------------------siwuxie095
二叉搜索树的遍历
程序:
BST.h:
#ifndef BST_H #define BST_H
#include "stdlib.h" #include <queue>
//二叉搜索树 template <typename Key, typename Value> class BST {
private:
struct Node { Key key; Value value; Node *left; Node *right;
Node(Key key, Value value) { this->key = key; this->value = value; this->left = this->right = NULL; }
Node(Node *node) { this->key = node->key; this->value = node->value; this->left = node->left; this->right = node->right; } };
Node *root; //根节点 int count;
public:
BST() { root = NULL; count = 0; }
~BST() { destroy(root); }
int size() { return count; }
bool isEmpty() { return count == 0; }
//向整棵二叉树树中插入新元素转换成向一个子树中插入新元素 //直到子树是空的时候,新建一个节点,这个新建的节点就是一 //棵新的子树,只不过它只有一个节点,将它直接返回回去 // //这样,通过递归的方式向二叉搜索树中插入了一个新的元素 void insert(Key key, Value value) { root = insert(root, key, value); }
bool contain(Key key) { return contain(root, key); }
//search()函数常见的返回形式: //(1)Node*,缺点:对外界来说,没有将数据结构Node进行隐藏 //(2)Value,缺点:如果查找不到的话,不知道该返回什么数值 //(3)Value*,优点:作为一个指针可以存一个空元素 Value *search(Key key) { return search(root, key); }
// 前序遍历 void preOrder() { preOrder(root); }
// 中序遍历:会将二叉搜索树的key从小到大进行排序 void inOrder() { inOrder(root); }
// 后序遍历 void postOrder() { postOrder(root); }
// 层序遍历 void levelOrder() { //需要引入队列:先进先出 queue<Node*> q; q.push(root); while (!q.empty()) {
Node *node = q.front(); q.pop();
cout << node->key << endl;
//如果node的左孩子不为空 if (node->left) { q.push(node->left); } //如果node的右孩子不为空 if (node->right) { q.push(node->right); } } }
// 寻找最小的键值 Key minimum() { assert(count != 0); Node *minNode = minimum(root); return minNode->key; }
// 寻找最大的键值 Key maximum() { assert(count != 0); Node *maxNode = maximum(root); return maxNode->key; }
// 从二叉树中删除最小值所在节点 void removeMin() { //根节点不为空,才能做事情 if (root) { root = removeMin(root); } }
// 从二叉树中删除最大值所在节点 void removeMax() { if (root) { root = removeMax(root); } }
// 从二叉树中删除键值为key的节点 void remove(Key key) { root = remove(root, key); }
private:
// 向以node为根的二叉搜索树中,插入节点(key, value) // 返回插入新节点后的二叉搜索树的根 Node *insert(Node *node, Key key, Value value) { //递归到底的情况:如果一个节点都没有, //创建一个新节点作为子树的根 if (node == NULL) { count++; return new Node(key, value); }
//如果新插入节点的key等于当前节点的key,做更新操作即可 if (key == node->key) { node->value = value; } else if (key < node->key) { node->left = insert(node->left, key, value); } else { // key > node->key node->right = insert(node->right, key, value); }
return node; }
// 查看以node为根的二叉搜索树中是否包含键值为key的节点 bool contain(Node *node, Key key) { //如果当前访问的节点已经为空, //即不包含,直接返回false即可 if (node == NULL) { return false; }
if (key == node->key) { return true; } else if (key < node->key) { return contain(node->left, key); } else { // key > node->key return contain(node->right, key); } }
// 在以node为根的二叉搜索树中查找key所对应的value Value *search(Node *node, Key key) {
if (node == NULL) { return NULL; }
if (key == node->key) { return &(node->value); } else if (key < node->key) { return search(node->left, key); } else { // key > node->key return search(node->right, key); } }
// 对以node为根的二叉搜索树进行前序遍历 void preOrder(Node *node) {
if (node != NULL) { cout << node->key << endl; preOrder(node->left); preOrder(node->right); } }
// 对以node为根的二叉搜索树进行中序遍历 void inOrder(Node *node) {
if (node != NULL) { inOrder(node->left); cout << node->key << endl; inOrder(node->right); } }
// 对以node为根的二叉搜索树进行后序遍历 void postOrder(Node *node) {
if (node != NULL) { postOrder(node->left); postOrder(node->right); cout << node->key << endl; } }
void destroy(Node *node) { //使用后序操作的方式来释放整棵树 if (node != NULL) { destroy(node->left); destroy(node->right);
delete node; count--; } }
// 在以node为根的二叉搜索树中,返回最小键值的节点 Node *minimum(Node *node) { if (node->left == NULL) { return node; }
return minimum(node->left); }
// 在以node为根的二叉搜索树中,返回最大键值的节点 Node *maximum(Node *node) { if (node->right == NULL) { return node; }
return maximum(node->right); }
// 删除掉以node为根的二叉搜索树中的最小节点 // 返回删除节点后新的二叉搜索树的根 Node *removeMin(Node *node) { //如果当前节点的左孩子为空,则当前节点为最小节点 //显然,最小值所在的节点只可能有右孩子 if (node->left == NULL) { Node *rightNode = node->right; delete node; count--; return rightNode; }
node->left = removeMin(node->left); return node; }
// 删除掉以node为根的二叉搜索树中的最大节点 // 返回删除节点后新的二叉搜索树的根 Node* removeMax(Node* node) { //如果当前节点的右孩子为空,则当前节点为最大节点 //显然,最大值所在的节点只可能有左孩子 if (node->right == NULL) { Node *leftNode = node->left; delete node; count--; return leftNode; }
node->right = removeMax(node->right); return node; }
// 删除掉以node为根的二叉搜索树中键值为key的节点 // 返回删除节点后新的二叉搜索树的根 Node* remove(Node* node, Key key) {
if (node == NULL) { return NULL; }
if (key < node->key) { node->left = remove(node->left, key); return node; } else if (key > node->key) { node->right = remove(node->right, key); return node; } else { // key == node->key //如果node只有右孩子 if (node->left == NULL) { Node *rightNode = node->right; delete node; count--; return rightNode; }
//如果node只有左孩子 if (node->right == NULL) { Node *leftNode = node->left; delete node; count--; return leftNode; }
// node->left != NULL && node->right != NULL //即node的左右孩子都不为空 Node *successor = new Node(minimum(node->right)); count++;
successor->right = removeMin(node->right); successor->left = node->left;
delete node; count--;
return successor; } } };
//前中后序遍历属于深度优先遍历 //而层序遍历则属于广度优先遍历 // //这四种遍历方式相对都非常高效,时间复杂度是O(n) // // // //二叉搜索树中,最复杂的一个操作就是删除节点 // //其实删除一个节点很容易,关键是将这个节点删除之后,如何来处理 //与这个节点相关联的部分,使得整棵树依然保持二叉搜索树的性质 // // //如果要删除的节点只有一个孩子,那么这个问题很简单,和删除最大 //(小)值所在节点的方法一样,最难的是删除左右都有孩子的节点 // //处理这种情况的一个非常经典的算法就是Hibbard Deletion,这个算 //法在 1962 年被一个叫做 Hibbard 的计算机科学家提出,具体如下: // //假如这个被删除的节点是 d,d 既有左孩子,又有右孩子,其实要做 //的事情就是找一个节点来代替 d,这个节点既不应该是 d 的左孩子, //也不应该是 d 的右孩子,Hibbard 提出这个节点应该是 d 的右子树 //中的最小值 // //删除左右都有孩子的节点 d,用 s 来代替,即 s 是 d 的后继 //(d 即 deletion,s 即 successor) // //s=min(d->right) //s->right=delMin(d->right) //s->left=d->left // //删除 d,s 是新的子树的根 // // // //其实代替的节点也可以是 d 的左子树中的最大值,如下: // //删除左右都有孩子的节点 d,用 p 来代替,p 是 d 的前驱 //(d 即 deletion,p 即 predecessor) // //p=max(d-left) //p->left=delMax(d->left) //p->right=d->right // //删除 d,p 是新的子树的根 // // //删除二叉搜索树中的任意一个节点 时间复杂度 O(lgn)
#endif |
main.cpp:
#include "BST.h" #include <iostream> #include <ctime> using namespace std;
int main() {
srand(time(NULL)); BST<int, int> bst = BST<int, int>();
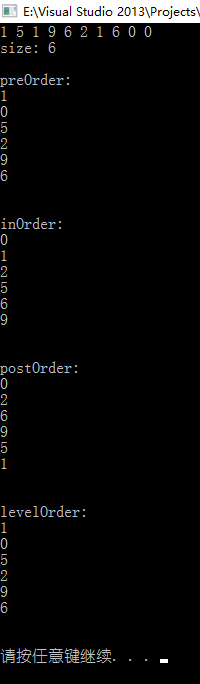
int n = 10; for (int i = 0; i < n; i++) { int key = rand() % n; // 为了后续测试方便,这里value值取和key值一样 int value = key; cout << key << " "; bst.insert(key, value); } cout << endl;
// test size cout << "size: " << bst.size() << endl << endl;
// test preOrder cout << "preOrder: " << endl; bst.preOrder(); cout << endl << endl;
// test inOrder cout << "inOrder: " << endl; bst.inOrder(); cout << endl << endl;
// test postOrder cout << "postOrder: " << endl; bst.postOrder(); cout << endl << endl;
// test levelOrder cout << "levelOrder: " << endl; bst.levelOrder(); cout << endl << endl;
system("pause"); return 0; } |
运行一览:
【made by siwuxie095】