文献引用
Amirian J, Hayet J B, Pettre J. Social Ways: Learning Multi-Modal Distributions of Pedestrian Trajectories with GANs[J]. 2019.
文章是继Social LSTM、Social GAN模型后的进一步提升,在理想的监控俯瞰数据库ETH、UCY上进行数据的预测。重点贡献有:
- 引入了注意力机制使模型自主分配对交互信息的关注。
- 舍弃了L2代价函数,引入基于互信息的Information Loss,增强了模型对多合理轨迹的预测能力。
- 提供了一种能够验证各模型的多轨迹预测能力的小型合成场景和轨迹生成效果的判断指标。
模型框架
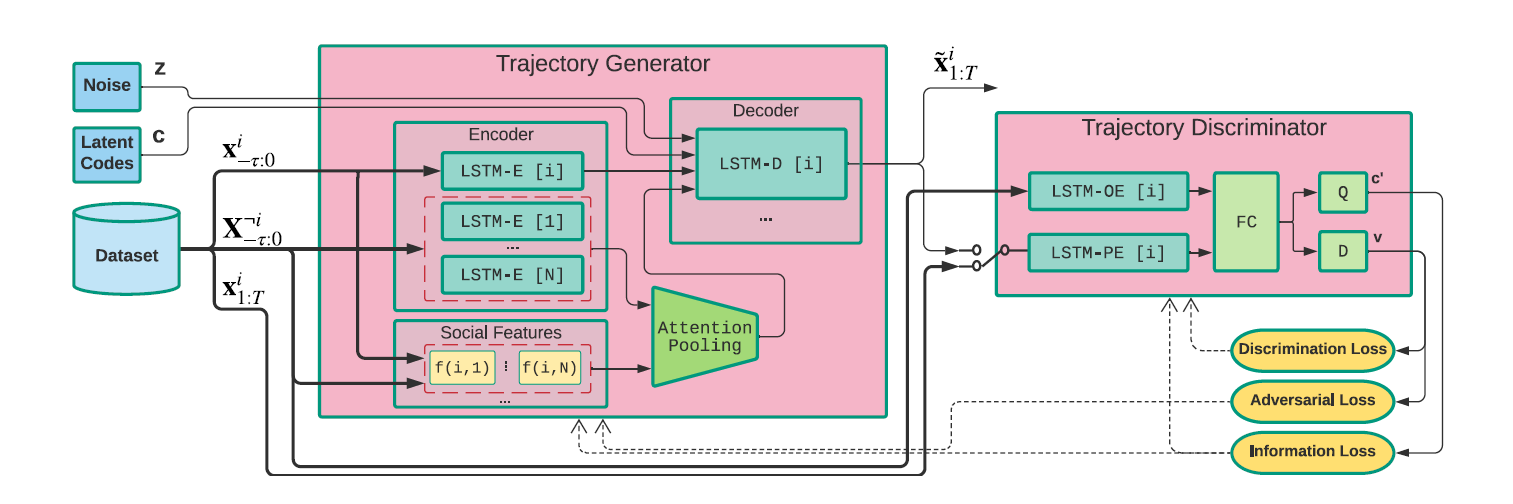
如上图所示,文章的基本框架是GAN网络,在不考虑batch批处理的情况下,模型逐一为每个行人预测轨迹。
- 在Generator中,对于待预测行人(i),首先会将所有行人的已知轨迹进行编码,而后基于(i)和其他行人之间的地理和运动信息,引入注意力机制使得模型对其他行人的交互信息自主适应。行人(i)的轨迹编码、注意力池化后的交互信息、噪音、latent code(新引入内容,之后会讲到)四种输入作为Decoder的输入,解码出行人(i)的预测轨迹。
- 在Discriminator中,会对生成轨迹/真实轨迹进行判别,判别的结果作为Generator/Discriminator的代价函数。
- 模型框架具体来说是InfoGAN,InfoGAN网络解决的是在无监督的情况下通过修改latent code倾向从而控制GAN的生成分布,与GAN相比其强调latent code对生成的控制性,与cGAN相比其强调能够在有潜在类别的数据中无监督(无数据标签)学习。因而GAN网络中新引入了Latent Code和Information Loss两个结构。
HighLight 1 - 注意力机制
注意力机制采用Key-Value-Query型定义,从认知角度引入合适的手工指标,基于这些指标使模型能够对周围轨迹产生不同的注意力。
- Key = Value = (H_t)(除目标行人(i)外,其他的行人的轨迹编码信息)。
- Query:(f^{ij})由三种运动地理运动信息合成
- (i)和(j)之间的欧式距离
- (i)和(j)之间运动方向的夹角。
- 以当前运动姿态,(i)和(j)未来将会出现的最短距离。
HighLight 2 - InfoGAN
原文[推荐阅读] Chen X, Duan Y, Houthooft R, et al. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets[J]. 2016.
InfoGAN模型解读:https://www.jiqizhixin.com/articles/2018-10-29-21,内容过简练,建议阅读原文。
模型结构
InfoGAN的模型结构相较于GAN的改进是较小的,在上文的模型中,首先是在输入中新增了Latent Code,而后弃用了SGAN中的L2损失函数,在Discriminator在加入了一个子网络(Q)产生Information Loss。
原理简介
-
Motivation: InfoGAN训练后的理想状态是通过调整Latent Code(潜码)——(c)输入控制生成的分布。然而GAN自由灵活性很高,网络很容易直接忽视Latent Code的存在,因此必须调整代价函数使网络重视Latent Code的存在。InfoGAN提出使用互信息(I)作为优化目标,(I)越大则潜码和生成的关系越大:
[I(X;Y) = H(X) - H(X|Y) ]对于互信息(I(X;Y)),其本意是指在已知(Y)的情况下,(X)的不确定性下降程度,当两者结合得非常紧密时,互信息将变得非常大。因此我们希望(I(c;G(z,c)))能够尽可能大,这样潜码就能控制Generator的生成了。
-
Restriction:
-
(H(c))是信息熵的计算,文章中在此假定(H(c))是一个固定的值,因此优化目标转化为令(H(c|x))最大化。
知识补充:
- 信息熵的计算公式:(H(X) = E[I(x_i)] = - sum_{i=1}^NP(x_i)logP(x_i))
- 具体计算:(H(c|x)=-E_{x sim G(z,c)}[E_{c'sim P(c|x)}[logP(c'|x)]])
-
需要后验概率(P(c|x)),要获取其非常困难,因此使用(Q(c|x))(辅助分布)来近似求解后验的概率(P(c|x)),并且作者通过数学推导了在互信息的计算中(P(c|x))和(Q(c|x))间的关系:

[!] 这里请务必留意将“=“变为”>=“时移除的部分是P和Q的KL散度,KL散度是用于衡量P和Q之间分布差异性的指标。这将为后文解释优化的合理性提供重要支撑。
-
-
我们继续与(P(c|x))的斗争,之前我们求出了(I(c;G(z,c)))的下界:
[E_{xsim G(z,c)}[E_{c'sim P(c|x)}[logQ(c'|x)]] + H(c) ]下界中相较原式(E[.])中的(P(c|x))被替代了,但是求期望的随机变量(c')的分布中依然涉及(P(c'|x)),要进一步替换,作者用了如下公式:
[E_{xsim X,ysim Y | x}[f(x,y)] = E_{xsim X, ysim Y|x,x'sim X|y}[f(x',y)] ]至此,(P(c|x))被彻底干掉了,从而变得可以被实现:
[E_{xsim G(z,c)}[E_{c'sim P(c|x)}[logQ(c'|x)]] + H(c) = E_{c sim P(c),x sim G(z,c)}[logQ(c|x)] + H(c) ]
-
Target:作者将最大化(I(c;G(z,c)))的目标转移为最大化(I)的下界
[L_1(G,Q)=E_{c sim P(c),x sim G(z,c)}[logQ(c|x)] + H(c) ][敲黑板]!!!
为什么最大化互信息可以变为最大化互信息的下界呢?这就是InfoGAN最精华、最巧妙的地方!
我们从训练调整参数的角度来看这个问题,InfoGAN网络的参数可分为Generator、Discriminator和Q三个部分,训练时(Generator)(Discriminator+Q)迭代训练,由于Discriminator与互信息无关,我们先不考虑,因此G和Q实际在两个迭代中完成:
- 训练Q时:G的参数固定,因此互信息(I)是不变的,这时候训练Q就是为了减小互信息下界和互信息的差异。而我们前文重点说道,差异恰好就是P和Q的KL散度,即分布差异,实现了调整Q的参数拟合P的过程。
- 训练G时:在Q不断拟合P的过程中,互信息(I)的下界也越来越接近互信息(I)(直至等于)。在这种条件下,训练G增大互信息的下界等同于增大互信息。
一句话来说,G和Q在计算互信息时有着不同的目标(提升互信息增强拟合),但是却都通过最大化L1(G,Q)损失函数实现了。(在原文中,作者也提到了这种方式类似于"Wake-Sleep Algorithm" - 同样的训练目标,最终两个权重都正确更新了)
-
Implement:
最终加入了GAN原有的损失函数后,总优化目标变化为:
[min_{G,Q}max_DV_1(D,G)=V(D,G) - mu L_1(G,Q) ]Q是含有待定参数的分布器。
- 在InfoGAN实现时,Q实际输出的是假设的正则分布的参数,并随着Discriminator进行训练,负似然对数作为损失函数。
- 在Social Ways模型在实现时,Q实际上是一个latent code reconstructor(潜码恢复器)。Information Loss实指Q所恢复的潜码(hat c)和真实潜码(c)之间的MSE。
HighLight 3 - 多轨迹预测的生成场景
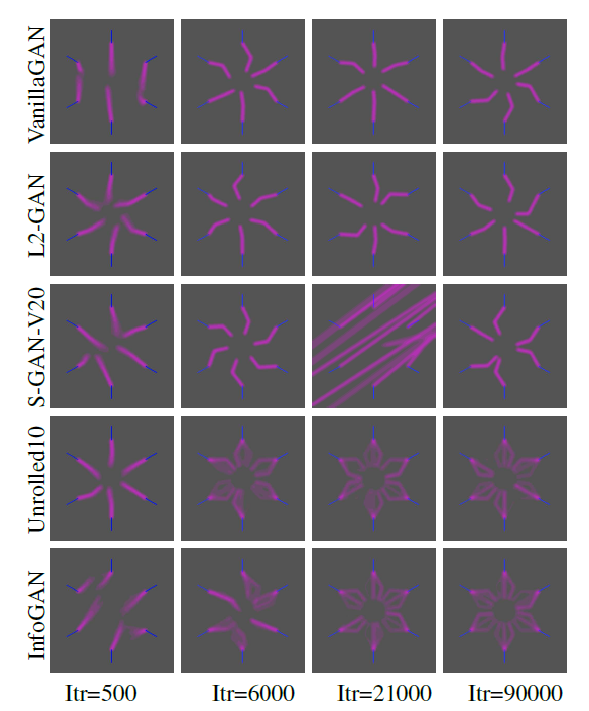
GAN模型引入轨迹预测的重要目的就是有助于生成多条轨迹(分布),文章为探究不同类GAN模型对多轨迹的预测能力,特地人工生成了一个测试场景(如下图):
- 蓝色为已知轨迹,红色为待预测轨迹。
- 从六个方向上产生轨迹,并在每个方向轨迹上又产生三个具体的分支。

不同的baseline模型在不同的迭代周期产生的预测结果如下图所示,从而验证了InfoGAN对多合理轨迹预测的有效性,其能够在更短的迭代周期中识别出多种可能性的轨迹:
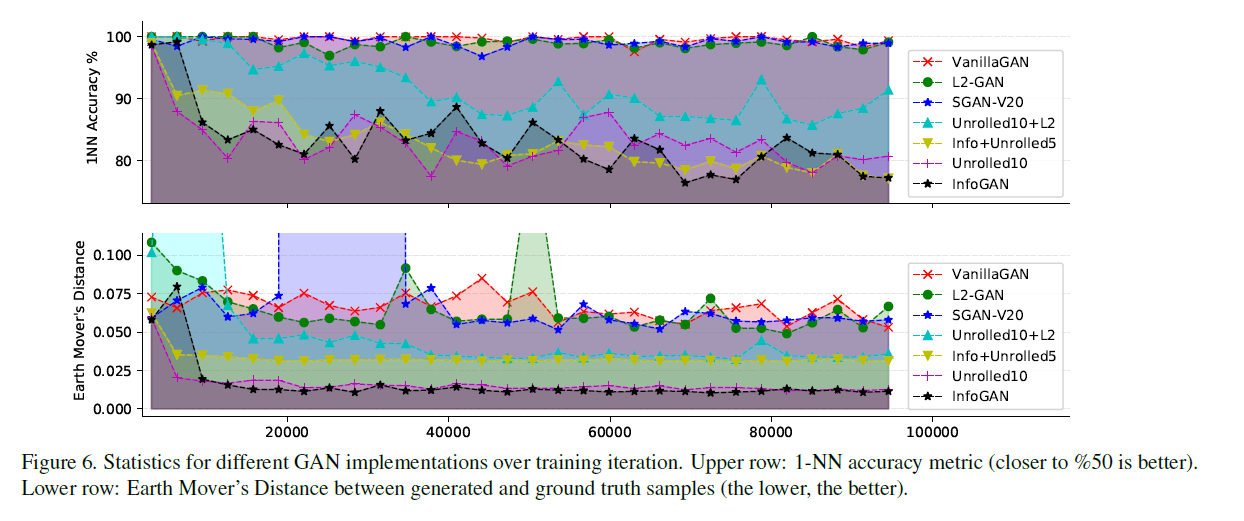
此外,文章还使用了1-Nearest Neighbor classifier和Earth Mover's Distance两种方法对真实未来轨迹和生成轨迹的质量进行评估:
- 对于1-Nearest Neighbor classifier,越接近50%越好。
- 对于EMD,越低越好。