-------------------siwuxie095
在长期的编码中,聪明的程序员们发现:有一些代码经常碰到,
而且需求特别稳定,于是,各大公司在出售自己的 IDE 环境时,
就会把这些模板代码打包,一起销售
慢慢地,这些大公司之间就达成了某种共识,觉得应该把这些
涉及模板的通用代码进一步的统一和规范,于是,大家慢慢形
成了一套 C++ 的标准模板,就是现在所看到的标准模板库

标准模板库
标准模板库,即 Standard Template Lib,简称为 STL

标准模板库所涉及的内容非常多,无法一一列举,这里只介绍
其中具有代表性的、最常用的部分
(1)向量 vector
向量,多么高大上的名字,大家千万不要被它的名字所吓倒
就其本质来说,向量就是对数组的封装

大家可以把它看做是一个数组,只不过相对于此前所学的传统数组,
向量这个数组的功能要强大的多,它可以根据存储的元素个数自动
的变长 或缩短,并且它具有一个很优秀的特点,即 能够在随机读取
数据的时候,在常数时间内完成,这是非常不容易的

也就是说,无论这个向量中是存十个数据,还是存一万个数据,它
都能够很快的从中找出我们想要的数据
向量的初始化 或 定义的方法,常用的有 4 种:
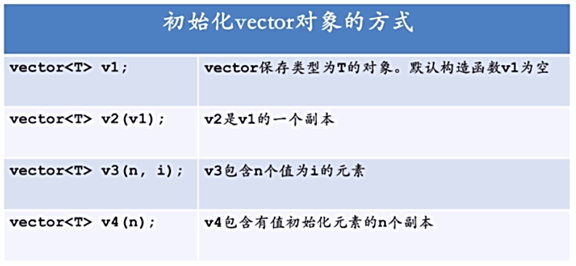
在使用时:

第一行代码使用的是第一种初始化的方法,初始化了一个空的向量 ivec1,
第二行代码是用空的向量 ivec1 又去初始化了另外一个空的向量 ivec2
第三行和第四行代码,同理 … 只不过参数不同罢了
第五行代码是用 10 个 -1 数字初始化 ivec4,而第六行代码则是用 10
个 hi! 字符串来初始化 svec
向量初始化之后必须要有一些配套的使用方法,这样程序员才能真正体会
到标准模板所带来的方便,如下:

在使用时:

就像通过类模板去实例化一个模板类时一样,需要在 vector 后面的
尖括号中传入一个参数,这里是 int,后面就是对象 vec 了
vec 调用 push_back() 时,就会在当前向量的尾部插入元素 10,而
调用 pop_back() 就会将这个 10 抹掉,最后打印 vec.size() 即 总共
数据的个数 为 0
对于数组来说,遍历数组是一种非常常见的操作,而对于向量来说,
遍历时可以像数组一样去遍历它,如下:

除了上面的遍历方法之外,还有一个常用的遍历方法,
即 用迭代器来进行遍历
迭代器,即 iterator,通过它就可以访问标准模板库
对象里的每一个元素
如:通过迭代器去遍历向量中的每一个元素

将向量定义为 vec,通过 vec 的 push_back() 向向量中压入很多的元素,
并依次放在向量的尾部,当然,第一次调用时,会放在第一个元素上 …
向量迭代器的定义方法:
在 vector 后面的尖括号中标记出当前的向量所使用的数据类型,再接
一对冒号 ::,用它来标记出当前的迭代器是属于向量的迭代器,然后是
迭代器 citer,即 citer 的数据类型是 vector<string>::iterator,然后
通过迭代器 citer 来指向当前向量 vec 的第一个元素,最后用 for 循环
就可以用迭代器 citer 去遍历整个向量了
遍历的方法很有意思:
1)首先作为 for 循环来说,第一个条件可以什么都不写
2)第二个条件,即 for 循环的截止条件 是 citer != vec.end(),其中
end() 表示当前向量 vec 的最后一个元素的下一个位置,显然,这是
合理的
3)第三个条件 citer++ 表明:citer 作为迭代器来说,是可以通过 ++
来进行修饰的,它的意义就相当于通过一个指针又指向了向量的下一个
元素,既然可以 ++,自然也可以 --,即 指向向量的上一个元素
4)要打印当前迭代器所指向的向量的值,切记要在迭代器 citer 前
加一个 *,这样,就指的是当前迭代器所指向的元素本身了
(2)链表 list
链表的本质,即 它的数据结构,如下:

链表一般由若干结点组成,如果一个结点都没有,称之为 空链表,
如果有多个结点, 把 第一个结点 称之为 头结点
对于每一个结点来说,又由两部分组成:一部分是数据部分,也叫
做 数据域,另一部分是指针部分,也叫做 指针域,指针部分用来将
各个结点串联起来
有一种链表 叫 双链表,即 不仅可以从头找到尾,还可以从尾找到头
对于链表来说,如果它想插入一个数据,如:在 D 和 E 之间插入数据,
可以让 D 的指针域指向插入进来的数据,再让插入进来的数据的指针
域指向 E
可见:链表插入数据的操作非常简单,而向量如果想在中间插入一个
数据,那么它其后的所有数据就要向后移一个位置,相对于链表来说,
就非常复杂
所以,对于链表来说,它的特点就是数据插入的速度比较快

在使用方法上,链表与向量的使用方法基本相同,它也有 begin()、
end() 等等函数,并且它也可以通过迭代器进行遍历的访问
(3)映射 map
关于映射,先来看一下它的数据结构,如下:

对于映射来说,存储的数据都是成对出现的,把它们标记为 key
和 value,key 称之为 键,而 value 称之为 值
key 和 value 是一对一对出现的,它们往映射这种数据结构中存
放时,也是一对一对去放的
所以在访问时,就可以通过 键 来找到对应的 值
看如下实例:

当通过映射 map 定义了一个对象 m 后,需要向 m 中放
若干对 key-value
而正是通过 pair 来定义 对,即 键值对,再通过 m 调用
insert() 函数将 键值对 放入到 映射 当中去
如果想要访问 value,就可以通过 m 接 key 的索引即可,
如:通过 m[10] 就可以访问到 shanghai,这种访问方式
和数组很相似
再看另一实例:

与上例不同的是,key 不再是数字,而是字符串,通过 m["S"] 即可访问
到 shanghai
程序 1:
main.cpp:
|
#include "stdlib.h" #include <iostream> #include <vector> using namespace std;
int main(void) { //注意向量vector是一个首字母小写的类型 //给一个类的参数这里是int 再写变量名 vector<int> vec;
//从向量的尾部插入数据 vec.push_back(3); vec.push_back(4); vec.push_back(6);
//cout << vec.size() << endl;//当前数据的个数 //vec.pop_back();//将尾部的数据删除(弹出) //cout << vec.size() << endl; //遍历该向量 for (int i = 0; i < vec.size();i++) { cout << vec[i] << endl; }
//拿到向量的第一个元素迭代器相当于是一个指针通过指针指向第一个元素 vector<int>::iterator itor = vec.begin();
//cout << *itor << endl;//打印第一个元素
//通过迭代器遍历向量 //vec.end();是最后一个元素的下一个位置 for (; itor != vec.end();itor++) { cout << *itor << endl; } cout << endl; cout << vec.front() << endl;//取第一个元素 cout << vec.back() << endl;//取最后一个元素 system("pause"); return 0; }
//向量就其本质来说其实就是数组的封装可以看做一个数组 //只是向量这个数组相对于传统数组来说功能要强大的多 //它可以根据存储的元素个数自动变长或缩短 //并且具有一个很优秀的特点就是在能够随机读取数据的时候 //在常数时间内完成(读取能在常数时间内完成) //10个或者10000个数据都能很快找出想要的数据 // //迭代器与类相关的如果要去迭代向量当中的每一个元素 //就要通过向量的迭代器进行迭代 |
程序 2:
main.cpp:
|
#include "stdlib.h" #include <iostream> #include <list> #include <map> #include <string> using namespace std;
int main(void) { list<int> list1;//链表 list1.push_back(4); list1.push_back(7); list1.push_back(9);
//这种遍历是错误的只能通过迭代器进行遍历 /*for (int i = 0; i < list1.size();i++) { cout << list1[i] << endl; }*/
list<int>::iterator itorx = list1.begin(); for (; itorx != list1.end();itorx++) { cout << *itorx << endl; }
cout << endl << endl;
//作为映射来说存储的数据都是成对出现的前面的是key(键) //后面的是value(值)每一个元素都是一对 m是映射的对象 map<int, string> m; pair<int, string> p1(3, "hello");//一对定义若干对key vallue值 pair<int, string> p2(6, "world"); pair<int, string> p3(9, "beijing");
//映射没有 push_back() 方法,通过 insert() 进行插入 m.insert(p1); m.insert(p2); m.insert(p3);
//访问的时候通过索引加key值的方式即通过键来找值 //若开始定义的映射是这样 //map<string,string> m; //pair<string,string> p1("H","hello"); 再插入 //访问时就可以 m["H"] 同样是通过键来找值 cout << m[3] << endl; cout << m[9] << endl; cout << endl << endl;
map<int, string>::iterator itor = m.begin();
for (; itor != m.end();itor++) { cout << itor->first << endl;//第一个key cout << itor->second << endl;//第二个value cout << endl;
//不能通过 cout<<*itor<<endl; 的方式访问因为作为映射来说 //每一个元素都是一对也就是一个pair // //其中包含一个key 一个value 如果直接通过*(星号)来指出这个 //元素的内容的话计算机是不知道该如何输出的怎么办 //必须要将key和value分别输出出来 //方式如上 }
system("pause"); return 0; } |
【made by siwuxie095】