1.单例模式
1.1C++
转自:http://blog.sina.com.cn/s/blog_7746d7e6010182ge.html
1.2c#(剑指offer面试题2)
(1)c#中静态构造函数可以确保函数只调用一次
2.itoa
转自:http://liangshuizwl.blog.163.com/blog/static/128268121200981994020314/
功 能:把一整数转换为字符串
用 法:char *itoa(int value, char *string, int radix);
详细解释:itoa是英文integer to array(将int整型数转化为一个字符串,并将值保存在数组string中)的缩写.
参数:value: 待转化的整数。
radix: 是基数的意思,即先将value转化为radix进制的数,范围介于2-36
* string: 保存转换后得到的字符串。
返回值:
char * : 指向生成的字符串, 同*string。
char *my_itoa(int
num,char *str,int radix)
{
const char
table[]="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ";//2-36进制
char *ptr = str;
bool negative =
false;
if(num == 0)
{
*ptr++='0';
*ptr='\0'; // don`t forget the end of the string is '\0'
return str;
}
if(num<0)//if num is negative ,the add '-'and change num to positive
{
*ptr++='-';
num*=-1;
negative =
true;
}
while(num)
{
*ptr++ = table[num%radix];
num/=radix;
}
*ptr = '\0'; //if num is negative ,the add '-'and change num to
positive// in
the below, we have to converse the string
char *start =
(negative ? str+1 : str); //now start points the head of the string
ptr--; //now prt
points the end of the string
while(start<ptr) --------逆序
{
char temp = *start;
*start = *ptr;
*ptr = temp;
start++;
ptr--;
}
return str;
}
主要考虑几点:1.负数2.while逐位3.逆转
3.key/value
单机存储100亿大数据量的key-value数据,要求能够支持插入和查询操作,单条数据长度不定,平均约1024字节,假设可用内存10G,磁盘空间不限,请设计一个存储查询模块,支持按照key来获取对应的value,设计目标以查询性能为先,尽量节约资源,查询可以理解为网民的检索行为。
1) 说明该设计方案和主要思路,以及优缺点
2) 请详细说明该设计思路下查询和插入的操作流程
3)如果增加更新操作,请评估前面的设计方案是否可行,需要做怎样的修改,不可行则指明主要问题点。
分析:
1)数据量大小为:
data_size=100亿*1024Byte=10^10*10^3Byte=10^13Byte=10^4G
假设每个key的长度不超过128Byte。
使用2种文件存储数据:索引文件和数据文件。
索引文件采用类似B+树的结构化存储,一条数据对应一条记录,一条记录包括:数据的key、存储该数据的数据文件ID以及数据文件偏移量,占用空间:
record_size=key_size+data_file_ID_size+offset_size=128+4+8=140Byte。
B+树共有3层,内节点只存储最多M个关键字key和相应的M棵子树的位置,第i个关键字是第i棵子树中的最小关键字,叶节点存储最多M个key-value数据。每个节点最多包含M个key,M^3=100亿=10^10,M=2200。
内节点有2种形式:一是存储在索引文件中,包含的域有:关键字key,相应的子节点的索引文件ID和文件偏移量,占用空间:
inner_node_size_in_file=(key_size+index_file_ID_size+file_offset_size)*M=(128+4+8)*2200=30800Byte=300K。
二是存储在内存中,除了上面提到的域,还包括指向子节点的指针域,占用空间:
Inner_node_size_in_memory*M=(inner_node_size_in_file+pointer_size)*M=144*2200Byte=316800Byte=310K。
第一层和第二层占用空间:
(M+1)*inner_node_size_in_momery=666M,
可以全部存储在内存中。
内节点按顺序写入索引文件,采用惰性空间分配策略,即使内节点没有满,也分配最大空间inner_node_size_in_file。这样保证内节点可以在原地更新,保持有序状态。假设索引文件最大index_file_size=2G,一个索引文件可以容纳内节点数目:
Inner_count_in_file=index_file_size/ inner_node_size_in_momery=6990>inner_node_count=M+1
一个索引文件足够了。
叶节点包含key-value数据,占用空间:Leaf_size_in_memory=M*data_size=2200*1024=2200K
叶节点以在文件尾追加方式写入数据文件,不需要保持有序,因为B+树的第二层内节点记录了所有叶节点的数据文件ID和文件偏移量。假设一个数据文件大小是data_file_size=2G,数据文件数目为data_file_count=data_size/data_file_size=5000
优点:
1) B+树采用3层,第1层和第2层是内节点,是索引节点,存储在索引文件,可以全部存储在内存,第3层是叶节点,存储在数据文件,部分缓存在内存。插入和查找一条数据,最多需要访问硬盘一次。
2) 索引文件采用惰性空间分配策略保证内节点可以在原地更新,保持有序状态。
3)数据文件的更新一直是在尾部追加,不需要移动数据。
缺点:
1) 索引文件浪费了部分空间。
第二问:
查找:在根节点二叉查找关键字,下降到第二层某一个节点,二叉查找关键字,下降到第三层某一个关键字,若该条数据不在内存中,从数据文件读入,若在内存中,直接返回数据。
插入:与查找类似,找到该条数据应该在的位置,添加到最后一个数据文件的末尾。
第三问:若增加更新操作,前面的方案可行,需要做下列修改:
将数据按照大小分类存储到不同的数据文件中。假设数据大小平均分布在512Byte到1536Byte之间,步长平均为128Byte,数据文件分类为存储512Byte的,存储512+128Byte的,存储512+128*2Byte的,……,类似内存池的做法。更新数据时,将数据写到能容纳该条数据的最小分类的数据文件,将该位置记为空闲,加到该数据文件的空闲位置链表。链表的指针可以用空闲位置的前4个字节表示,文件的最开始4个字节表示链表头部指针。当然,这样会浪费部分空间。可以监控每种文件的空间使用情况,做出调整。
4.自己实现malloc/free
转自:http://www.cnblogs.com/wuyuegb2312/archive/2013/05/03/3056309.html
#define ALLOCSIZE 10000 static char allocbuf[ALLOCSIZE]; /*storage for alloc*/ static char *allocp = allocbuf; /*next free position*/ char *alloc(int n) { if(allocbuf+ALLOCSIZE - allocp >= n) { //存在足够空间 allocp += n; return alloc - n; } else return 0; } void afree(char *p) { if (p >= allocbuf && p<allocbuf + ALLOCSIZE) allocp = p; }
这种简单实现的缺点:
1.作为代表内存资源的allocbuf,其实是预先分配好的,可能存在浪费。
2.分配和释放的顺序类似于栈,即“后进先出”,释放时如果不按顺序会造成异常。
这个实现虽然比较简陋,但是依然提供了一个思路。如果能把这两个缺点消除,就能够实现比较理想的malloc/free。
仅仅依靠地址运算来进行定位,是限制分配回收灵活性的原因,它要求已使用部分和未使用部分必须通过某个地址分开成两个相邻区域。为了能让这两个区域能够互相交错,甚至其中还包括一些没有分配的地址空间,需要使用指针把同类的内存空间连接起来形成链表,这样就可以处理地址不连续的一系列内存空间。但是为什么只连接了空闲空间而不连接使用中的空间?这么问可能出于在对图中二者类比时的直觉而没有经过思考,这很简单,因为没有必要。前者相互链接是为了能够在内存分配时遍历所有空闲空间,并且在使用free()回收已使用空间时进行重新插入。而对于使用中的空间,由于我们在分配空间时已经知道它们的地址了,回收时可以直接告诉free(),并不用像malloc()时进行遍历。
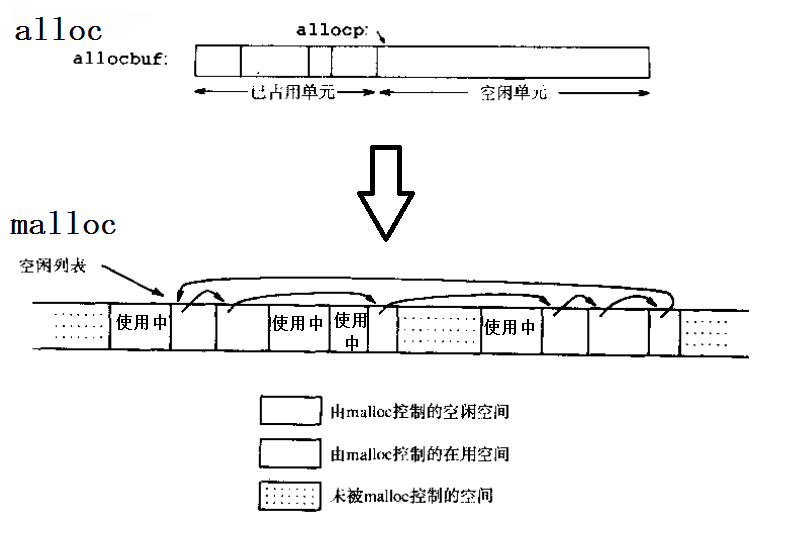
既然提到了链表,可能对数据结构稍有了解的人会立刻写下一个struct来代表一个内存区域,其中包含一个指向下一个内存区域的指针,但是这个struct的其他成员该怎么写呢?作为待分配的内存区域,大小是不定的,如果把它声明为struct的成员变量显然不妥;如果声明为一个指向某个其他的区域的指针,这似乎又和上面的直观表示不相符合。因此,这里仍然把控制结构和空闲空间相分开,但保持它们在内存地址中相邻,形成下图的形式,而正由这个特点,我们可以利用对控制结构指针的指针运算来定位对应的内存区域:
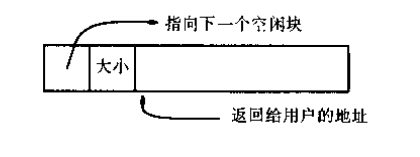
对应地,把控制信息定义为Header:

typedef long Align;/*for alignment to long boundary*/ union header { struct { union header *ptr; /*next block if on free list*/ unsigned size; /*size of this block*/ } s; Align x; }; typedef union header Header;
使用union而不是直接使用struct的原因是为了地址对齐。这里是long对齐,union的x永远不会使用。
这样,malloc的主要工作就是对这些Header和其后的内存块的管理。
void *malloc(unsigned nbytes) { Header *p, *prevp; unsigned nunits; nunits = (nbytes+sizeof(Header)-1)/sizeof(Header) + 1; if((prevp = freep) == NULL) { /* no free list */ base.s.ptr = freep = prevp = &base; base.s.size = 0; } for(p = prevp->s.ptr; ;prevp = p, p= p->s.ptr) { if(p->s.size >= nunits) { /* big enough */ if (p->s.size == nunits) /* exactly */ prevp->s.ptr = p->s.ptr; else { p->s.size -= nunits; p += p->s.size; p->s.size = nunits; } freep = prevp; return (void*)(p+1); } if (p== freep) /* wrapped around free list */ if ((p = morecore(nunits)) == NULL) return NULL; /* none left */ } }
实际分配的空间是Header大小的整数倍,并且多出一个Header大小的空间用于放置Header。但是直观来看这并不是nunits = (nbytes+sizeof(Header)-1)/sizeof(Header) + 1啊?如果用(nbytes+sizeof(Header))/sizeof(Header)+1岂不是刚好?其实不是这样,如果使用后者,nbytes+sizeof(Header)%sizeof(Header) == 0时,又多分配了一个Header大小的空间了,因此还要在小括号里减去1,这时才能符合要求。
malloc()第一次调用时建立一个退化链表base,只有一个大小是0的空间,并指向它自己。freep用于标识空闲链表的某个元素,每次查找时可能发生变化;中间的查找和分配过程是基本的链表操作,在空闲链表中不存在合适大小的空闲空间时调用morecore()获得更多内存空间;最后的返回值是空闲空间的首地址,即Header之后的地址,这个接口与库函数一致。
#define NALLOC 1024 /* minimum #units to request */ static Header *morecore(unsigned nu) { char *cp; Header *up; if(nu < NALLOC) nu = NALLOC; cp = sbrk(nu * sizeof(Header)); if(cp == (char *)-1) /* no space at all*/ return NULL; up = (Header *)cp; up->s.size = nu; free((void *)(up+1)); return freep; }
morecore()从系统申请更多的可用空间,并加入。由于调用了sbrk(),系统开销比较大,为避免morecore()本身的调用次数,设定了一个NALLOC,如果每次申请的空间小于NALLOC,就申请NALLOC大小的空间,使得后续malloc()不必每次都需要调用morecore()。对于sbrk(),在后面会有介绍。
这里有个让人惊讶的地方:malloc()调用了morecore(),morecore()又调用了free()!第一次看到这里时可能会觉得不可思议,因为按照惯性思维,malloc()和free()似乎应该是相互分开的,各司其职啊?但请再思考一下,free()是把空闲链表进行扩充,而malloc()在空闲链表不足时,从系统申请到更多内存空间后,也要先把它们转化成空闲链表的一部分,再进行利用。这样,malloc()调用free()完成后面的工作也是顺理成章了。根据这个思想,后面是free()的实现。在此之前,还有几个morecore()自身的细节:
1.如果系统也没有空间可以分配,sbrk()返回-1。cp是char *类型,在有的机器上char无符号,这里需要一次强制类型转换。
2.morecore()调用的返回值看上去比较奇怪,别担心,freep会在free()中修改的。使用这个返回值也是为了在malloc()里的判断、p = freep的再次赋值的语句能够紧凑。
void free(void *ap) { Header *bp,*p; bp = (Header *)ap -1; /* point to block header */ for(p=freep;!(bp>p && bp< p->s.ptr);p=p->s.ptr) if(p>=p->s.ptr && (bp>p || bp<p->s.ptr)) break; /* freed block at start or end of arena*/ if (bp+bp->s.size==p->s.ptr) { /* join to upper nbr */ bp->s.size += p->s.ptr->s.size; bp->s.ptr = p->s.ptr->s.ptr; } else bp->s.ptr = p->s.ptr; if (p+p->s.size == bp) { /* join to lower nbr */ p->s.size += bp->s.size; p->s.ptr = bp->s.ptr; } else p->s.ptr = bp; freep = p; }
free()首先定位要释放的ap对应的bp与空闲链表的相对位置,找到它的的最近的上一个和下一个空闲空间,或是当它在整个空闲空间的前面或后面时找到空闲链表的首尾元素。注意,由于malloc()的分配方式和free()的回收时的合并方式(下文马上要提到),可以保证整个空闲空间的链表总是从低地址逐个升高,在最高地址的空闲空间回指向低地址第一个空闲空间。
定位后,根据要释放的空间与附近空间的相邻性,进行合并,也即修改对应空间的Header。两个if并列可以使得bp可以同时与高地址和低地址空闲空间结合(如果都相邻),或者进行二者之一的合并,或者不合并。
完成了这三部分代码后(注意放到同一源文件中,sbrk()需要#include <unistd.h>),就可以使用了。当然要注意,命名和stdlib.h中的同名函数是冲突的,可以自行改名。
第一次审视源码,会发现很多实现可能原先并没有想到:Header的结构和对齐填充、空间的取整、链表的操作和初始化(边界情况)、malloc()对free()的调用、由malloc()和free()暗中保证的链表地址有序等等,确实很值得玩味。
另外再附上前文中提到的两个问题还有一些补充问题的简单思考:
1.Header与空闲空间相剥离,Header中包含一个指向其空闲空间的指针
这样做未必不可,相应地算法需要改动。同时,由于Header和空闲空间不再相邻,sbrk()获得的空间也应该包含Header的部分,内存的分布可能会更加琐碎。当然,这也可能带来好处,即用其他数据结构对链表进行管理,比如按大小进行hash,这样查找起来更快。
2.关于sbrk()
sbrk()也是库函数,它能使堆往栈的方向增长,具体可以参考:brk(), sbrk() 用法详解。
3.可以改进的方
空闲空间的寻找是线性的,查找过程在内存分配中可以看作是循环首次适应算法,在某些情况下可能很慢;如果再建立一个数据结构,如hash表,对不同大小的空间进行索引,肯定可以加快查找本身,并且能实现一些算法,比如最佳匹配。但查找加快的代价是,修改这个索引会占用额外的时间,这是需要权衡的。 morecore()中的最小分配空间是宏定义,在实际使用中完全可以作为参数传递,根据需要设定最小分配下限。