第六次C博客作业
Q1.本章学习总结
1.1 学习内容总结
- 结构体如何定义,成员如何赋值
- 首先要定义一个结构体,常用的方法是
struct 结构名
{
结构成员
}; //注意这里有个分号
- 然后需要在主函数中声明结构体变量,可在声明时对逐一结构成员进行赋初值,也可以采用 结构体变量名.结构成员名= 的方式进行赋值
- 如果结构成员是char类型的,记得使用strcpy()函数进行赋值
struct student
{
int num;
int score;
}; //这里分号前可以直接写上结构体变量名,用逗号分隔,这样在下面使用不用先声明
int main()
{
struct student p = { 10,80 }; //声明时直接按成员顺序逐个赋值
p.num = 10; //中间用点连接,不能用->
p.score = 80;
}
- 我们现在更支持使用typedef来定义结构体,和普通的定义基本一致,而且可以改变每次声明新的变量时都要写的struct xxx
typedef struct student
{
int num;
int score;
}STU,*stu;
int main()
{
STU a; //等同于struct student a
stu b; //等同于struct student *b;
}
- 结构体数组排序做法
- 个人觉得本质上和数组的排序基本一样,唯一要注意的点就是一个结构体赋值给另一个结构体时,所有的结构成员都会被替换
typedef struct student
{
char name[10];
int score;
}STU;
int main()
{
STU p[10], temp;
int i, j;
for (i = 0; i < 10; i++)
scanf("%s %d", p[i].name, &p[i].score); //给结构体数组赋值
for (i = 0; i < 10; i++)
for (j = i + 1; j < 10; j++)
if (p[i].score < p[j].score)
{
temp = p[i]; p[i] = p[j]; p[j] = temp; //和数组的选择排序类似,只是交换的是一整个结构体里的内容而已
}
}
- 结构体指针怎么用
- 这个我认为也和普通的指针类似,只是类型从int/char这样子的变成了一整个结构体
- 要注意取结构体指针的结构成员的写法,一般有下面的两种写法
STU *p;
(*p).score = 100; //括号不能省略
p->score = 100; //更常见的写法
p.score = 100; //这是错的!!!!
-
与普通指针类似,假设有STU *p=a(a是结构体数组),那么p即指向a[0] 的首地址,p+1指向a[1]的首地址
-
共用体、枚举类型做法
- 共用体和结构体长得很相似,但实际上它们大有不同:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
- 一般运用较少,在前几个结构成员相同,但因为几个结构成员不同导致后面要保存不同类型的内容时会用到。
- 枚举类型个人认为与宏定义较类似,直接举例说明
enum week{ Mon, Tues, Wed, Thurs, Fri, Sat, Sun }; //定义方式为enum 枚举类型名{每个值对应的名字}; 分号!!
/*这样子没有给初值定义完,默认Mon代表0,Tues代表1,以此类推*/
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun };
/*给了第一个名字初值,那么后面的Tues则为2,Wed为3,每个加1*/
enum week day; //枚举类型,输出星期的例子
scanf("%d", &day);
switch(day)
{
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
- 文件读写,文件中数据如何读进结构体数组
- 首先需要定义一个FILE类型的指针变量
- 打开文件的方式为 文件指针名=fopen("文件名","文件操作方式")
- 常用操作方式分为 r:只读;w:只写;a:追加在末尾;b:二进制文件;+:读和写
- 其中,用"r"打开文件时,文件必须存在;用"w"打开文件时,若打开的文件不存在,则以指定的文件名建立该文件,若打开的文件已经存在,则将该文件删去,重建一个新文件
- 文件可能会打开失败,这样fopen函数会返回NULL,在写程序时要注意对这部分有判断
- 有打开就要有关闭,记得要用 fclose(文件指针名) 来关闭文件
- 对文件数据进行读取、写入
- fgets(用于储存的目标字符串,读取长度,文件指针名) 可以用于实现从目标文件中读取字符串,用法与注意事项以前使用fgets基本相同(会读入 等),唯一不同的是最后一个从stdin(从键盘读入)改为了文件指针(从文件读入)
- fputs(想要存入的字符串,文件指针名) 可以实现将字符串写入目标文件中
- fputc、fgetc 用法与上面两个基本相同,从目标文件读入一个字符
- fscanf、fprintf 与scanf、printf基本相同,按格式从文件中读取、写入数据
- feof(文件指针名) 用于判断文件是否已经读到末尾
/*文件中数据读入结构体数组简单样例*/
typedef struct student
{
char name[10];
int score;
}STU;
int main()
{
FILE* fp;
STU p[50];
int i = 0;
fp = fopen("stu.txt", "r+");
if (fp == NULL) //记得要对打不开的情况做判断
{
exit(1);
}
while (!feof(fp))
{
fscanf(fp, "%s %d", p[i].name, &p[i].score);
i++;
}
fclose(fp); //读完记得关闭文件!!
}
- 其他一些对文件进行操作的函数
- fseek(FILE *stream, long offset, int fromwhere):函数设置文件指针stream的位置。如果执行成功,stream将指向以fromwhere( 偏移起始位置:文件头为0(SEEK_SET),当前位置为1(SEEK_CUR),文件尾为2(SEEK_END) )为基准,偏移offset(指针偏移量)个字节的位置。如果执行失败(比如offset超过文件自身大小),则不改变stream指向的位置。
- ftell(FILE *stream):用于得到文件位置指针当前位置相对于文件首的偏移字节数。
- rewind(FILE *stream):将文件内部的位置指针重新指向开头。
- remove(char *filename):用于删除指定文件。
- rename(char *oldname, char *newname):将指定文件进行更名。
1.2 本章学习体会
- 上半学期C语言的学期也进入了尾声,文件部分感觉通过一次大作业已经掌握了很多
- 而对于链表,我也试着将它运用到大作业里面,虽然写程序的时候遇到很多磕碰,但还是成功用链表写了程序的一部分
- 虽然是老生常谈了,但还是想说要多实践多运用,可能在课堂上听着感觉链表挺简单的,但一上手写起来又是生不如死了
(脑子:我学会了 手:不,你不会) - 没有任何捷径,多敲代码才是真理
- 代码量(本次大作业):887行
Q2.综合作业--“我爱成语”
2.1 文件介绍
2.1.1 头文件 idiom.h
- 头文件中所有的结构体、函数声明以及函数的功能全部在截图上的注释中

2.1.2 文件1 main.cpp
-
主界面函数功能
- 先在这里读取文件,检查文件是否存在
- 导入到登录界面、游戏的主菜单
- 根据用户不同的选择进入不同的函数
- 普通的主函数,选择1/2开始玩游戏,3对题库进行管理,4/5展示游戏排行榜,6展示游戏说明,7切换用户(就是重新登录),0退出游戏
-
代码截图

2.1.3 文件2 menu.cpp
-
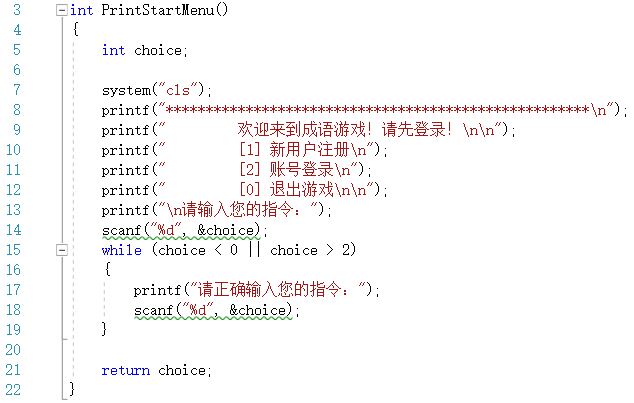
PrintStartMenu()函数
- 程序刚开始时的主界面,用来引导用户注册、登录
- 返回用户的选择,并传递给控制登录的函数
- 在主界面如果选择切换用户会回到这里
- 代码截图
-
LoginMenu()函数
- 传入在上一个函数中的选择n,如果用户在上一个界面选择0则退出,选择1代表注册,2代表登录
- 在这里打开储存用户信息的文件user.txt并读入结构体数组
- 对于新用户注册,采用如下流程:用户输入用户名 --> 遍历结构体数组检查是否有重复用户名,如有重新输入 --> 用户输入密码 --> 创建成功,将该账户名和密码写入结构体数组,并写入到user文件的末尾 --> 用户使用这个id直接登录到游戏中
- 对于用户登录,输入账号和密码,检查用户名和密码是否正确,如不正确提示“用户名或密码错误”并重新输入,如果正确则登录进游戏
- 最后返回用户名,以便于排名更新等操作
- 代码截图

-
PrintSelectMenu()函数
- 菜单界面,传入用户的名字用于问候
- 记录用户的选择返回主函数
- 代码截图

-
PrintInformation()函数
- 用于输出游戏说明
- getch()和按任意键继续那句可以用system("pause")代替
- 代码截图

-
ShowRanking()函数
- 根据传入的数字展示游戏的排名
- 先从文件中读入,再写到结构体数组中,然后再输出
- 代码截图

-
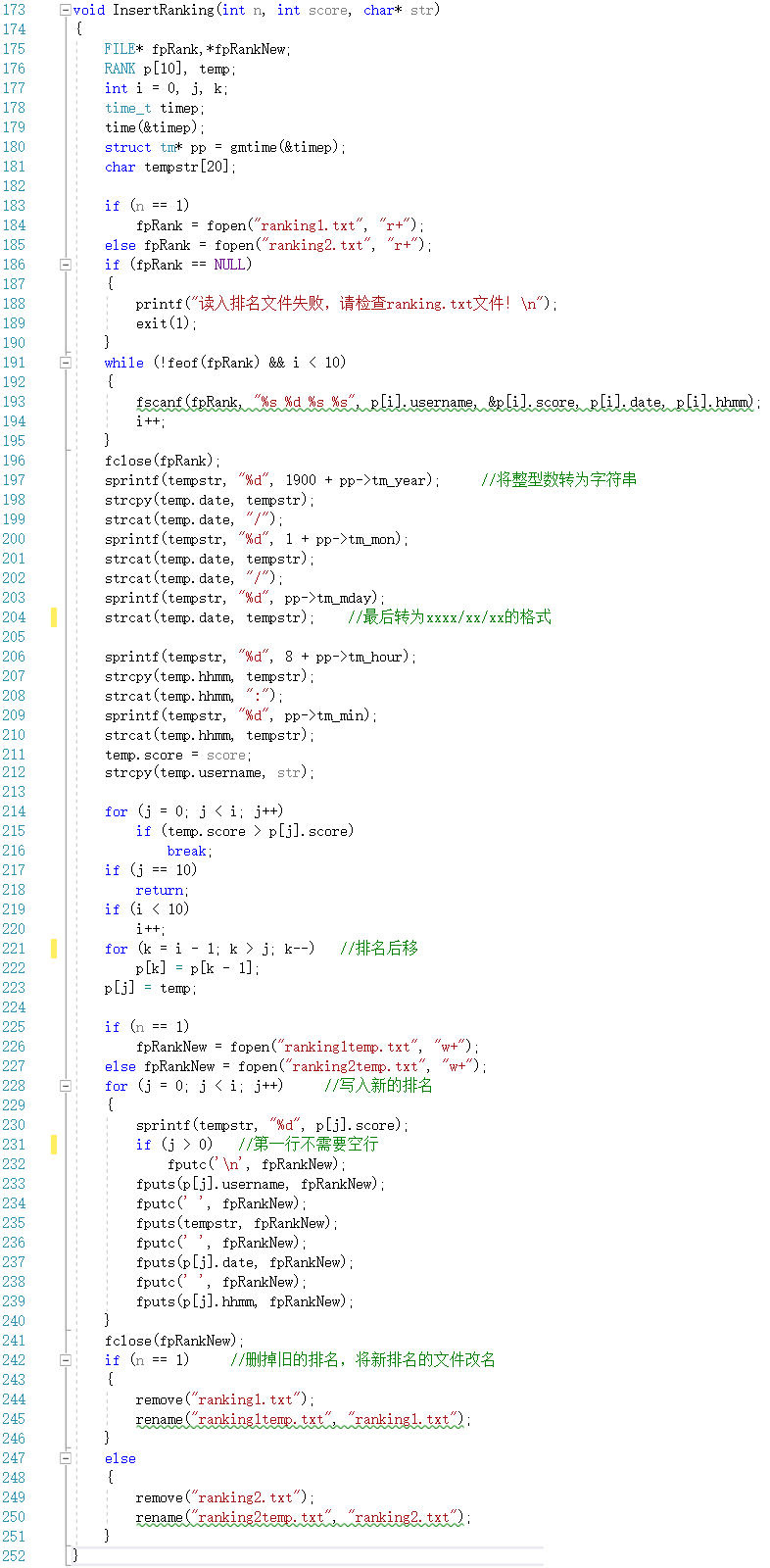
InsertRanking()函数
- 该函数传入三个数据:游戏号码(猜成语1,接龙2)、分数、用户名
- 该函数的主要流程如下:读入排名文件并写入结构体数组中 --> 读取当前时间,和传入的三个参数一起储存到temp的临时的结构体中 --> 逐个比较直到全部排名读完或者出现一个排名的分数低于temp中的分数 --> 如果已有10个排名且读完了全部排名,则不对排名进行操作就返回;如果读完排名但排名小于10个则将新排名插在末尾;如果在末尾前读完则将比temp中分数低的全部后移一位 --> 建立新的临时排名文件,按新排好序的排名重新编写排名文件 --> 删除旧的排名文件,并将新的临时排名文件进行更名
- struct tm是time.h中带有的结构体,里面的结构成员(年份、月份、日期、小时、分钟等等)都是int类型变量,gmtime()函数将当前时间储存到这个结构体中,经过一定处理后就是当前时间
- 正因为它们都是int类型的变量,不能通过fputs函数写入到文件中,所以我又使用了sprint()函数,将数据转化成字符串类型,再进行存储,具体使用方法: sprintf(要存储到的字符串名,对数据进行格式化的类型,要处理的数据),其中第二项较为灵活,如%d就是转为十进制整数,%o就是整数转成八进制等等
- 还用到了remove()和rename()函数,这两个在前面知识点总结部分有说明
- 代码截图
2.1.4 文件3 idiomedit.cpp
-
IdiomsEdit()函数
- 该函数用于输出题库管理的菜单,并根据用户的选择进入不同的函数
- 代码截图

-
GetIdiomsData()函数
- 该函数读取成语文件的资料,并将它们储存到链表中
- 使用了跨文件的全局变量COUNT记录成语数量
- 使用的是带头节点的链表,要注意一开始给头节点指针空间并让head->next=NULL
- 使用strchr()函数来寻找冒号,将这一点改成�后,将�前的作为成语本身存储,后面的为解释
- 要注意要对找不到冒号的情况进行处理,如果文件中有一行没有冒号或者单独空行,VS会报错数组越界(好像是叫这个)
- 代码截图

-
OutputIdioms()函数
- 作用是输出所有成语
- 注意,由于是带头结点的链表,所以临时指针要从头节点的next开始
- 代码截图

-
InsertNewIdiom()函数
- 用于让用户自己插入一个新的成语
- 遍历判断这个成语是否有重复
- 将新的成语插入到链表头节点,再往前移动头节点(这样比较方便)
- 最后将新成语写入文件末尾,并及时fclose()进行保存
- 代码截图

-
DeleteIdiom()函数
- 用于让用户删除目标成语,其实就是链表中目标结点的删除
- 和排名相同,创建了一个新的临时文件
- 删除目标结点后遍历链表,将链表里的内容写入到新的临时文件中
- 然后删除旧的文件,将临时文件重命名
- 代码截图

-
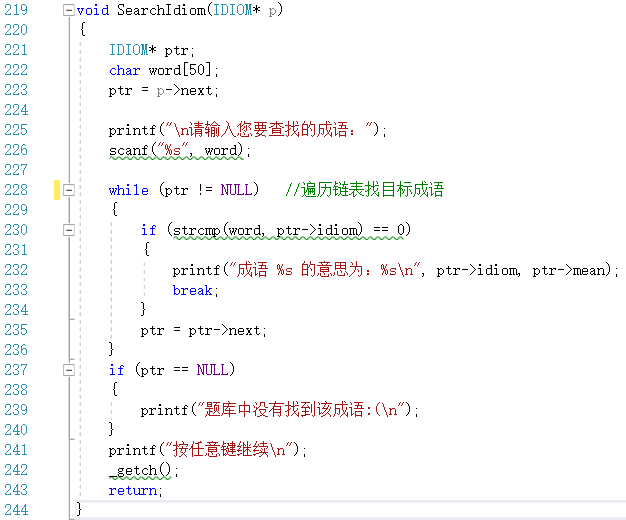
SearchIdiom()函数
- 用于搜索目标成语,输出这个成语的意思
- 其实就是遍历链表进行对比而已
- 代码截图
2.1.5 文件4 game.cpp
-
GameMenu()函数
- 游戏难度选择的菜单,使用了sleep()函数模拟倒计时的功能,其中sleep()函数中括号填的是毫秒数
- 代码截图
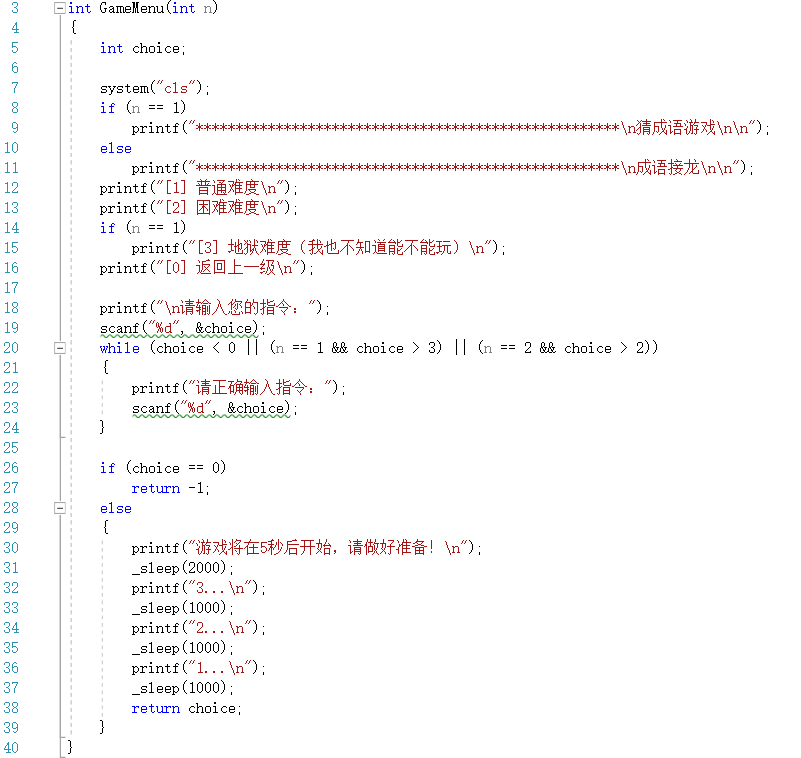
-
GuessingGame()函数
- 进行猜成语游戏执行的函数,根据难度不同会有不同的提示
- 由于链表不能直接进行随机,所以我选择了根据成语数量生成一个随机数,然后让链表往下走这么次的方法来进行随机
- USED数组是用来记录对应这个随机数的成语是否出现过了,其实可以并在链表的结构成员中
- 而对于挖空,由于一个中文占两个字节,所以在随机挖空时随机数的范围除以2,最后挖空时再乘2比较好,防止挖空到一个字的尾加另一个字的头
- 然后用户输入答案,检查是否超时,再与正确答案做比对,记录连续答对的题目数量
- 代码截图

-
ChainGame()函数
- 进行成语接龙游戏的函数
- 由于数量比较大,就没有使用链表
- 一开始是系统随机找题,然后让玩家进行回答
- 如果回答正确,系统会在题库中随机找题一万次,比对第一个字和玩家输入的最后一个字(不采用遍历是为了增加随机性)
- 如果回答错误,或是一万次没有找到合适的词语,就将重新随机出题
- 用户回答的答案会在题库中进行比对,检查是否是成语、第一个字和系统出题的最后一个字是否相符、这个字有没有出现过
- 代码截图

2.2 运行结果
2.2.1 登录界面
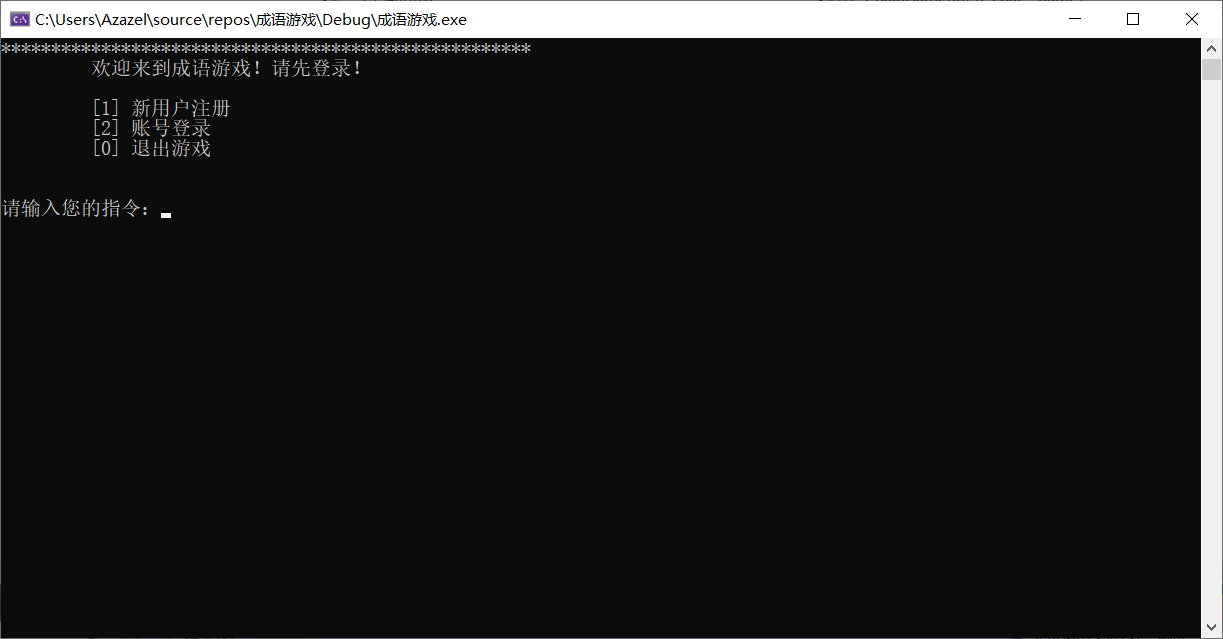

2.2.2 游戏界面
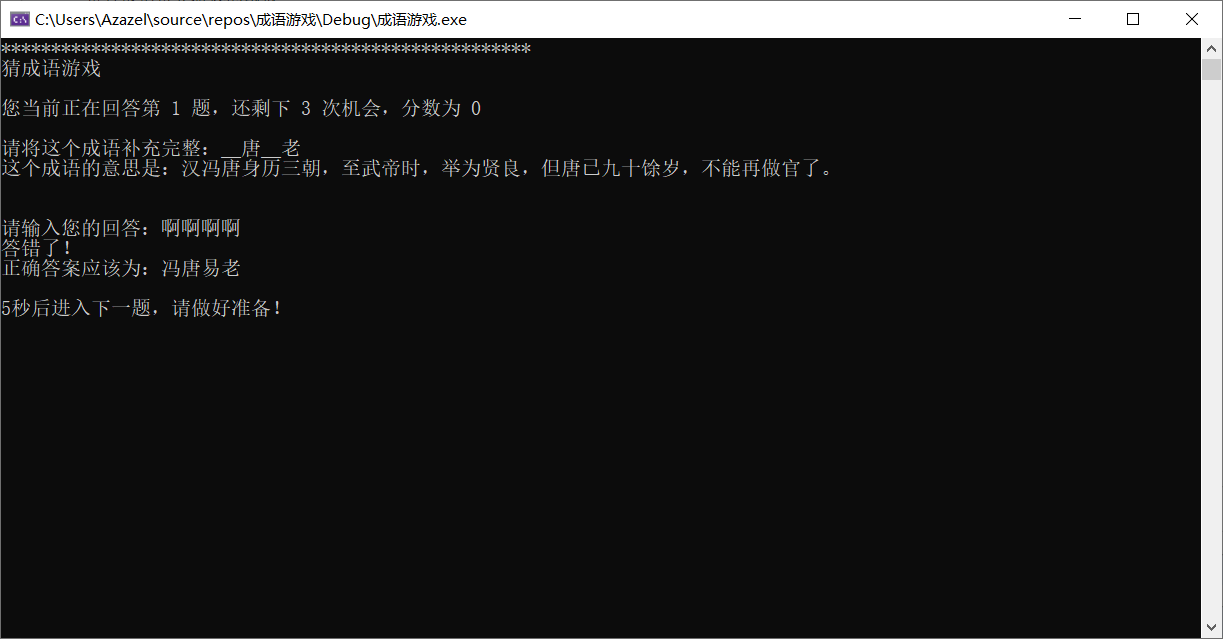

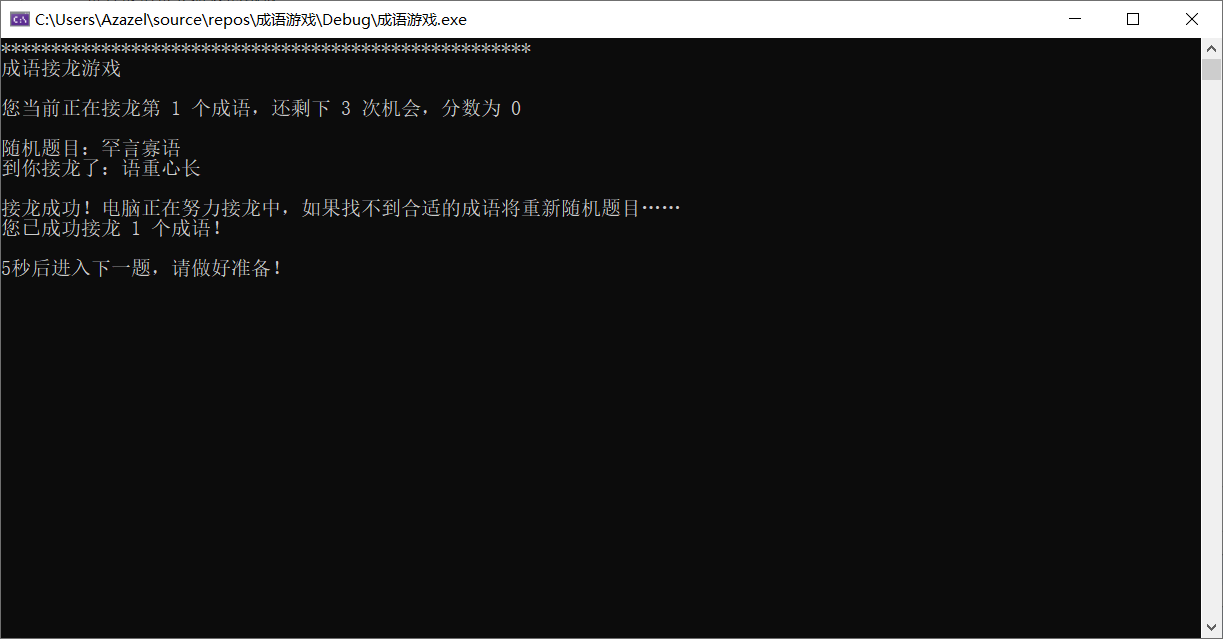
2.2.3 排名界面
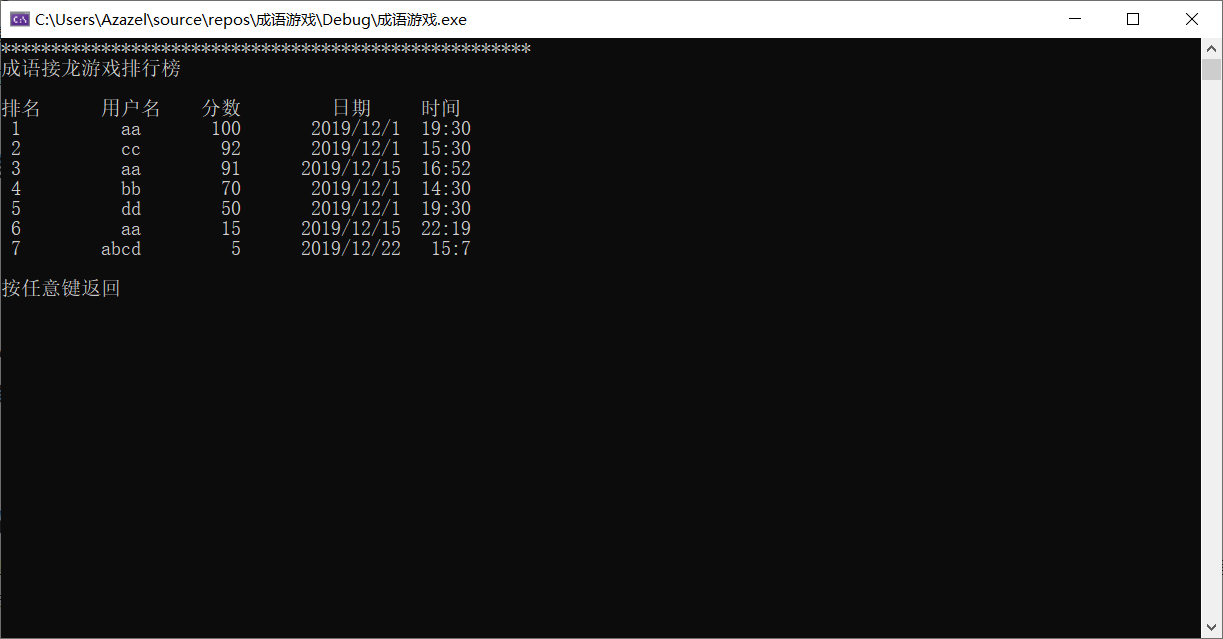
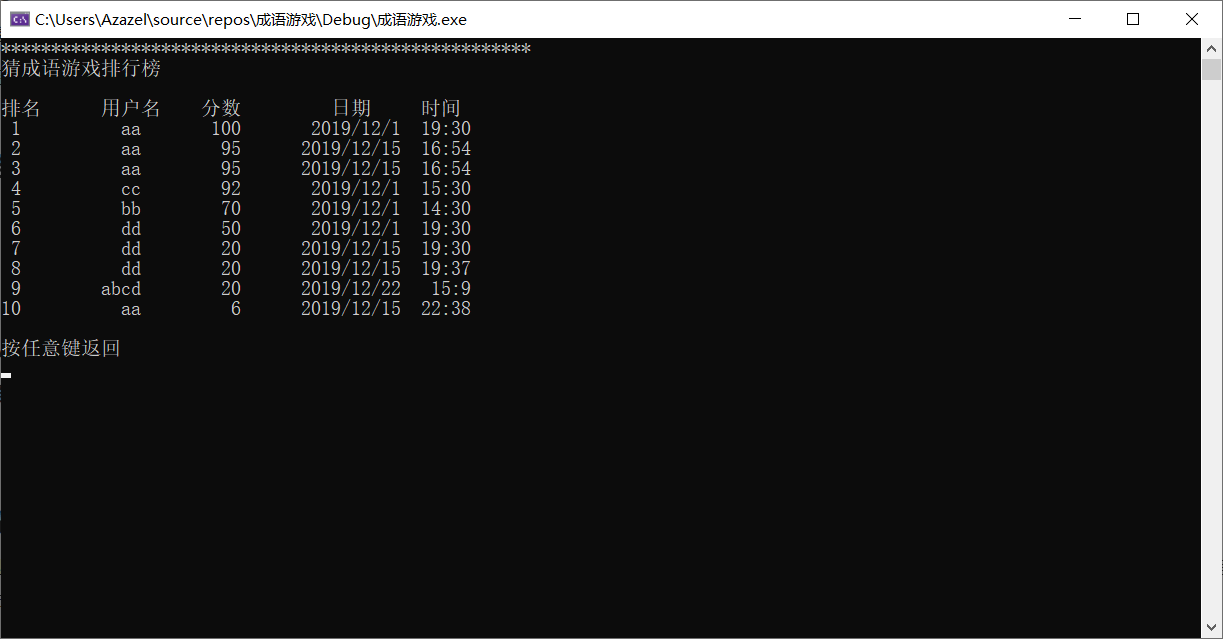
2.3 大作业总结
2.3.1 碰到问题和解决方法
Q1.莫名奇妙的报错?

A1.这个似乎是函数定义、声明、使用时有一个函数名字写错了,检查哪个错了改掉即可
Q2.还是莫名其妙的报错!
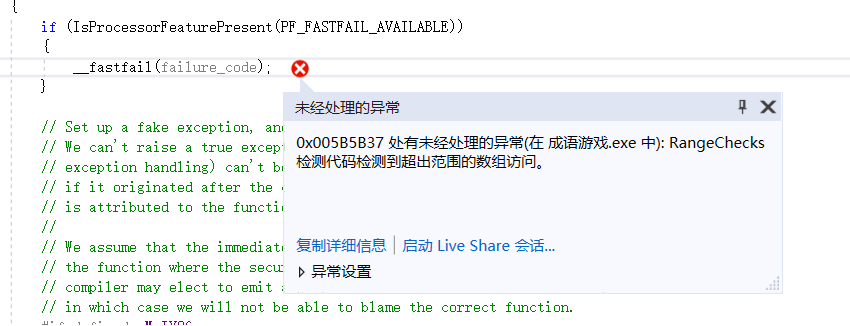
A2.这个是我在GetIdiomsData()函数中提到的,文件中可能有一行没有冒号,或是最后多了一行空行,导致loc没有定位到冒号,此时他为NULL,在这个基础上再对字符数组进行操作必然越界。所以要注意对找不到冒号时的情况进行判断!
Q3.链表无法随机,怎么随机出题
A3.我选择了根据链表长度,生成随机数让遍历指针执行那么多次的next,从而实现随机
Q4.挖空后成语变成乱码
A4.这个就是挖空挖到一个字的尾和另一个字的头了,要注意一个汉字占两个字节,再进行操作,参考上面挖空部分的代码
Q5.排名有更新后也出现乱码
A5.因为按照“一个排名加一个换行”的方式输出,会导致最后一名后面多一个空行,所以我后来采用了“一个换行加一个排名”的方式,只要对第一行进行判断即可
2.3.2 小结
- 一开始看到这个作业其实是很懵的,完全不知道从何下手,但是实际写起来远比想象中的容易,所以首先面对这种大作业不应该产生畏难情绪。
- “哇要写这么多/效果这么炫酷,这是什么函数啊??”这种无意义的话就不必了,不要看到一个没见过的函数/没见过的效果就哇好难哇好难,有的时候它们真的很简单,实现的代码你也都学过,只是你有没有往那个方面想,别人想到了,自己没有想到而已
- 遇到想要实现的功能又不知道何从下手,建议直接百度,说真的。我的sprintf()就是从百度学到的。不要说我不会就直接放弃了,还是要有点追求的嘛
- 本次作业由于时间比较紧迫,很多小细节没有实现到位(例如加载、密码输入变成*号等功能),但这些小功能也都是从同学的程序中学到的一个思路,还是要加强优秀代码的阅读
- 是一次综合能力全部运用的大作业,自我感觉还算满意吧