一、命令式编程(imperative)和符号式编程(symblic)
命令式:
import numpy as np a = np.ones(10) b = np.ones(10) * 2 c = b * a d = c + 1
当程序执行到 c=b∗a时,代码开始做对应的数值计算. 符号式编程于此不同,需要先给出一个函数的定义(可能十分复杂).当我们定义这个函数时,并不会做真正的数值计算.这类函数的定义中使用数值占位符.当给定真正的输入后,才会对这个函数进行编译计算.
符号式编程:
上面的例子用符号式重新写:
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)
上述代码中,语句C=B∗A并不会触发真正的数值计算,但会生成一个计算图(也称符号式编程)描述这个计算.
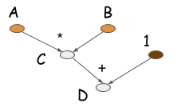
大部分符号式编程都显性或隐性的包含一个编译的步骤,把计算转换成可以调用的函数.上面的例子中,数值计算仅仅在代码最后一行进行.其一个重要特点是其明确有构建计算图和生成可执行代码两个步骤.对于神经网络,一般会用一个就算图描述整个模型.
命令式编程更加灵活
用python调用imperative-style库十分简单,编写方式和普通的python代码一样,在合适的位置调用库的代码实现加速.如果用python调用symbolic-style库,代码结构将出现一些变化,比如iteration可能无法使用.尝试把下面的例子转换成symbolic-style
a = 2 b = a + 1 d = np.zeros(10) for i in range(d): d += np.zeros(10)
如果symblic-style API不支持for循环,转换就没那个直接.不能用python的编码思路调用symblic-style库.需要利用symblic API定义的domain-specific-language(DSL).深度学习框架会提供功能强大的DSL,把神经网络转化成可被调用的计算图.
感觉上imperative program更加符合习惯,使用更加简单.例如可以在任何位置打印出变量的值,轻松使用符合习惯的流程控制语句和循环语句.
符号式编程更加有效
既然imperative pragrams更加灵活,和计算机原生语言更加贴合,那么为什么很多深度学习框架使用symbolic风格? 最主要的原因式效率,内存效率和计算效率都很高.比如下面的例子
import numpy as np a = np.ones(10) b = np.ones(10) * 2 c = b * a d = c + 1
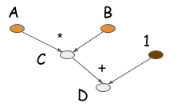
1、对于imperative programs中,需要在每一行上都分配必要的内存
2、symbolic programs限制更多.因为只需要d,构建计算图后,一些中间量,比如c的值将无法看到.
另外:
symbolic program还可以通过operation folding优化计算.在上述的例子中,乘法和加法可以展成一个操作,如下图所示.
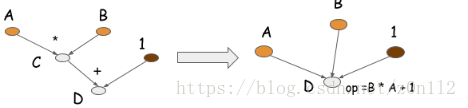
如果在GPU上运算,计算图只需要一个kernel,节省了一个kernel.在很多优化库,比如caffe/CXXNet,人工编码进行此类优化操作. operation folding可以提高计算效率.
imperative program中不能自动operation folding,因为不知道中间变量是否会被访问到. symbolic program中可以做operation folding,因为获得了完整的计算图,而且明确哪些量以后会被访问,哪些量以后都不会被访问.
二、深度学习框架
(参考https://blog.csdn.net/yeler082/article/details/78755095)
1、说明
深度学习框架也就像Caffe、tensorflow这些是深度学习的工具,简单来说就是库,编程时需要import caffe、import tensorflow。作一个简单的比喻,一套深度学习框架就是这个品牌的一套积木,各个组件就是某个模型或算法的一部分,你可以自己设计如何使用积木去堆砌符合你数据集的积木。好处是你不必重复造轮子,模型也就是积木,是给你的,你可以直接组装,但不同的组装方式,也就是不同的数据集则取决于你。
2、 应用优势
深度学习框架的出现降低了入门的门槛,你不需要从复杂的神经网络开始编代码,你可以依据需要,使用已有的模型,模型的参数你自己训练得到,你也可以在已有模型的基础上增加自己的layer,或者是在顶端选择自己需要的分类器和优化算法(比如常用的梯度下降法)。
当然也正因如此,没有什么框架是完美的,就像一套积木里可能没有你需要的那一种积木,所以不同的框架适用的领域不完全一致。 总的来说深度学习框架提供了一些列的深度学习的组件(对于通用的算法,里面会有实现),当需要使用新的算法的时候就需要用户自己去定义,然后调用深度学习框架的函数接口使用用户自定义的新算法.
3、 关于组件
大部分深度学习框架都包含以下五个核心组件:
1. 张量(Tensor) ——数据的表现形式
2. 基于张量的各种操作 ——各种操作
3. 计算图(Computation Graph) ——操作的集合和优化
4. 自动微分(Automatic Differentiation)工具
5. BLAS、cuBLAS、cuDNN等拓展包——加速训练
4、详细介绍部分组件
计算图
随着技术的不断演进,加上脚本语言和低级语言各自不同的特点(概括地说,脚本语言建模方便但执行缓慢,低级语言则正好相反),因此业界逐渐形成了这样的一种开发框架:前端用Python等脚本语言建模,后端用C++等低级语言执行。而这里,在前端和后端之间起到关键耦合作用的就是计算图。
BLAS、cuBLAS、cuDNN等拓展包——提高运算效率
- 第一种方法是模拟传统的编译器。就好像传统编译器会把高级语言编译成特定平台的汇编语言实现高效运行一样,这种方法将高级语言转换为C语言,然后在C语言基础上编译、执行。为了实现这种转换,每一种张量操作的实现代码都会预先加入C语言的转换部分,然后由编译器在编译阶段将这些由C语言实现的张量操作综合在一起。目前pyCUDA和Cython等编译器都已经实现了这一功能。
- 第二种方法就是前文提到的,利用脚本语言实现前端建模,用低级语言如C++实现后端运行,这意味着高级语言和低级语言之间的交互都发生在框架内部,因此每次的后端变动都不需要修改前端,也不需要完整编译(只需要通过修改编译参数进行部分编译),因此整体速度也就更快。
- 除此之外,由于低级语言的最优化编程难度很高,而且大部分的基础操作其实也都有公开的最优解决方案,因此另一个显著的加速手段就是利用现成的扩展包。
三、什么是TensorFlow
1、 关于TensorFlow
https://baijiahao.baidu.com/s?id=1587378061168798378&wfr=spider&for=pc
2、关于Python,Pycharm,Anaconda(anaconda可以看做Python的一个集成安装,安装它后就默认安装了python、IPython、集成开发环境Spyder和众多的包和模块,非常方便。)
https://blog.csdn.net/haha555hahha/article/details/76736604
https://blog.csdn.net/weixin_37683002/article/details/82287248
3、关于TensorFlow在windows上安装与基于MINST数据集的简单示例(MINST是一个大量手写体图片组成的数据库,用于计算机视觉的入门)
https://blog.csdn.net/darlingwood2013/article/details/60322258/
概念:TensorFlow 是世界上最受欢迎的开源机器学习框架,能够让你直接解决各种机器学习任务,提供了各种API。
用途和优势:可以用其构建各种深度学习模型,例如反向传播的大型神经网络模型,模型表现为操作图的形式,可以让这部分图在这里运行,让另一部分图分布式运行在不同的机器群上,甚至可以让这部分注重数学的图在GPU上运行,与此同时,数据输入部分的代码在CPU上运行。
使用:最开始只可以用python来使用TensorFlow,现在已经可以支持java,C++等多种平台。可以安装在windows、mac、linux不同的操作系统。
扩展:还有一个项目是称为TensorBoard的工具 ,这是包中的可视化工具之一 。