涉及到这个问题,首先要解答,索引这种数据结构在InnoDB与MyIsam中有何不同
非常经典的文章:https://blog.csdn.net/qq_25551295/article/details/48901317
myisam的主索引和次索引都指向物理行,下面来进行讲解
innodb的主键下存储该行的数据,此索引指向对主键的引用
myisam的索引存储图如下,可以看出,无论是id还是cat_id,下面都存储有执行物理地址的值。通过主键索引或者次索引来查询数据的时候,都是先查找到物理位置,然后再到物理位置上去寻找数据。

innodb的索引存储图如下,我们会发现,主键索引下面直接存储有数据,而次索引下,存储的是主键的id。通过主键查找数据的时候,就会很快查找到数据,但是通过次索引查找数据的时候,需要先查找到对应的主键id,然后才能查找到对应的数据。
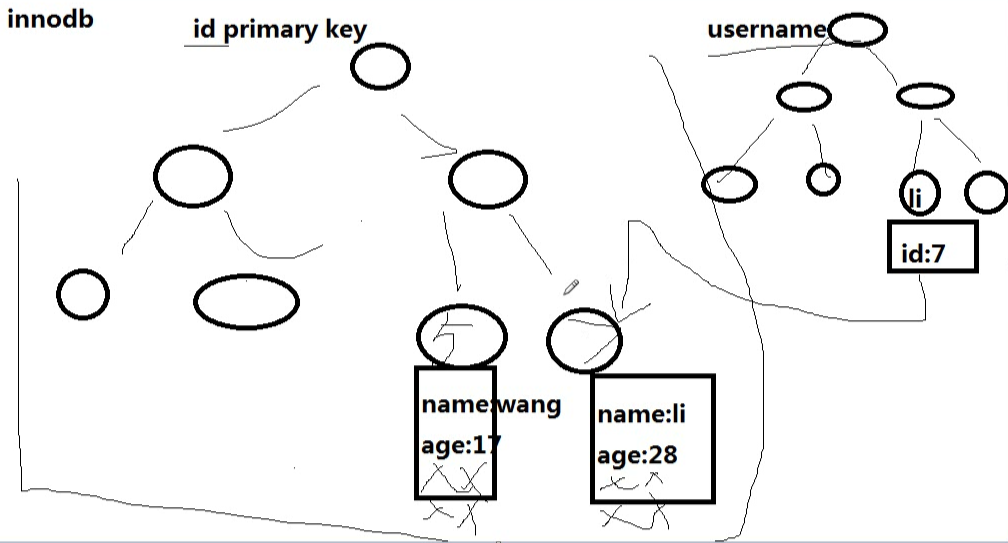
Innodb的主索引文件上 直接存放该行数据,称为聚簇索引,次索引指向对主键的引用
myisam中, 主索引和次索引,都指向物理行(磁盘位置).
注意: innodb来说,
1: 主键索引 既存储索引值,又在叶子中存储行的数据
2: 如果没有主键, 则会Unique key做主键
3: 如果没有unique,则系统生成一个内部的rowid做主键.
4: 像innodb中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为”聚簇索引”
“要修改数据,首先要找到数据,而如果没有索引,就会直接锁住表的数据,就会锁住其他的会话。
所以,如果你看innodb的最佳实践里,一定会要你创建主键索引,如果你没有主键,可以用一个代理键,也就是自增列实现。”
“InnoDB行锁是通过给索引上的索引项加锁来实现的”
MyIsam索引和数据分离,InnoDB在一起,MyIsam天生非聚簇索引,最多有一个unique的性质,InnoDB的数据文件本身就是主键索引文件,这样的索引被称为“聚簇索引”
https://blog.csdn.net/silyvin/article/details/79332879
那么答案也出来了,InnoDB之所以可以锁行,是因为Innodb的主索引结构上,既存储了主键值,又直接存储了行数据,可以方便的锁住行数据,而MyIsam索引指向另一片数据文件,没有办法精确锁住数据段
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
https://mp.weixin.qq.com/s/e12zJEWJUW_y79LTs6BarQ
