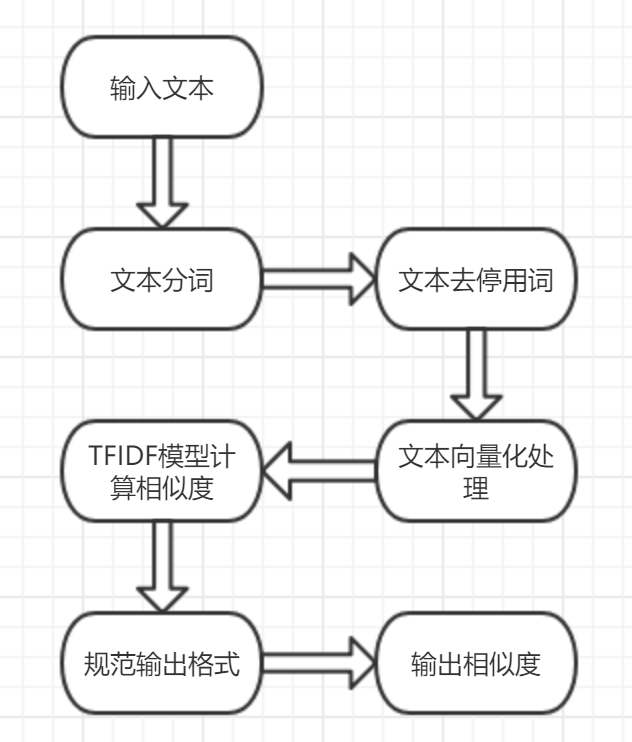
使用语言以及代码原理
使用语言
看到题目后,我第一反应是搜索关于论文查重的算法和原理,通过一天的资料搜索,我了解了分词方法以及各种文本相似度算法,由于需要对中文文本的进行处理,C#这一块的处理比较复杂,所以我打算采用Python的jieba分词以及词袋模型完成这次的编程作业。
在此之前我从未使用过Python,但是这个比java好上手,所以我打算速成学习(可能很艰难,但也只能硬着头皮上QAQ)。
代码原理
- 1.jieba
jieba 是目前最好的 Python 中文分词组件,如果想详细了解的话可以点击:jieba
2.词袋模型
文本中出现频率越高的词就越能代表这个文本,词袋模型在分词的基础上统计每个词项在每篇文档中出现的次数,即词项频率,然后将文档转换为词-权重的集合。
我们用词袋模型来描述一篇文档 。词袋的含义就是说,像是把一篇文档拆分成一个一个的词条,然后将它们扔进一个袋子里。在袋子里的词与词之间是没有关系的。因此词袋模型中,词项在文档中出现的次序被忽略,出现的次数被统计。例如,“我和你” 和“你和我” 具有同样的意义。将词项在每篇文档中出现的次数保存在向量中,这就是这篇文档的文档向量。 - 3.TF-IDF算法
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
词频 (TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
逆向文件频率 (IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
最后产生出高权重的TF-IDF。TF-IDF=TF*IDF
模块介绍
1.文本处理模块
在文本处理模块,我想的比较简单,就是利用jieba库直接对全文进行分词,去停用词,然后用词袋模型把文本转化为向量。
代码如下:
# 分词
def cut_words(file):
with open(file, 'r',encoding="utf-8") as f:
text = f.read()
words = jieba.lcut(text,cut_all = True)
return words
# 去停用词
def drop_Disable_Words(cut_res,stopwords):
res = []
for word in cut_res:
if word in stopwords or word =="
" or word =="u3000":
continue
res.append(word)
return res
def main_gensim(orig_path,copy_path,ans_path):
files = [orig_path,copy_path]
corpus = []
for file in files:
#分词
cut_res = cut_words(file)
#去停用词
res = drop_Disable_Words(cut_res,stopwords)
corpus.append(res)
#建立词袋模型,文本向量化处理
dictionary = corpora.Dictionary(corpus)
txt_vectors = [dictionary.doc2bow(text) for text in corpus]
query = tokenization(orig_path)
query_bow = dictionary.doc2bow(query)
TF_IDF(txt_vectors,query_bow)
2.计算模块
计算是用的TFIDF
#建立TF-IDF模型
def TF_IDF(txt_vectors,query_bow):
tfidf = models.TfidfModel(txt_vectors)
tfidf_vectors = tfidf[txt_vectors]
#使用TF-IDF模型计算相似度
index = similarities.MatrixSimilarity(tfidf_vectors)
sims = index[query_bow]
运行结果

上面是我初稿的运行结果,感觉大体上是偏高的,最初我也想不懂为什么,不过看了大佬的答案,发现差距在于我对文本的处理不够细致,大佬们是对文本先分句再分词,而我直接全文分词,这样下来的准确率自然变低了。
性能分析
这次作业性能分析我用的是pycharm自带的profile工具,这个工具在我们函数调用比较复杂的时候图就会非常缩略,截图不能看到详细内容,只能放大看。

对于这个结果我只能说还行吧,有点久但是可以接受。

下面就是耗时比较大的函数模块以及调用的图:
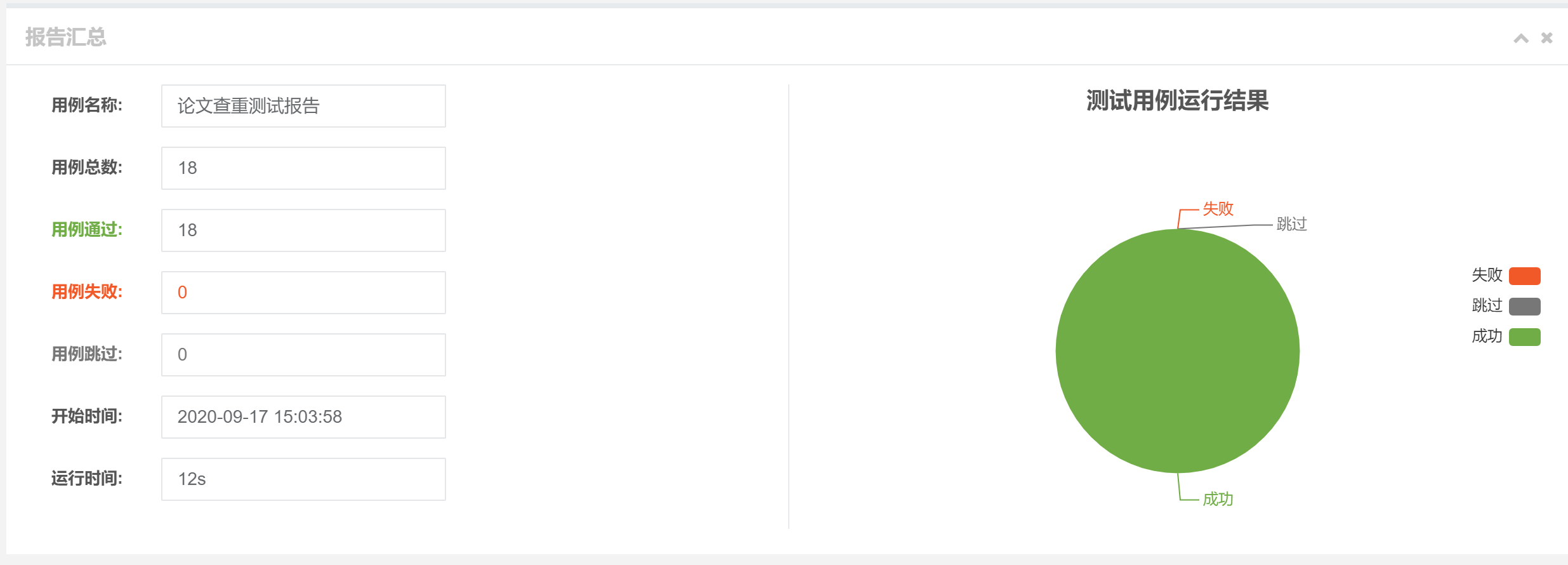
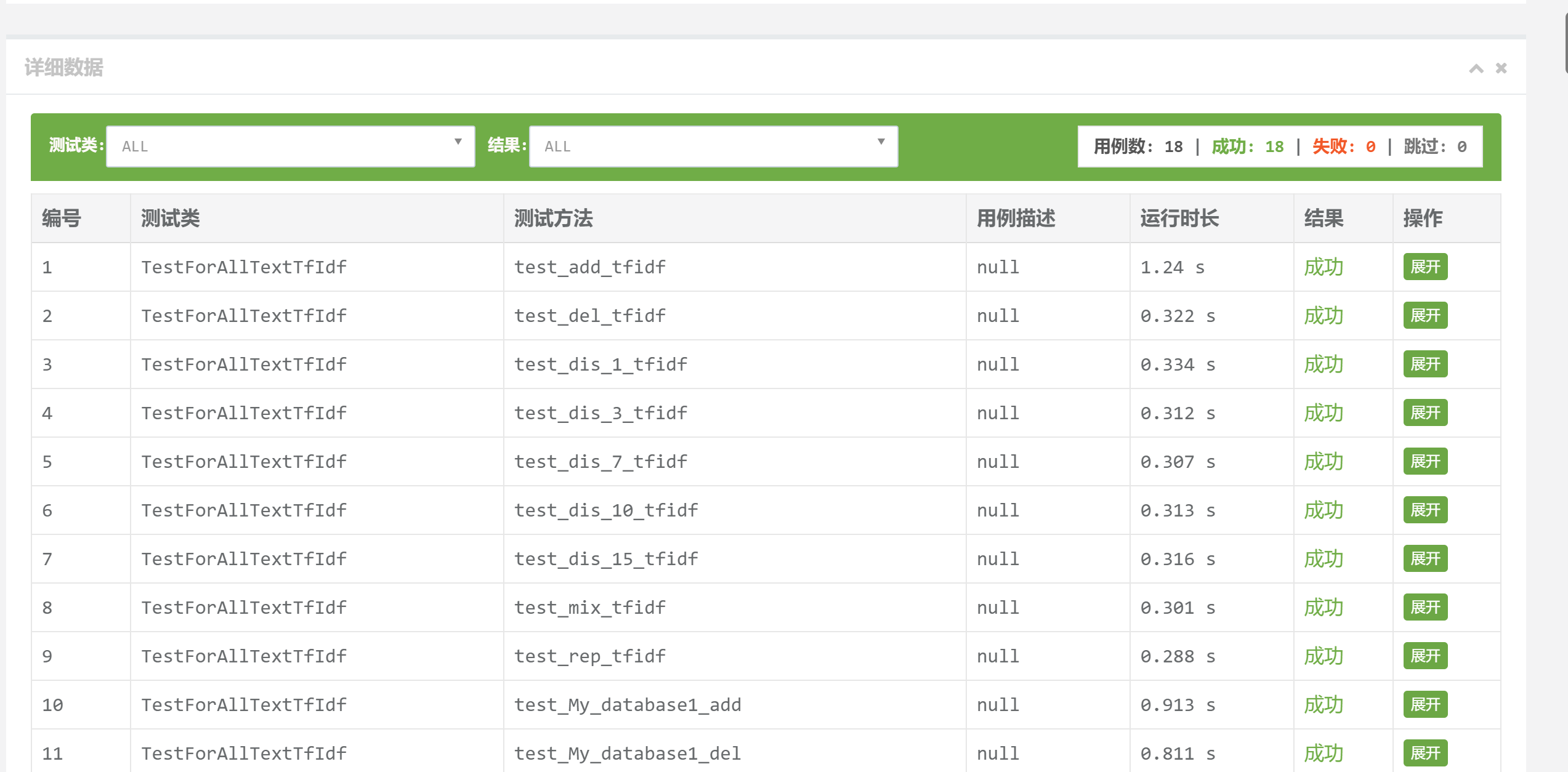
计算模块部分单元测试展示
总结
DDL是第一生产力,想学Python好久了却一直无法开始,这次的作业让我速成python,当然,速成的质量肯定不好,在下一次作业来之前还要恶补一番(下一次作业来的慢一点吧)。
另一方面,我在网上查阅了很多关于查重算法的资料,但是最后发现我准确率偏差的关键不在于算法,而在于对文本的分词处理,对于问题的细节拆分还不够,这是我要继续学习锻炼的地方。
这次作业和以往写算法题目不一样,debug并不只是在某个代码段输出对应值来找到代码漏洞那么简单,我们还用相应的模块载入测试数据来衡量程序的严谨性和效果。
在这次软工实践中也不止代码,这时候才认识到自己以前认识的软工是多么浅显,也后悔为什么以前没有主动多学点知识,以至于现在完成作业都这么费劲。
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| Planning(计划) | 30 | 60 |
| Estimate(估计时间) | 30 | 30 |
| Development(开发) | 540 | 650 |
| Analysis(需求分析(包括学习新技术)) | 600 | 730 |
| Design Spec(生成设计文档) | 30 | 30 |
| Design Review(设计复审) | 30 | 30 |
| Coding Standard(代码规范 ) | 30 | 33 |
| Design(具体设计) | 180 | 165 |
| Coding(具体编码) | 300 | 337 |
| Code Review(代码复审) | 60 | 45 |
| Test(测试(自我测试,修改代码,提交修改)) | 120 | 135 |
| Reporting(报告) | 60 | 155 |
| Test Report(测试报告) | 30 | 30 |
| Size Measurement(计算工作量) | 30 | 30 |
| Postmortem & Process Improvement Plan(事后总结, 并提出过程改进计划) | 60 | 30 |
| Total(合计) | 2130 | 2490 |