一个哥们在qq群里问了一个关于浮点数的程序,然后行了行浮点数的知识.竟然忘了,所有找了些文章.回忆回忆,理解理解
首先来聊天他的问题和让我无言以对的解决办法吧
""十六进制转负数浮点数怎么转换啊"
然后我默默的写了一个下面的东东
#include "stdafx.h"
#include <iostream>
#include <stdio.h>
#include <string>
#include <vector>
using namespace std;
float getFloat()
{
return (float)3.1423;
}
string FloatToHex ( float fNum )
{
int nInteger = (int)(fNum);
int nPower = 0;
while( fNum - nInteger > 1e-5 )
{
fNum *= 10;
nInteger = (int)(fNum);
nPower++;
}
std::cout<<nPower<<std::endl;
return "";
}
string FloatLength ( float fNum )
{
char cAryFloat[100] = {0};
sprint(cAryFloat, "%g", fNum);//从字符串cAryFloat中统计小数点后面有几位!!! %f 3.142300 %g 3.1423 %e 31423 + 1e-4
return "";
}
int _tmain(int argc, _TCHAR* argv[]) { FloatToHex(getFloat()); getchar(); return 0; } /* 在getFloat()函数中如果 return (float)3.14 那么最后打印的是2 在getFloat()函数中如果 return (float)3.1423 那么最后打印的是7 纠结了半天,猜测着可能你是返回3.1423但是你没办法控制float的精度,所有最后会打印7吧.
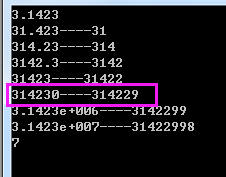
float最后可能是31422.9999999 打印的时候打印出了31423.但是强转int的话int仍然是32422.
所以又写了另外的函数string FloatLength ( float fNum ) 这个统计起来就没问题了..
*/
下面的是他的代码:
int i = 0xbd600d1b;
float *f = (float *)&i;
printf("%f
",*f);
float ff = -0.0547;
int *ii = (int *)&ff;
printf("%X
",*ii);
反正也对吧...但是总有一种无言以对的感觉...
接下来就要进入正题,讲一讲浮点数在内存中的表示了.
首先是在c和c#中的浮点类型分两种 单精度float和双精度double. float或者double在内存中的组织都遵循IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53
然后呢对于一个存储在内存的浮点数都包括3部分 : 符号位 指数位 小数部分 (而float和double的区别就是各部分占得位数可能不同)
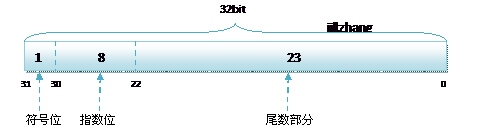
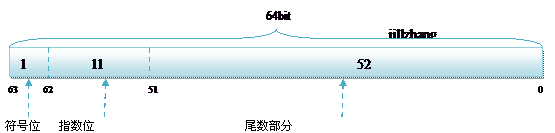
好了,既然知道了浮点数在内存中的表示方法,那么来个有意思的东西8.25 用10进制表示是82.5 * 10e-1, 那么用2进制表示是多少呢?
刚开始的时候我真的蒙了,真心不知道怎么用二进制表示啊(好吧8我是知道怎么用二进制表示的,只要大于0的数我都能用二进制表示出来,但是小数就呵呵了,从来没用到过) 答案是1000.01 琢磨了十分钟才搞明白怎么解这个东西:
8--->1000 0.25-->0[0*20] . 0 [0*2-1] 1[1*2-2] 所以就是1000.01了 再转换一下100.001 * 21 在转换就成了 1.00001 * 23
在二进制中010 跟10是等价的.所以啊最后如果用科学计数法表示的话都可以表示成1.xxx * 2xxx的形式 (注意跟十进制的区别80 你可以表示成8*101 但是二进制中不可能出现8这个数字,它只有0和1)
那么好啊,既然所有的二进制都可以表示成1.xxx * 2xxx那么小数点前面的肯定都是1了所以在存储到内存的时候默认都是1.xxx就好了,也没必要在内存中存储1这个bit了所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点(意思是要表示0-9必须最少要用4bit.),24bit就能使float能精确到小数点后6位(24/4=6),而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
好吧关于为什么指数要+127的问题,我也不知道.从网上找了段讲解粘贴在下方了,有机会再搞清楚吧:
书上说之所以要将指数加上 127 来得到阶码,是为了简化浮点数的比较运算,这一点我没有体会出来。但是通过 127 这个偏移量 (移码),可以区分出指数的正负。阶码为 127 时表示指数为 0;阶码小于 127 时表示负指数;阶码大于 127 时表示正指数。
那么继续看8.25和120.5的内存表示方法 8.25 == 1.0001 * 23


恩.以上基本就可以把float和double的东西搞得差不多了..
大牛还弄了个例子来说明把一个float赋值给double的话 double的值未必等于float..我们来看看吧
猜测一下下面的程序的输出结果是什么:
1 float f = 2.2f; 2 double d = (double)f; 3 Console.WriteLine(d.ToString("0.0000000000000")); 4 f = 2.25f; 5 d = (double)f; 6 Console.WriteLine(d.ToString("0.0000000000000"));
可能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?
首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0 100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,
ps: 先插入一个怎么把十进制小数转换成二进制的小数的方法---->
而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2=1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列 00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为: 2.2 == 10.00110011.... == 1.000110011... * 21 .所以指数是127+1=128

但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
恩,学习完了.附上原作者的链接 http://www.cnblogs.com/jillzhang/archive/2007/06/24/793901.html