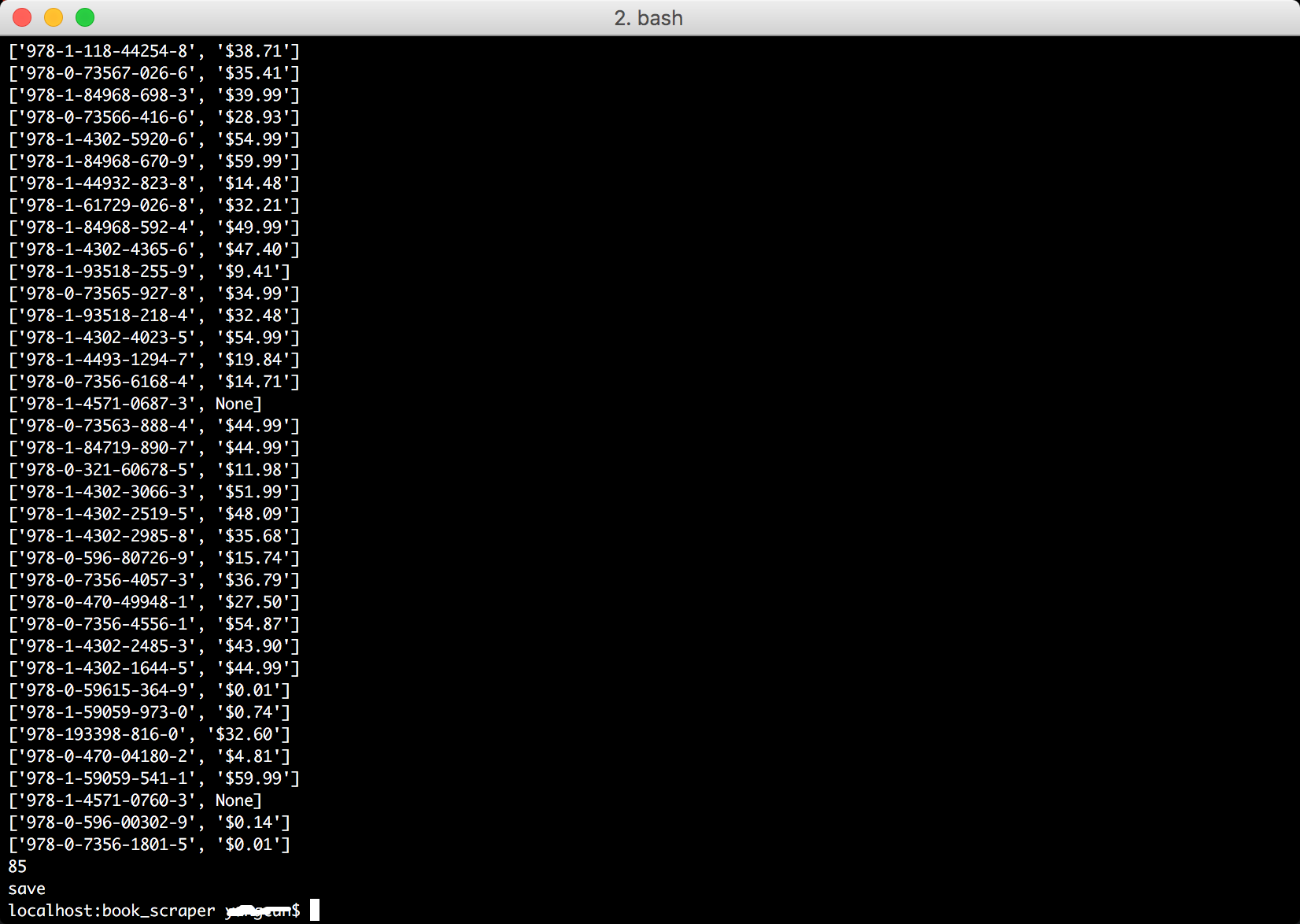
def get_price_amazon(isbn): base_url = "https://www.amazon.com/s/ref=nb_sb_noss?url=search-alias%3Daps&field-keywords=" url = base_url + str(isbn) page = urlopen(url) soup = BeautifulSoup(page, 'lxml') page.close() price_regexp = re.compile("$[0-9]+(.[0-9]{2})?") price = soup.find(text=price_regexp) return [isbn, price]
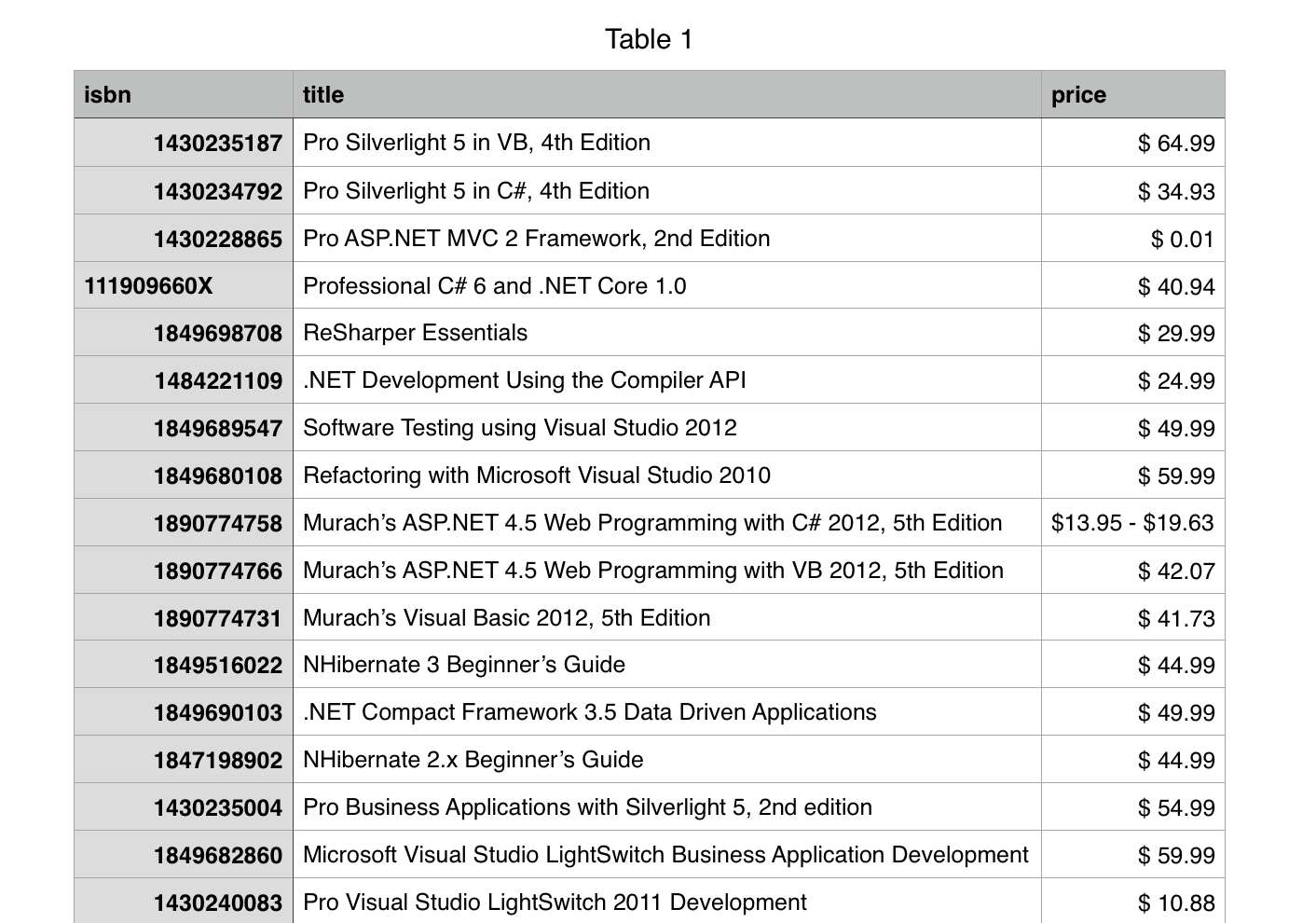
book_info_data = pd.read_csv('books.csv') price_data = pd.read_csv('prices.csv') result = pd.merge(book_info_data, price_data, on='isbn') result.to_csv('result.csv', index=False, header=True, columns=['isbn', 'title', 'price'])
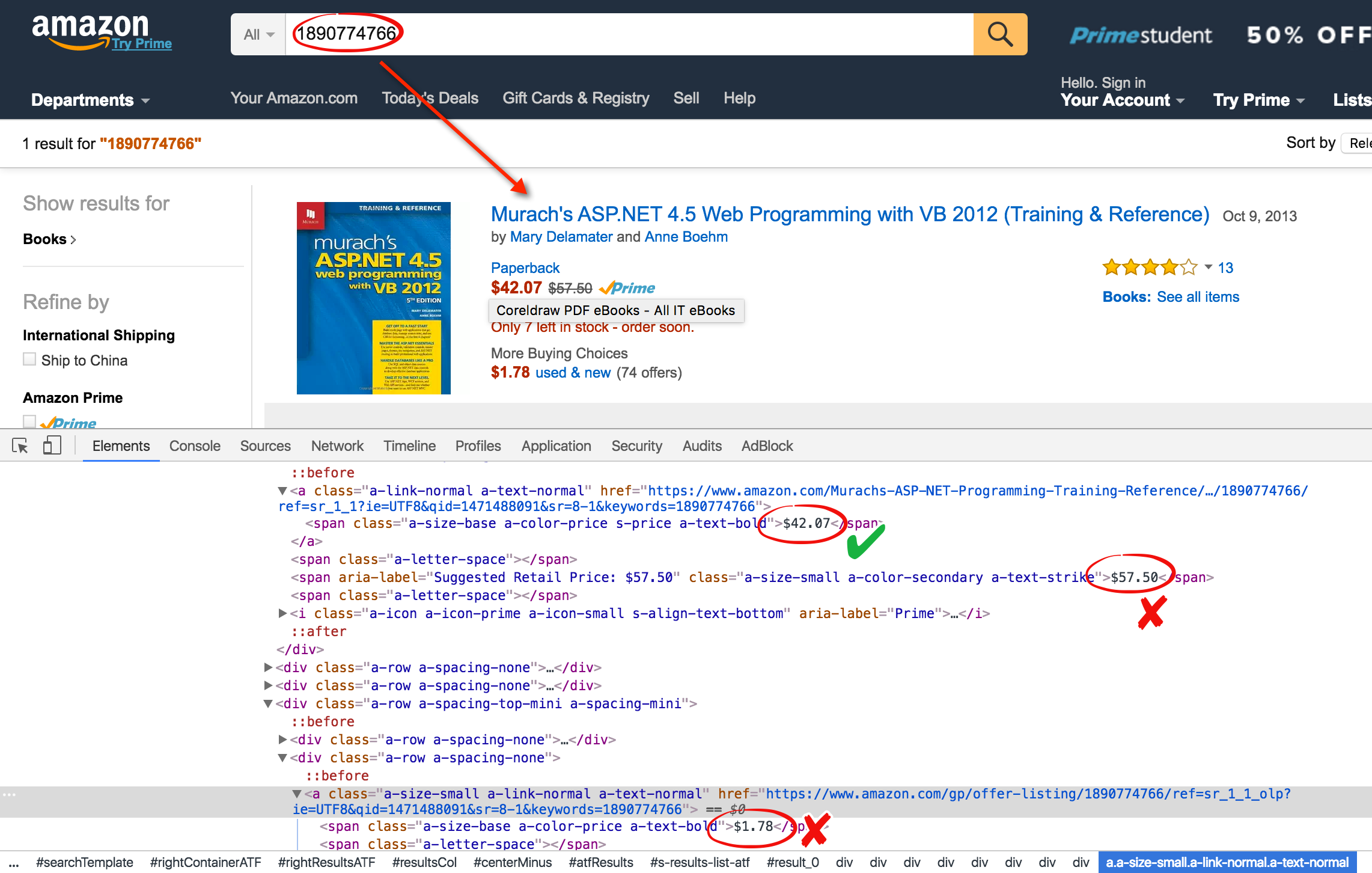
大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 python操作Excel,excel读写 通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码) 接下来将通过ISBN码去amazon.com获取每本书对应的价格。 一、了解需要和分析网站 通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。 结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码) 接下来将通过ISBN码去amazon.com获取每本书对应的价格。 一、了解需要和分析网站 通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。 结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码) 接下来将通过ISBN码去amazon.com获取每本书对应的价格。 一、了解需要和分析网站 通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。 结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码) 接下来将通过ISBN码去amazon.com获取每本书对应的价格。 一、了解需要和分析网站 通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。 结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码) 接下来将通过ISBN码去amazon.com获取每本书对应的价格。 一、了解需要和分析网站 通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。 结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码) 接下来将通过ISBN码去amazon.com获取每本书对应的价格。 一、了解需要和分析网站 通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。 结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。