HashMap和HashSet是Java Collection FrameWork中两个重要成员,并且底层Hash存储机制完全相同,可以说HashSet就是借助HashMap实现的。
通过HashMap源码分析Hash存储机制。
首先简单了解一下HashMap的特点:
采用数组与链表结合的数据结构;用过数组和链表的朋友都对两者的特点很熟悉(或查看http://www.cnblogs.com/siriu-s/p/5234415.html),但是为了将两者特点结合,所以某些方面不会比单独使用一个更高效。
系统采用 Hash 算法决定集合元素的存储位置,这样可以保证能快速存、取集合元素;对于 HashMap 而言,系统 key-value 当成一个整体进行处理,系统总是根据 Hash 算法来计算 key-value 的存储位置,这样可以保证能快速存、取 Map 的 key-value 对。
接下来看一下源码:
成员变量:
- static final int DEFAULT_INITIAL_CAPACITY = 16;// 默认初始容量为16,必须为2的幂
- static final int MAXIMUM_CAPACITY = 1 << 30;// 最大容量为2的30次方
- static final float DEFAULT_LOAD_FACTOR = 0.75f;// 默认加载因子0.75
- transient Entry<K,V>[] table;// Entry数组,哈希表,长度必须为2的幂
- transient int size;// 已存元素的个数
- int threshold;// 下次扩容的临界值,size>=threshold就会扩容
- final float loadFactor;// 加载因子
三种构造函数(实际上有四种,这里讨论其中三个)
1、不传入参数负载因子和容量,采用默认值即bucket=16,load_factory=0.75实例化HashMap()

2、传入容量初始值,负载因子采用默认值,按此值实例化HashMap()

3、容量和负载因子都穿入初始值,须对参数值进行检测,容量值不得小于0,但也不能大于容量最大值,若大于最大值则按最大容量创建(2的30次方);负载因子须大于0
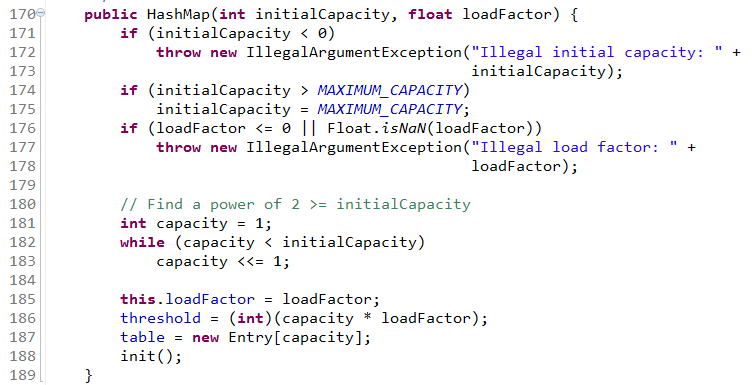
重点看一下第三个构造方法,以为都要调用它。我们可以看到看第181-183行代码,这里做了一个移位运算,保证了初始容量一定为2的幂,假如你传的是5,那么最终的初始容量为8。为什么HashMap容量一定要为2的幂呢?HashMap中的数据结构是数组+单链表的组合,我们希望的是元素存放的更均匀,最理想的效果是,Entry数组中每个位置都只有一个元素,这样,查询的时候效率最高,不需要遍历单链表,也不需要通过equals去比较Key,而且空间利用率最大。那如何计算才会分布最均匀呢?我们首先想到的就是%运算,哈希值%容量=bucketIndex,我们阅读一下这段源码:

很明显在这里用到了位运算,可是为什么不用%取余呢?当容量一定是2^n时,h & (length - 1) == h % length,它俩是等价不等效的,位运算首先要把数字转换成二进制数,然后与length(桶数量)进行与运算,但是这样做以人的思维来说是比较麻烦的,但是为什么要这样做呢?因为机器就只认识二进制码。(这里的 h 是通过key的hashcode最终计算出的哈希值,length是目前容量。)
一般加载因子设置为0,75,这可以说是一种折中的策略,如果加载因子过高加少了空间开销但是又会影响查询速度,过低又会导致扩容频繁,因为扩容的标志是桶占用个数=加载因子*容量。
那么扩容又是怎样的呢?
在需要扩容时,进行refresh,新容量=原容量*2,然后根据key重新计算hashcode再重新散列,将原有数据重新放进新的hashmap中,完成扩容。
如何获取hashmap中存储的元素?看get()方法

在查询元素时将key传入作为参数,首先对key做判空处理,为空则调用getForNullKey()方法。