本文《machine learning in action》学习笔记
chapter 2. Classifying with k Nearest Neighbors
the pros and cons of k-Nearest Neighbors:
pro: high accuracy, insensitive to outliers, no assumptions about data
cons: Computationally expensive, requires a lot of memory
works with : Numeric values, normal values
what’s the k meaning?
by giving a data set with label, it can partition into several piece. Given a new data, we compare it with each piece of existing data and look at the top k most similar piece of data. Here we use the distance to evaluate the similarity. Finally, we take a majority vote from the k most similar piece of data, the majority is the class we assign to the new data.
This is the meaning of k.
example of Movies classification by kNN
Background:
the review that giving a kiss or kicks to a movie seems to related different class movies. Usually, the romance movie always get much kiss while action movies get much kicks.
Question: While giving several movies with different kiss and kicks, can we train a model to classify a new movie?
General approach to kNN
1) collect data
2) prepare: algorithm format
3) analyze
4)Train :
5) Test: calculate the error
6) Use
after training the model and testing, if you find the model is good enough, it can be used to classify.
prepare: import data with python
To make the question much easier to understand, here we assign the data point (1,1.1) to class A, and (0,0.1) to class B. There are 4 points, two classes.
def createDataSet():
'''create data set according to the data for specific use'''
group = array([[1.0,1.1],[1.0,1.1],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
Putting the kNN classification algorithm into action
Procedure :
for every point in our dataset:
calculate the distance between inX and the current point
sort the distance in increasing order
take k items with lowest distances to inX
find the majority class among these items
return the majority class as our prediction for the class of the inXpython code
from numpy import *
import operator
def createDataSet():
'''create data set according to the data for specific use'''
group = array([[1.0,1.1],[1.0,1.1],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
def classify0(inX, dataSet, labels, k):
'''put the kNN classification algorithm into action'''
dataSetSize = dataSet.shape[0]
diffMax = tile(inX,(dataSetSize,1)) - dataSet
sqDiffMax = diffMax ** 2
sqDistances = sqDiffMax.sum(axis=1)
distances = sqDistances**0.5
# argsort 返回由大到小的索引值
sortedDistIndicies = distances.argsort()
classCount= {}
for i in range(k):
# 找到最大索引值对应数据的label
voteIlabel = labels[sortedDistIndicies[i]]
# returns a value for the given key
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
if __name__ == '__main__':
group,labels = createDataSet()
classResult = classify0([0, 0], group, labels, 3)
print(classResult)Distance calculation
(1)Calculate the distance using the Euclidian distance between two vectors.
(2) Some function of Numpy that help to understand the code:
1) shape
numpy.ndarray.shape
The shape property is usually used to get the current shape of an array.
example:
>>> x = np.array([1, 2, 3, 4])
>>> x.shape
(4,)
>>> y = np.zeros((2, 3, 4))
>>> y.shape
(2, 3, 4)
>>> y.shape = (3, 8)
>>> y
array([[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.]])2) tile()
numpy.tile(A, reps)
Construct an array by repeating A the number of times given by reps.
exampe:
>>> a = np.array([0, 1, 2])
>>> np.tile(a, 2)
array([0, 1, 2, 0, 1, 2])
>>> np.tile(a, (2, 2))
array([[0, 1, 2, 0, 1, 2],
[0, 1, 2, 0, 1, 2]])
>>> np.tile(a, (2, 1, 2))
array([[[0, 1, 2, 0, 1, 2]],
[[0, 1, 2, 0, 1, 2]]])
>>> b = np.array([[1, 2], [3, 4]])
>>> np.tile(b, 2)
array([[1, 2, 1, 2],
[3, 4, 3, 4]])
>>> np.tile(b, (2, 1))
array([[1, 2],
[3, 4],
[1, 2],
[3, 4]])
>>> c = np.array([1,2,3,4])
>>> np.tile(c,(4,1))
array([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]])voting with lowest k dictionary
for i in range(k):
# 找到最大索引值对应数据的label
voteIlabel = labels[sortedDistIndicies[i]]
# returns a value for the given key
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
# 按照键值的大小排列
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)这里dictionary的get方法是这么理解的:
classCount是一个字典, classCount[voteIlabel] = ?表示给字典中的key赋值。
votellablel 是我们分的类别A,B
get()的语法:get(key, default=None)
这里classCount.get(voteIlabel,0) + 1 就是指获取key为voteIlabel的值,当key不存在时,建立一个key并且赋值为0,如果key存在则返回该key对应的值并加1.
这里要做的事情就是给每一个类投票,for-loop结束之后,可以得到一个字典
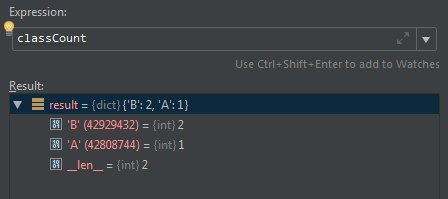
接下来就是要返回票数多的类别,用到了sort函数(我下面也有介绍这个函数)
classCount.items() 就是讲上面求到的字典转为元组
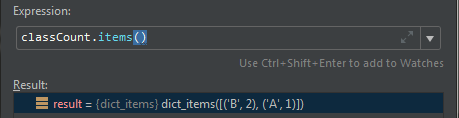
sort()的第二个参数表示要按照元组那个位置上的值排列。这里(‘B’,2)(‘A’,1)
我们想要的是类别A或者B,按照第二个数的大小排,所以key = operator.itemgetter(1),填1而不是0,填0就按照A,B顺序排。
按照高到低排序,最后返回第一个元组的第一个元素sortedClassCount[0][0]就是B.
(1) some function of numpy and python that can help to understand the code:
numpy.argsort(a, axis=-1, kind='quicksort', order=None)
Returns the indices that would sort an array.
Parameters:
a : array_like Array to sort.
axis : int or None, optional
Axis along which to sort. The default is -1 (the last axis). If None, the flattened array is used.
kind : {‘quicksort’, ‘mergesort’, ‘heapsort’}, optional sorting algorithm.
order : str or list of str, optional
Returns:
index_array : ndarray, intexample
One dimensional array:
>>> x = np.array([3, 1, 2])
>>> np.argsort(x)
array([1, 2, 0])Two-dimensional array:
>>> x = np.array([[0, 3], [2, 2]])
>>> x
array([[0, 3],
[2, 2]])>>> np.argsort(x, axis=0) # sorts along first axis (down)
array([[0, 1],
[1, 0]])>>> np.argsort(x, axis=1) # sorts along last axis (across)
array([[0, 1],
[0, 1]])Indices of the sorted elements of a N-dimensional array:
>>> ind = np.unravel_index(np.argsort(x, axis=None), x.shape)
>>> ind
(array([0, 1, 1, 0]), array([0, 0, 1, 1]))
>>> x[ind] # same as np.sort(x, axis=None)
array([0, 2, 2, 3])Sorting with keys:
>>> x = np.array([(1, 0), (0, 1)], dtype=[('x', '<i4'), ('y', '<i4')])
>>> x
array([(1, 0), (0, 1)],
dtype=[('x', '<i4'), ('y', '<i4')])
>>> np.argsort(x, order=('x','y'))
array([1, 0])
>>> np.argsort(x, order=('y','x'))
array([0, 1])2)
Python 3 - dictionary get() Method
Description
The method get() returns a value for the given key. If key is not available then returns default value None.
Example
#!/usr/bin/python3
dict = {'Name': 'Zara', 'Age': 27}
print ("Value : %s" % dict.get('Age'))
print ("Value : %s" % dict.get('Sex', "NA"))Value : 27
Value : NA3)
Axis is difficult to understand, you can refer this link:
Sort dictionary
sortedClassCount = sorted(classCount.iteritems(), key = operater.itemgetter(1), reverse = Ture)
return sortedClassCount[0][0]1)
python sorted
The sorted() method sorts the elements of a given iterable in a specific order - Ascending or Descending.
The syntax of sorted() method is: sorted(iterable[, key][, reverse])
Sort the list using sorted() having a key function
# take second element for sort
def takeSecond(elem):
return elem[1]
# random list
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
# sort list with key
sortedList = sorted(random, key=takeSecond)
# print list
print('Sorted list:', sortedList)Sorted list: [(4, 1), (2, 2), (1, 3), (3, 4)]operator.itemgetter
Return a callable object that fetches item from its operand using the operand’s getitem() method.
examle:
>>> itemgetter(1)('ABCDEFG')
'B'
>>> itemgetter(1,3,5)('ABCDEFG')
('B', 'D', 'F')
>>> itemgetter(slice(2,None))('ABCDEFG')
'CDEFG'Example of using itemgetter() to retrieve specific fields from a tuple record:
>>> inventory = [('apple', 3), ('banana', 2), ('pear', 5), ('orange', 1)]
>>> getcount = itemgetter(1)
>>> list(map(getcount, inventory))
[3, 2, 5, 1]
>>> sorted(inventory, key=getcount)
[('orange', 1), ('banana', 2), ('apple', 3), ('pear', 5)]