古人云:工欲善其事,必先利其器。在网络爬虫中,Scrapy无疑是一把利器,那么,今天我们来谈谈Scrapy的安装。
幸运的是,Scrapy已经支持Python3.4+了,也就是说,我们可以在python3的环境下安装Scrapy。我这里的环境是windows10+python3.5。
有童鞋问,现在都8102年了,怎么还在用python3.5.0,他python3.7.0都用上了。当然不是笔者的电脑渣到带不动python3.7,而是对于一些python库而言,或者一些python的插件,它们还没这么与时俱进,这就导致高版本的python无法大展身手,并且,新版本的用户毕竟是小部分,可能存在一些小瑕疵却没有人来告诉你。低版本的python完全能满足我们的所有需求,要知道,C语言标准已经更新到了C17标准,但对于很多程序而言,它们的核心依然是C90的产物,他们的理念是既然还能用,那又何必花大气力来大换血呢!
跑题了~~
我们先来更新一下pip,在cmd(最好以管理员身份打开)中,输入以下命令来更新pip:
python -m pip install --upgrade pip
接下来就简单了,就如安装其他库一样,直接输入下面语句来进行下载Scrapy:
pip install scrapy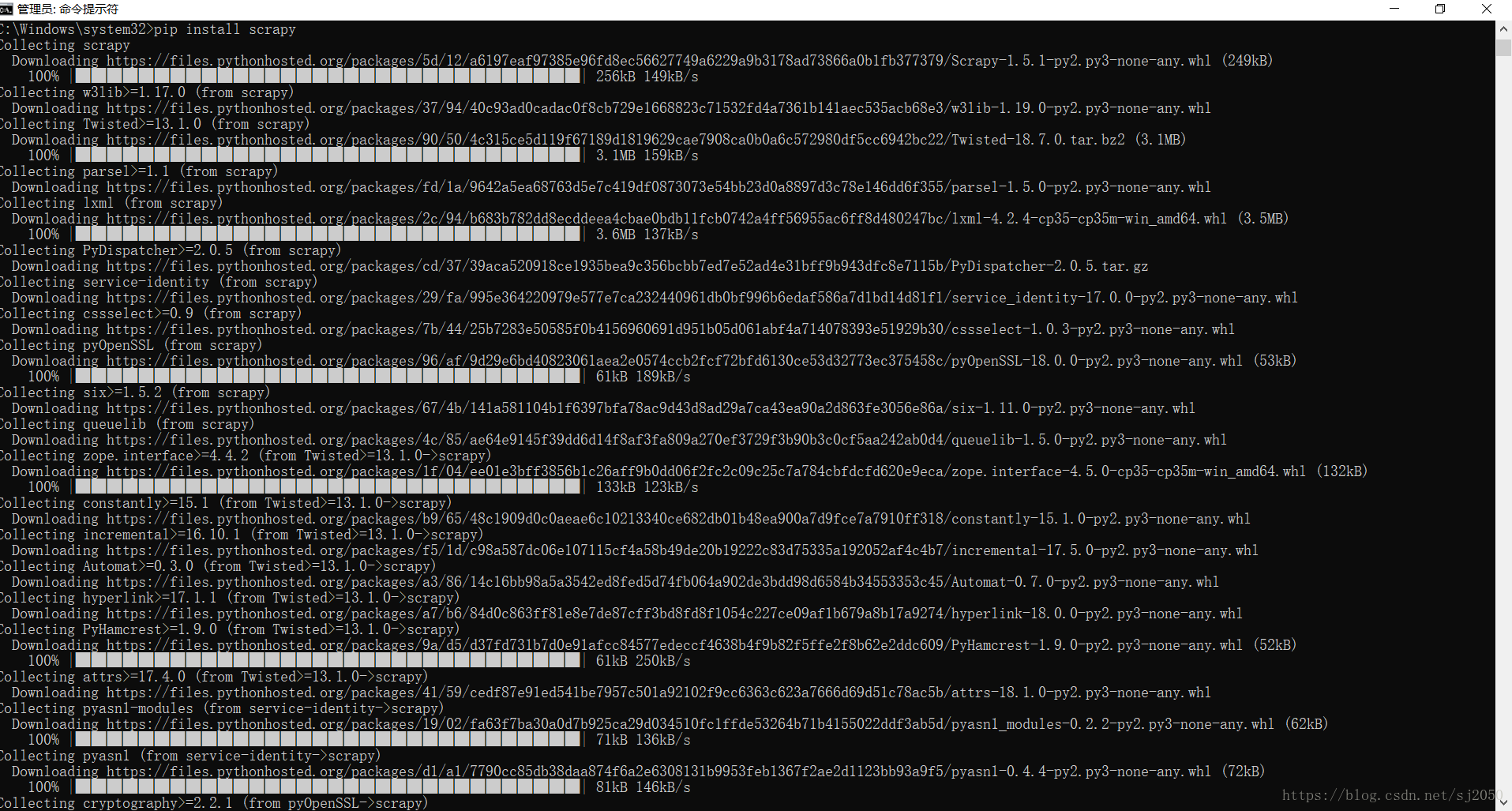
接着,就是想一会小姐姐的时间,不出意外的话就成功安装了,但我们还是要测试一下是否成功安装了Scrapy,我们在python中输入:
import scrapyscrapy.version_info如果,你看到:

那么,恭喜X总喜装Scrapy!!
