从爬虫遇到的问题中我们学会了:
1.有的网站是有反爬虫机制的,外卖网站(我们猜测基本所有盈利性质的网站可能都是)全部都有。
2.我们对于反爬虫机制有了一定的了解。
本次爬虫测试中,我们最后连美团网站都无法打开,显然是美团对于爬虫做出了回应,这个回应会是什么呢?应该并非IP封锁,因为平时大家都要用,如果是IP被封的话应该不仅仅是我们的组员无法连接到美团网站。
我们上网查找了一些可能性。根据http://blog.csdn.net/leoleocmm/article/details/17391105这篇博客中所说,可能是爬虫的User Agent被识别后拒绝了。“统计每天的production.log,抽取User-Agent信息,找出访问量最大的那些User-Agent”,这是原博文中的一句话,我们猜测或许美团采取的就是这种,因为最初我们能够爬下有限的一些网页。可能美团统计的周期比较短所以发现的比较快。
如果再让我们尝试一次,或许我们也不是很有办法做出能够很好应对这个问题的方案,毕竟我们的技术水平有限,而且资本不足。但是,我们可以做出一些可能有较小效果的改变:
比如,我们可以每天爬取一小部分数据,这样的话应该不会产生很大的访问量,但是效率可能非常低。就像当初俄罗斯的黑客们通过几kb/s的速度,甚至可能更慢的速度偷偷盗取了微软(或者某知名公司)刚上市的一款软件重要信息。
工作分配与昨天一样。
| 成员 | 已完成任务 | 新任务 |
| 彭林江 | 研究美团爬虫 | 落实API |
| 牛强 | 研究美团爬虫 | 落实意见反馈功能测试 |
| 高雅智 | 研究美团爬虫 | 测试已完成组件 |
| 郝倩 | 研究遍历美团数据方法 | 提升爬虫程序性能 |
| 王卓 | 研究遍历美团数据方法 | 提升爬虫程序性能 |
| 张明培育 | 实施UI改善 | 实施UI改善 |
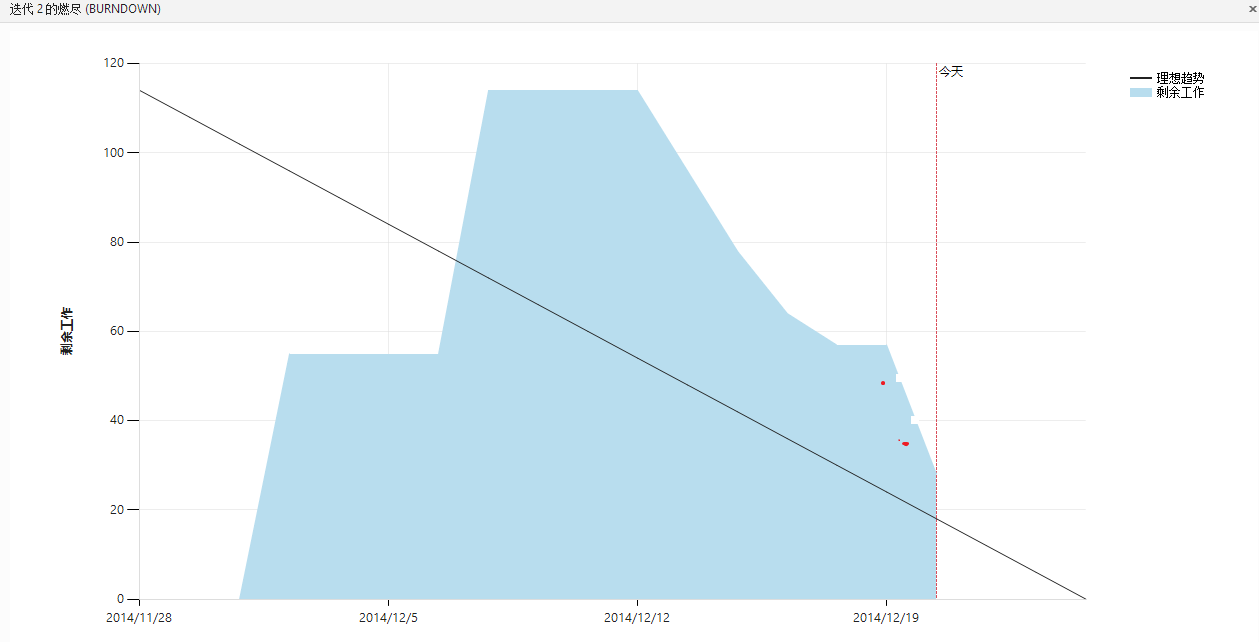
今天的燃尽图如下

上面的这个燃尽图是有些问题的
可对比下面的燃尽图中的两个红点,者分别代表12.19和12.20真正的位置,之前由于TFS出了问题,导致19号的工作量为0,20号的工作量与21号的工作量被一同计算了。