最近接触的某个数据挖掘项目将近尾声(其实并没有……),客户开始关心模型最终部署的问题,希望将模型部署在巨硬云Azure上,他们定期上传数据,定期跑跑模型,得到预测即可。我觉得这应该挺简单的,客户把数据上传到某个文件夹里,我的程序直接读取就好啦,然后跑完模型结果保存在另一个文件夹里。结果客户说,我们的数据会上传到一个SFTP上,你得从那上面读取,这样的话我们可以随时换VM或者换SFTP,至于怎么实现你们自己搞定。
虽然客户的需求很有道理,但这让我有点懵逼了,感觉似乎变成了隔空取物,毕竟我没法直接在python里用os操作SFTP上的远程文件夹,也没法直接用pandas读取。不过幸好,我们有pysftp这个库。
pysftp这个库专门用于连接并操作SFTP,我们只需要提供SFTP的地址,用户名和密码,其他的基本跟os的操作一样了。此库安装也非常简单,直接pip install pysftp即可。
整体的思路非常简单,我们先来看看整个系统的流程:
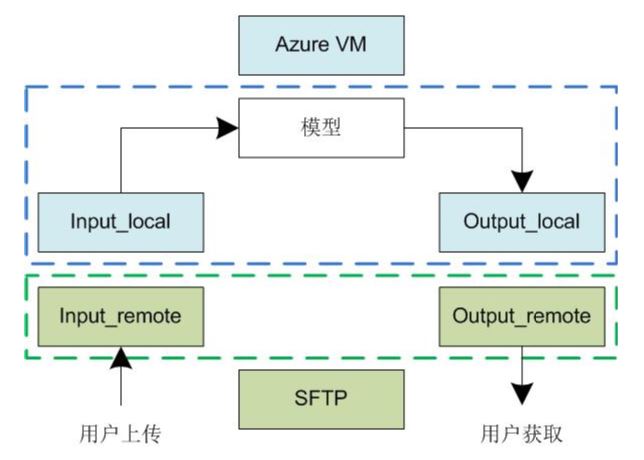
用户的数据上传至SFTP上的Input_remote文件夹,我们将其同步到Azure上的Input_local文件夹中。然后我们的模型从Input_local读取数据,运行,并将结果返回至Azure上的Output_local文件夹中。随后我们再将其推送至SFTP上的Output_remote文件夹,用户通过该文件夹获取。这样一来我们就实现了VM与SFTP的分离,两者随时想换就能换。
然后就是附上代码的环节了:
1. 导入库
import pysftp import os import warnings warnings.filterwarnings(action='ignore')
pysftp用于连接与操作SFTP,os用于操作VM上的本地文件。warnings仅用于过滤掉警告消息(强迫症患者)。
2. 远程文件同步到本地(SFTP -> VM)
cnopts = pysftp.CnOpts()
cnopts.hostkeys = None
with pysftp.Connection('***.com', username='******', password='******', cnopts=cnopts) as sftp:
sftp.chdir('./remote_folder') # 变更远程目标文件夹
print(sftp.listdir()) # 同步前文件夹的内容
print(os.listdir())
sftp.get_d(remotedir='./', localdir='./') # 远程同步到本地
print(sftp.listdir()) # 同步后文件夹的内容
print(os.listdir())
开头两行是连接选项,不加可能会报错。然后我们用with语句开启一个通往SFTP的连接,在pysftp.Connection中依次输入SFTP的连接地址、用户名和密码。使用with的好处是,当我们使用完毕时,会自动关掉这个连接。
我们在这里可以看到,pysftp的操作基本和os别无二致,非常简单,我们在这一步所做的就是:更改远程目标文件夹 -> 分别查看远程/本地文件夹的内容 -> 使用get_d从远程同步到本地 -> 再次查看远程/本地文件夹的内容。我们看一下结果:

可以看到我们把SFTP上的test1.csv同步到了本地。
3. 本地文件推送至远程(VM -> SFTP)
在这里,我们先把test1.csv改个名字,改成test2.csv,然后把这个文件推送到远程文件夹里。
os.rename('test1.csv', 'test2.csv')
with pysftp.Connection('***.com', username='******', password='******', cnopts=cnopts) as sftp:
sftp.chdir('./remote_folder') # 变更远程目标文件夹
print(sftp.listdir()) # 查看
print(os.listdir())
sftp.put('test2.csv') # 推送单个文件
print(sftp.listdir()) # 再次查看
print(os.listdir())
由于上次使用的with语句在执行结束后关闭了连接,因此我们在这里要重新变更远程目标文件夹,我们通过put命令将本地的test2.csv推送至远程文件夹,执行前后分别查看一下:

可以看到我们把VM上的test2.csv推送到了远程。如果我们想直接同步整个文件夹的内容的话,我们可以用put_d命令(跟get_d类似)。
通过上述简单的演示,我们基本上完成了一个最简易的SFTP-VM的数据打通环节,需要注意的是,同步与推送的过程中,新出现的文件总是会直接覆盖已存在的同名文件(overwrite),所以千万要注意不要一失足成千古恨。
此外,我们可以把同步与推送的过程写在一个with语句里,并把我们的模型打包嵌入进去,这样一来我们就基本完成了一个最简单的模型部署。