刚接触使用scrapy的时候,如果一开始就想实现特别复杂的配置,显然是不太现实的,用一些小的例子可以帮助自己理解各个模块。
今天的目标:爬取http://www.luoxia.com/shendiao/ 网站金庸小说神雕侠侣目录及各章节链接,并且保存到mongoDB数据库
分析:使用scrapy不做任何处理,实际上就可以得到原网页,但是我需要得到的目录名字和名录的url地址,所以需要对response进行解析(在spiders模块完成),
然后我需要保存到数据库,需要在itempipeline里面完成。(各模块功能可参见:上一篇文章)
开始编写代码前需要先生成项目爬虫
1、首先通过scrapy startproject shendiaoSpider命令,创建一个项目shendiaoSpider,但是这个时候项目只是一个空壳,还需要生成一个爬虫
2、通过cd shendiaoSpider命令进入目标文件夹,然后通过scrapy genspider shendiao www.luoxia.com/shendiao 生成一个爬虫,爬虫名叫shendiao
正式开始编写代码,我们需要编写的文件是shendiao.py(用来解析response生成我们需要的item),items.py(定义需要的item字段),pipelines.py(用来存储到数据库),settings.py(配置pipeline以及mongoDB的数据库名和表名):
一、编写items.py,定义两个字段,一个title各章节的标题,一个url各章节的url
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ShendiaospiderItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
二、编写shendiao.py,这里主要是做一个信息提取,把title字段和章节url字段提取出来
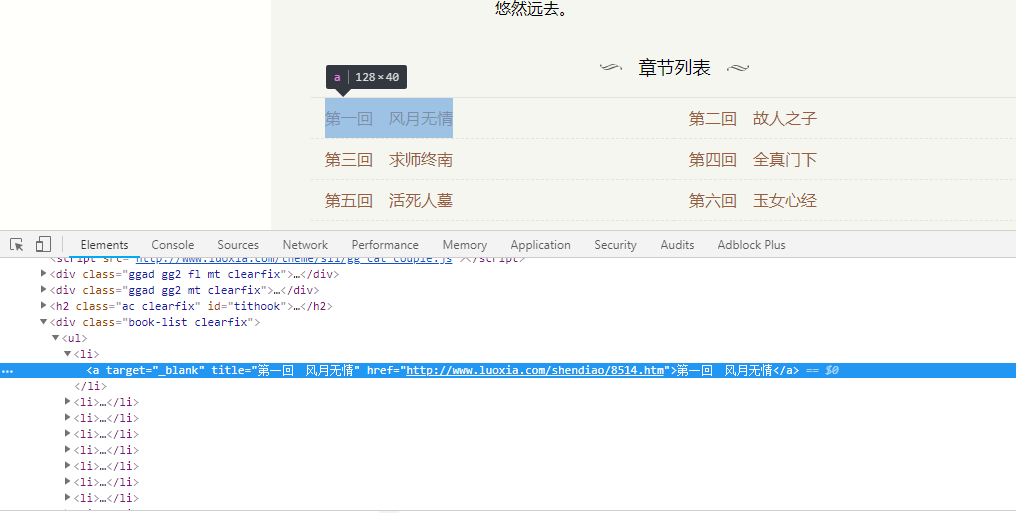
通过对目标网站分析,很容易看出来,所有的章节信息都包含在li标签里的a标签里,我们可以使用css选择器或者xpath进行信息提取,代码如下:
# -*- coding: utf-8 -*- import scrapy from shendiaoSpider.items import ShendiaospiderItem class ShendiaoSpider(scrapy.Spider): name = 'shendiao' allowed_domains = ['www.luoxia.com/shendiao'] start_urls = ['http://www.luoxia.com/shendiao/'] def parse(self, response):
#对于class属性中有空格的,使用css时需要用.进行连接 book_lists = response.css('.book-list.clearfix li') for book_list in book_lists: item = ShendiaospiderItem() item['title'] = book_list.css('a::text').extract_first() item['url'] = book_list.css('a::attr(href)').extract_first() yield item
上面就可以提取出目标字段,保存到item中,如果对于选择器不是很理解,可以看:选择器使用
这个时候在cmd命令行使用scrapy crawl shendiao运行已经可以显示出结果了
三、编写pipelines.py,代码如下:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo #默认的pipeline,只是返回item信息 class ShendiaospiderPipeline(object): def process_item(self, item, spider): return item #使用这个Pipeline将数据item保存到mongoDB class MongoPipeline(object): def __init__(self, mongo_uri, mongo_db): #初始化方式定义两个变量,一个是数据库地址,一个是具体数据库database名称 self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): #定义个类方法,使用这个方法找到settings里面MONGO_URI和MONGO_DB设定的值 return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DB') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) #创建一个到MongoDB位置的连接 self.db = self.client[self.mongo_db] #连接到数据库 def process_item(self, item, spider): name = item.__class__.__name__ self.db[name].insert(dict(item)) #把item信息以字典形式插入到数据库的表中 def close_spider(self, spider): self.client.close() #关闭到数据库的连接
为了方便理解,上面的代码我写了大量的注释,实际写的代码如果这样搞,估计要被人吐死。
四、编写settings.py文件,代码修改部分如下,应该很容易理解:
ITEM_PIPELINES = { 'shendiaoSpider.pipelines.ShendiaospiderPipeline': 300, 'shendiaoSpider.pipelines.MongoPipeline': 400, } MONGO_URI = 'localhost' MONGO_DB = 'shendiao'
这样再次运行这个爬虫,就可以把数据存入到mongoDB数据库了,最后打开可视化工具看一下。

可以看到这个数据库名字叫shendiao,它下面有个表名字ShendiaospiderItem,信息也被存了进去。
好了,关于使用scrapy下载数据并存入到mongoDB的方法就先到这。