1.Scrapy整体框架
Scrapy采用了Twisted异步网络来处理请求,整体框架如下:
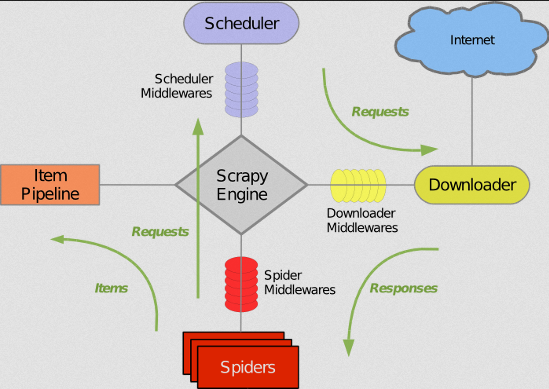
Scrapy Engine爬虫引擎:协调整个框架组件间的数据交互,是框架的核心
Schedule调度器:接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。(相当于需要爬取的url的集合)
Downloader下载器:下载指定的url的网页文本,并传递给spiders处理。
spiders 爬虫:处理爬取下来的网页文本,提取出所需要的信息。可以提取出数据Item,传递到Item Pipeline保存, 也可以提取出url,传递给Schedule的url任务队列。
Item Pipeline 项目管道: 接受spiders传递过来的数据Item,进行持久化。写入文件或数据库等。
Schedule Middleware 调度中间件:引擎和调度器之间的交互
Spider Middleware 爬虫中间件:引擎和爬虫之间的交互
Downloader Middleware下载器中间件:引擎和下载器之间的交互
一次完整的流程可以简单总结为:
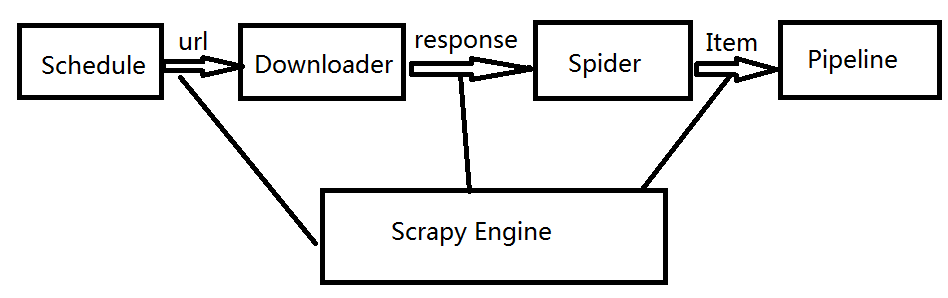
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy 代理)交给Downloader。
3.Downloader 向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders 处理response,提取数据并将数据经ScrapyEngine 交给ItemPipeline 保存(可以是本地,可以是数据库)。提取url 重新经ScrapyEngine 交给 Scheduler 进行下一个循环。直到无Url请求程序停止结束。
2,常用命令语句:
官方文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/commands.html
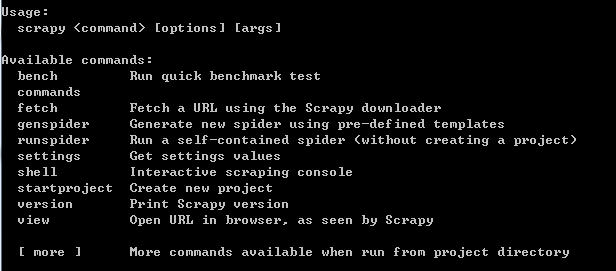
1 scrapy startproject project_name : 当前目录下创建爬虫项目
2 scrapy genspider [-t template] <spider_name> <domain> 根据模板创建爬虫应用(先进入创建的爬虫项目目录)
(模板有basic,crawl,csvfeed,xmlfeed,默认使用basic模板,scrapy genspider -t basic)
scrapy genspider -l :查看所有模板
scrapy genspider -d template_name : 查看模板名称
3 scrapy list 查看创建的所有爬虫应用
4 scrapy crawl spider_name 运行单独的爬虫应用
scrapy crawl spider_name --nolog 不显示多有的记录
3. 爬虫项目结构
创建后的爬虫项目目录如下:
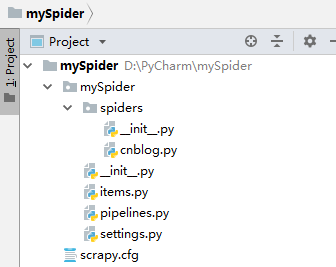
scrapy.cfg : 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py: 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines.py: 数据处理行为,如:一般结构化的数据持久化
settings.py: 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫应用目录,包含创建的所有爬虫应用(cnblog.py)
创建后的cnblog.py中代码如下
# -*- coding: utf-8 -*- import scrapy class CnblogSpider(scrapy.Spider): name = "cnblog" #爬虫应用名称 allowed_domains = ["cnblogs.com"] #限制爬虫域名,其他域名不爬取 start_urls = ( 'http://www.cnblogs.com/', # 爬虫起始url ) def parse(self, response): pass # 访问起始URL并获取结果后的回调函数, response为下载器返回的结果,response.text即网页文本
若windows输出编码乱码:UnicodeEncodeError: 'gbk' codec can't encode character u'xbb' (windows采用gbk,下载器下载的网页文本为unicode字符串),解决方案如下:
python 3:在代码前加入下面代码
import sys,io sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #gb18030可以兼容所有gb系列的编码,可以有效地避免少部分GBK无法解码的内容
python 2:输出文档时对文档格式进行设置
python 2 不支持sys.stdout.buffer,对于要打印的内容设置如下编码,:
print response.text.encode('gb18030')
4 选择器(Selector)
官方文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/selectors.html
构造选择器
from scrapy.selector import Selector from scrapy.http import HtmlResponse #通过Selector类 response = HtmlResponse(url='http://example.com', body=html_body) Selector(response=response).xpath() #通过selector属性,xpath(),css()方法 response.selector.xpath()
response.xpath()
response.css()
筛选表达式含义:
https://www.jianshu.com/p/2391950137a4
https://blog.csdn.net/manongpengzai/article/details/77109600
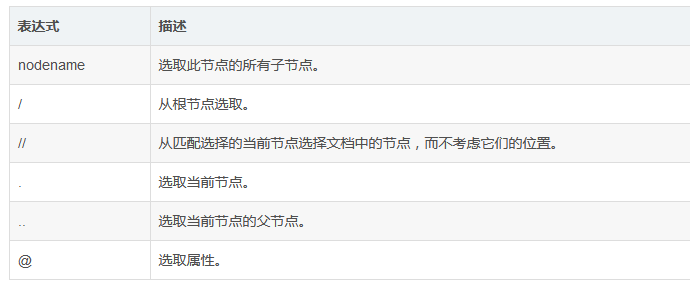
* 匹配任何元素节点
@* 匹配任何属性节点
node()匹配任何类型的节点
text()匹配文本值
extract()拿到对象中的字符窜
string()
# hxs = Selector(response=response).xpath('//a') # 选择文档中的所有a元素 # print(hxs) # hxs = Selector(response=response).xpath('//a[2]') # 选择文档中的第二个a元素 # print(hxs) # hxs = Selector(response=response).xpath('//a[@id]') #选择文档中的具有id属性的a元素 # print(hxs) # hxs = Selector(response=response).xpath('//a[@id="i1"]') #选择文档中的id=“i1”的a元素 # print(hxs) # hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]') # print(hxs) # hxs = Selector(response=response).xpath('//a[contains(@href, "link")]') #href属性值包含 “link” # print(hxs) # hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]') #href属性值以 “link”开始 # print(hxs) # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]') #正则表达式,id属性值 和“id+”进行匹配 # print(hxs) # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]/text()').extract() # 匹配的a元素的文本值 # print(hxs) # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]/@href').extract() # 匹配的a元素的href属性值 # print(hxs) # hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract() # 逐级查找 # print(hxs) # hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first() # 只返回第一个 # print(hxs) # ul_list = Selector(response=response).xpath('//body/ul/li') # for item in ul_list: # v = item.xpath('./a/span') # # 或 # # v = item.xpath('a/span') # # 或 # # v = item.xpath('*/a/span') # print(v)
4,实战项目
1,爬取博客园主页文章标题,并自动翻页


import scrapy from scrapy.http.request import Request class CnblogSpider(scrapy.Spider): name = "cnblog" allowed_domains = ["cnblogs.com"] start_urls = ( 'https://www.cnblogs.com/', ) has_request_set={} def parse(self, response): #print response.text.encode("gb18030") #print dir(response) page_title = response.xpath('//div[@class="post_item"]//h3/a/text()').extract_first() print response.url, page_title pager_list=response.xpath('//div[@class="pager"]/a/@href').extract() for item in pager_list: url = 'https://www.cnblogs.com/%s'%item import hashlib hash = hashlib.md5() hash.update(url) key = hash.hexdigest() #对url加密,方便比较,不访问重复的url if key in self.has_request_set: print u"已经下载了" #使用unicode时不乱码 else: self.has_request_set[key]=url yield Request(url=url,method='GET') # Request()中未设置callback=, 默认采用self.parse()处理返回response,即递归调用 # 在settings.py 中设置DEPTH_LIMIT=1 来设置递归调用的深度
2,利用cookie登陆抽屉热搜榜,实现批量点赞
import scrapy from scrapy.http.cookies import CookieJar from scrapy.http.request import Request #运行爬虫进行批量点赞前,在设置文件中设置DEPTH_LIMIT =4,不然递归次数多,太暴力了!!!!! class ChoutiSpider(scrapy.Spider): name = "chouti" allowed_domains = ["chouti.com"] start_urls = ( 'https://dig.chouti.com/', ) cookies_dict={} has_request_set={} #访问主页面,获取cookie def parse(self, response): cookie_jar = CookieJar() cookie_jar.extract_cookies(response, response.request) for k, v in cookie_jar._cookies.items(): for i, j in v.items(): for m,n in j.items(): self.cookies_dict[m]=n.value # n 为一个cookie实例对象 Cookie() #print n.value,type(n) #print self.cookies_dict #带着cookie去登陆,对cookie授权 url = "https://dig.chouti.com/login" yield Request( url=url, method='POST', headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}, #必须设置Content-Type,post提交的数据才能被正确处理 body='oneMonth=1&password=19930624&phone=8618626429847', cookies=self.cookies_dict, callback=self.check_login ) #拿着授权后的cookie去访问 def check_login(self,response): yield Request( url="https://dig.chouti.com/", method='GET', cookies=self.cookies_dict, callback=self.do_favor ) #进行批量点赞 def do_favor(self,response): linkid_list = response.xpath('//div[@share-linkid]/@share-linkid').extract() #print linkid user = response.xpath('//span[@id="userProNick"]/text()').extract() #print user for id in linkid_list: url = "https://dig.chouti.com/link/vote?linksId=%s"%id yield Request( url=url, method='POST', cookies=self.cookies_dict, callback=self.show_favor ) # 拿到页码,自动翻页 pager_list = response.xpath('//div[@id="dig_lcpage"]/ul/li/a/@href').extract() #print pager_list for page in pager_list: page_url = "https://dig.chouti.com%s"%page import hashlib hash = hashlib.md5() hash.update(page_url) key = hash.hexdigest() if key in self.has_request_set.keys(): pass else: self.has_request_set[key]=page_url #print page_url yield Request( url=page_url, method='GET', cookies=self.cookies_dict, callback=self.do_favor # 递归调用,从而对每一页进行点赞; ) #打印点赞后的返回结果:推荐成功 def show_favor(self,response): print response.text
5,数据格式化处理
对于上面实例的数据可以在parse中简单处理,但若要进行数据格式化和持久化,可以用items格式化数据,并交给pipeline处理。
items
items官方文档:https://doc.scrapy.org/en/latest/topics/items.html
Item的定义类似django中的model,每个Item对象有若干属性,其使用起来和dict很相似,并可以与dict互相转换
Creating Item >>> product = Product(name='Desktop PC', price=1000) >>> print product Product(name='Desktop PC', price=1000) Getting Field >>> product['name'] Desktop PC >>> product.get('name') Desktop PC Setting Field >>> product['last_updated'] = 'today' >>> product['last_updated'] today Creating dicts from items: >>> dict(product) # create a dict from all populated values {'price': 1000, 'name': 'Desktop PC'} Creating items from dicts >>> Product({'name': 'Laptop PC', 'price': 1500}) Product(price=1500, name='Laptop PC')
pipeline
pipeline官方文档:https://doc.scrapy.org/en/latest/topics/item-pipeline.html
通过语句yield item,会将item传递给pipeline中定义的process_item()方法处理,根据在settings中设置的权重不同,各个pipeline类的process_item()方法会依次执行(若process_item()未return item,该item会被丢弃,不会向一个pipeline类的process_item()方法传递)。除了process_item()方法外,pipeline还可以实现其他的方法,如下:
from scrapy.exceptions import DropItem class CustomPipeline(object): def __init__(self,v): self.value = v def process_item(self, item, spider): # 操作并进行持久化 # return表示会被后续的pipeline继续处理 return item # 表示将item丢弃,不会被后续pipeline处理 # raise DropItem() @classmethod def from_crawler(cls, crawler): """ 初始化时候,用于创建pipeline对象 :param crawler: :return: """ val = crawler.settings.getint('MMMM') return cls(val) def open_spider(self,spider): """ 爬虫开始执行时,调用 :param spider: :return: """ print('000000') def close_spider(self,spider): """ 爬虫关闭时,被调用 :param spider: :return: """ print('111111')
爬取链家房产信息,并保存:
# -*- coding: utf-8 -*- import scrapy from ..items import LianjiaItem from scrapy.http.request import Request import json class LianjiaSpider(scrapy.Spider): name = "lianjia" allowed_domains = ["lianjia.com"] start_urls = ( 'http://wh.lianjia.com/ershoufang/', ) has_request_set={} def parse(self, response): sell_list = response.xpath('//ul[@class="sellListContent"]/li') #print sell_list for item in sell_list: img_src = item.xpath('./a/img[@class="lj-lazy"]/@data-original').extract_first() #不要爬取src属性,得到的为空图片 house_name =item.xpath('.//div[@class="houseInfo"]/a/text()').extract_first() house_desc = item.xpath('.//div[@class="houseInfo"]/text()').extract_first() total_price = item.xpath('.//div[@class="totalPrice"]/span/text()').extract_first() unit_price = item.xpath('.//div[@class="unitPrice"]/span/text()').extract_first() house_item = LianjiaItem(img_src=img_src,house_name=house_name, house_desc=house_desc,total_price=total_price,unit_price=unit_price) yield house_item #无法从返回的页面中拿到分页页码,只能拿到总页码数? pager_data = response.xpath('//div[@comp-module="page"]/@page-data').extract() #print pager_data total_page = json.loads(pager_data[0])["totalPage"] #for i in range(2,total_page) for i in range(2,4): #只爬取第2,3页 page_url="https://wh.lianjia.com/ershoufang/pg%s/"%i yield Request(url=page_url,callback=self.parse)
import scrapy class LianjiaItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() img_src = scrapy.Field() house_name = scrapy.Field() house_desc = scrapy.Field() total_price= scrapy.Field() unit_price = scrapy.Field()
import json import requests import os class LianjiaPipeline(object): def __init__(self): self.file=open('lianjia.txt','a') #在当前路径下创建文件并追加内容 def process_item(self, item, spider): if item['house_name']: data= json.dumps(dict(item),ensure_ascii=False).encode("utf8")+" " self.file.write(data) self.file.close() return item class ImgPipeline(object): def __init__(self): if not os.path.exists('images'): #当前路径不存在文件夹时创建文件夹 os.mkdir('images') def process_item(self,item, spider): response = requests.get(item['img_src'], stream=True) #stream=True边下载边从内存保存到硬盘,而不是全部下载到内存 file_name=u'%s_%s万.jpg'%(item['house_name'],item['total_price']) with open(os.path.join('images',file_name),'wb') as f: f.write(response.content) return item
ITEM_PIPELINES = { 'mySpider.pipelines.LianjiaPipeline': 100, 'mySpider.pipelines.ImgPipeline': 200, } # 值为0-1000,数字越小,优先度越高,先执行其process_item()方法
6. 中间件
spider Middleware 爬虫中间件: 介于引擎和爬虫之间,自定义爬虫中间件类,实现相应的方法,在settings中设置即可。数字越小越靠近引擎,process_spider_input()优先处理,数字越大越靠近spider,process_spider_output()优先处理,关闭用None。
官方文档:https://scrapy.readthedocs.io/en/latest/topics/spider-middleware.html
https://zhuanlan.zhihu.com/p/42498126
class SpiderMiddleware(object): def process_spider_input(self,response, spider): """ 从引擎传来的response,先在这里处理,然后交给spider :param response: :param spider: :return: """ pass def process_spider_output(self,response, result, spider): """ spider处理完成,返回结果时调用 (返回的结果在这里处理,后传给引擎) :param response: :param result: :param spider: :return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable) """ return result def process_spider_exception(self,response, exception, spider): """ 异常调用 :param response: :param exception: :param spider: :return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline """ return None def process_start_requests(self,start_requests, spider): """ 爬虫启动时调用 :param start_requests: :param spider: :return: 包含 Request 对象的可迭代对象 """ return start_requests
SPIDER_MIDDLEWARES = { 'mySpider.middlewares.MyCustomSpiderMiddleware': 543, } # 会与 SPIDER_MIDDLEWARES_BASE中的中间件合并,根据权重,依次执行; ''' SPIDER_MIDDLEWARES_BASE= { 'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50, 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500, 'scrapy.spidermiddlewares.referer.RefererMiddleware': 700, 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800, 'scrapy.spidermiddlewares.depth.DepthMiddleware': 900, } '''
download Middleware 下载器中间件:介于引擎和下载器之间,需要自定义和设置,数字越小,越靠近引擎,数字越大越靠近下载器。数字越小的,process_request()优先处理;数字越大的,process_response()优先处理;若需要关闭某个中间件直接设为None即可
DOWNLOADER_MIDDLEWARES = { 'mySpider.middlewares.MyCustomDownloaderMiddleware': 543, } #设置后会和DOWNLOADER_MIDDLEWARES_BASE合并,根据权重依次执行 ''' DOWNLOADER_MIDDLEWARES_BASE= { 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300, 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350, 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400, 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500, 'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550, 'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560, 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590, 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600, 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700, 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750, 'scrapy.downloadermiddlewares.stats.DownloaderStats': 850, 'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900, } '''
class DownMiddleware1(object): def process_request(self, request, spider): """ 从引擎传来的request,经过所有下载器中间件的process_request调用 :param request: :param spider: :return: None,继续后续中间件去下载; Response对象,停止process_request的执行,开始执行process_response Request对象,停止中间件的执行,将Request重新调度器 raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception """ pass def process_response(self, request, response, spider): """ 下载器处理完成返回的response,经过所有下载器中间件的process_response :param response: :param result: :param spider: :return: Response 对象:转交给其他中间件process_response Request 对象:停止中间件,request会被重新调度下载 raise IgnoreRequest 异常:调用Request.errback """ print('response1') return response def process_exception(self, request, exception, spider): """ 当下载处理器(download handler)或 process_request() (下载中间件)抛出异常 :param response: :param exception: :param spider: :return: None:继续交给后续中间件处理异常; Response对象:停止后续process_exception方法 Request对象:停止中间件,request将会被重新调用下载 """ return None from_crawler(cls, crawler): # 利用crawler创建中间件实例 return
7. 自定义命令
官方文档:https://doc.scrapy.org/en/latest/topics/commands.html?highlight=COMMANDS_MODULE
在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称
8. 信号机制
官方文档:https://scrapy.readthedocs.io/en/latest/topics/signals.html
scrapy中设置了很多信号,在特定事情发生时会被调用,可以自定义相应的处理函数
from scrapy import signals class MyExtension(object): def __init__(self, value): self.value = value @classmethod def from_crawler(cls, crawler): val = crawler.settings.getint('MMMM') ext = cls(val) crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened) crawler.signals.connect(ext.spider_closed, signal=signals.spider_closed) return ext def spider_opened(self, spider): print('open') def spider_closed(self, spider): print('close')
from scrapy import signals from scrapy import Spider class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/", ] @classmethod def from_crawler(cls, crawler, *args, **kwargs): spider = super(DmozSpider, cls).from_crawler(crawler, *args, **kwargs) crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed) return spider def spider_closed(self, spider): spider.logger.info('Spider closed: %s', spider.name) def parse(self, response): pass
9.url去重设置
官方文档:https://doc.scrapy.org/en/latest/topics/settings.html?highlight=DUPEFILTER_CLASS
DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' :默认处理重复请求的类
DUPEFILTER_DEBUG = False #RFPDupeFilter默认为False,只记录第一个重复的request。设置True时记录所有的
dont_filter=True),该Request的url不被去重
class RepeatUrl: def __init__(self): self.visited_url = set() @classmethod def from_settings(cls, settings): """ 初始化时,调用 :param settings: :return: """ return cls() def request_seen(self, request): """ 检测当前请求是否已经被访问过 :param request: :return: True表示已经访问过;False表示未访问过 """ if request.url in self.visited_url: return True self.visited_url.add(request.url) return False def open(self): """ 开始爬去请求时,调用 :return: """ print('open replication') def close(self, reason): """ 结束爬虫爬取时,调用 :param reason: :return: """ print('close replication') def log(self, request, spider): """ 记录日志 :param request: :param spider: :return: """ print('repeat', request.url) 复制代码
10. settings各项含义
1. 爬虫名称 BOT_NAME = 'step8_king' # 2. 爬虫应用路径 SPIDER_MODULES = ['step8_king.spiders'] NEWSPIDER_MODULE = 'step8_king.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent # 3. 客户端 user-agent请求头 # USER_AGENT = 'step8_king (+http://www.yourdomain.com)' # Obey robots.txt rules # 4. 禁止爬虫配置 # ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) # 5. 并发请求数 # CONCURRENT_REQUESTS = 4 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # 6. 延迟下载秒数 # DOWNLOAD_DELAY = 2 # The download delay setting will honor only one of: # 7. 单域名访问并发数,并且延迟下次秒数也应用在每个域名 # CONCURRENT_REQUESTS_PER_DOMAIN = 2 # 单IP访问并发数,如果有值则忽略:CONCURRENT_REQUESTS_PER_DOMAIN,并且延迟下次秒数也应用在每个IP # CONCURRENT_REQUESTS_PER_IP = 3 # Disable cookies (enabled by default) # 8. 是否支持cookie,cookiejar进行操作cookie # COOKIES_ENABLED = True # COOKIES_DEBUG = True # Disable Telnet Console (enabled by default) # 9. Telnet用于查看当前爬虫的信息,操作爬虫等... # 使用telnet ip port ,然后通过命令操作 # TELNETCONSOLE_ENABLED = True # TELNETCONSOLE_HOST = '127.0.0.1' # TELNETCONSOLE_PORT = [6023,] # 10. 默认请求头 # Override the default request headers: # DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', # } # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html # 11. 定义pipeline处理请求 # ITEM_PIPELINES = { # 'step8_king.pipelines.JsonPipeline': 700, # 'step8_king.pipelines.FilePipeline': 500, # } # 12. 自定义扩展,基于信号进行调用 # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html # EXTENSIONS = { # # 'step8_king.extensions.MyExtension': 500, # } # 13. 爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度 # DEPTH_LIMIT = 3 # 14. 爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo # 后进先出,深度优先 # DEPTH_PRIORITY = 0 # SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue' # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue' # 先进先出,广度优先 # DEPTH_PRIORITY = 1 # SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue' # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue' # 15. 调度器队列 # SCHEDULER = 'scrapy.core.scheduler.Scheduler' # from scrapy.core.scheduler import Scheduler # 16. 访问URL去重 # DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl' # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html """ 17. 自动限速算法 from scrapy.contrib.throttle import AutoThrottle 自动限速设置 1. 获取最小延迟 DOWNLOAD_DELAY 2. 获取最大延迟 AUTOTHROTTLE_MAX_DELAY 3. 设置初始下载延迟 AUTOTHROTTLE_START_DELAY 4. 当请求下载完成后,获取其"连接"时间 latency,即:请求连接到接受到响应头之间的时间 5. 用于计算的... AUTOTHROTTLE_TARGET_CONCURRENCY target_delay = latency / self.target_concurrency new_delay = (slot.delay + target_delay) / 2.0 # 表示上一次的延迟时间 new_delay = max(target_delay, new_delay) new_delay = min(max(self.mindelay, new_delay), self.maxdelay) slot.delay = new_delay """ # 开始自动限速 # AUTOTHROTTLE_ENABLED = True # The initial download delay # 初始下载延迟 # AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies # 最大下载延迟 # AUTOTHROTTLE_MAX_DELAY = 10 # The average number of requests Scrapy should be sending in parallel to each remote server # 平均每秒并发数 # AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: # 是否显示 # AUTOTHROTTLE_DEBUG = True # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings """ 18. 启用缓存 目的用于将已经发送的请求或相应缓存下来,以便以后使用 from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware from scrapy.extensions.httpcache import DummyPolicy from scrapy.extensions.httpcache import FilesystemCacheStorage """ # 是否启用缓存策略 # HTTPCACHE_ENABLED = True # 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可 # HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy" # 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略 # HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy" # 缓存超时时间 # HTTPCACHE_EXPIRATION_SECS = 0 # 缓存保存路径 # HTTPCACHE_DIR = 'httpcache' # 缓存忽略的Http状态码 # HTTPCACHE_IGNORE_HTTP_CODES = [] # 缓存存储的插件 # HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' """ 19. 代理,需要在环境变量中设置 from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware 方式一:使用默认 os.environ { http_proxy:http://root:woshiniba@192.168.11.11:9999/ https_proxy:http://192.168.11.11:9999/ } 方式二:使用自定义下载中间件 def to_bytes(text, encoding=None, errors='strict'): if isinstance(text, bytes): return text if not isinstance(text, six.string_types): raise TypeError('to_bytes must receive a unicode, str or bytes ' 'object, got %s' % type(text).__name__) if encoding is None: encoding = 'utf-8' return text.encode(encoding, errors) class ProxyMiddleware(object): def process_request(self, request, spider): PROXIES = [ {'ip_port': '111.11.228.75:80', 'user_pass': ''}, {'ip_port': '120.198.243.22:80', 'user_pass': ''}, {'ip_port': '111.8.60.9:8123', 'user_pass': ''}, {'ip_port': '101.71.27.120:80', 'user_pass': ''}, {'ip_port': '122.96.59.104:80', 'user_pass': ''}, {'ip_port': '122.224.249.122:8088', 'user_pass': ''}, ] proxy = random.choice(PROXIES) if proxy['user_pass'] is not None: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass'])) request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass) print "**************ProxyMiddleware have pass************" + proxy['ip_port'] else: print "**************ProxyMiddleware no pass************" + proxy['ip_port'] request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) DOWNLOADER_MIDDLEWARES = { 'step8_king.middlewares.ProxyMiddleware': 500, } """ """ 20. Https访问 Https访问时有两种情况: 1. 要爬取网站使用的可信任证书(默认支持) DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapy.core.downloader.contextfactory.ScrapyClientContextFactory" 2. 要爬取网站使用的自定义证书 DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "step8_king.https.MySSLFactory" # https.py from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory from twisted.internet.ssl import (optionsForClientTLS, CertificateOptions, PrivateCertificate) class MySSLFactory(ScrapyClientContextFactory): def getCertificateOptions(self): from OpenSSL import crypto v1 = crypto.load_privatekey(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.key.unsecure', mode='r').read()) v2 = crypto.load_certificate(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.pem', mode='r').read()) return CertificateOptions( privateKey=v1, # pKey对象 certificate=v2, # X509对象 verify=False, method=getattr(self, 'method', getattr(self, '_ssl_method', None)) ) 其他: 相关类 scrapy.core.downloader.handlers.http.HttpDownloadHandler scrapy.core.downloader.webclient.ScrapyHTTPClientFactory scrapy.core.downloader.contextfactory.ScrapyClientContextFactory 相关配置 DOWNLOADER_HTTPCLIENTFACTORY DOWNLOADER_CLIENTCONTEXTFACTORY """ """ 21. 爬虫中间件 class SpiderMiddleware(object): def process_spider_input(self,response, spider): ''' 下载完成,执行,然后交给parse处理 :param response: :param spider: :return: ''' pass def process_spider_output(self,response, result, spider): ''' spider处理完成,返回时调用 :param response: :param result: :param spider: :return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable) ''' return result def process_spider_exception(self,response, exception, spider): ''' 异常调用 :param response: :param exception: :param spider: :return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline ''' return None def process_start_requests(self,start_requests, spider): ''' 爬虫启动时调用 :param start_requests: :param spider: :return: 包含 Request 对象的可迭代对象 ''' return start_requests 内置爬虫中间件: 'scrapy.contrib.spidermiddleware.httperror.HttpErrorMiddleware': 50, 'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': 500, 'scrapy.contrib.spidermiddleware.referer.RefererMiddleware': 700, 'scrapy.contrib.spidermiddleware.urllength.UrlLengthMiddleware': 800, 'scrapy.contrib.spidermiddleware.depth.DepthMiddleware': 900, """ # from scrapy.contrib.spidermiddleware.referer import RefererMiddleware # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html SPIDER_MIDDLEWARES = { # 'step8_king.middlewares.SpiderMiddleware': 543, } """ 22. 下载中间件 class DownMiddleware1(object): def process_request(self, request, spider): ''' 请求需要被下载时,经过所有下载器中间件的process_request调用 :param request: :param spider: :return: None,继续后续中间件去下载; Response对象,停止process_request的执行,开始执行process_response Request对象,停止中间件的执行,将Request重新调度器 raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception ''' pass def process_response(self, request, response, spider): ''' spider处理完成,返回时调用 :param response: :param result: :param spider: :return: Response 对象:转交给其他中间件process_response Request 对象:停止中间件,request会被重新调度下载 raise IgnoreRequest 异常:调用Request.errback ''' print('response1') return response def process_exception(self, request, exception, spider): ''' 当下载处理器(download handler)或 process_request() (下载中间件)抛出异常 :param response: :param exception: :param spider: :return: None:继续交给后续中间件处理异常; Response对象:停止后续process_exception方法 Request对象:停止中间件,request将会被重新调用下载 ''' return None 默认下载中间件 { 'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300, 'scrapy.contrib.downloadermiddleware.downloadtimeout.DownloadTimeoutMiddleware': 350, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400, 'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500, 'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550, 'scrapy.contrib.downloadermiddleware.redirect.MetaRefreshMiddleware': 580, 'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 590, 'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600, 'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750, 'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830, 'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850, 'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900, } """ # from scrapy.contrib.downloadermiddleware.httpauth import HttpAuthMiddleware # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # DOWNLOADER_MIDDLEWARES = { # 'step8_king.middlewares.DownMiddleware1': 100, # 'step8_king.middlewares.DownMiddleware2': 500, # }
11. 自定义简单版scrapy框架
准备知识:Twisted中reactor, defer, deferredlist, inlineCallback, getpage,参考https://www.cnblogs.com/silence-cho/p/9898984.html
项目架构及代码:
#coding:utf-8 from twisted.web.client import defer,getPage from twisted.internet import reactor from Queue import Queue class Request(object): def __init__(self,url,callback): self.url = url self.callback = callback class HttpResponse(object): def __init__(self,content,request): self.response = content self.request = request @property def text(self): return self.response class Scheduler(object): def __init__(self): self.q = Queue() def open(self): pass def enqueue_request(self,req): self.q.put(req) def next_request(self): try: req = self.q.get(block=False) except Exception as e: req = None return req def size(self): return self.q.qsize() class ExecutionEngine(object): def __init__(self): self._close = None self.scheduler = None self.max = 5 self.crawling = [] def get_response_callback(self,content,request): print request.url # print self.crawling self.crawling.remove(request) # print self.crawling response = HttpResponse(content,request) result = request.callback(response) import types if isinstance(result,types.GeneratorType): for req in result: self.scheduler.enqueue_request(req) def _next_request(self): if self.scheduler.size()==0 and len(self.crawling)==0: self._close.callback(None) return while len(self.crawling) < self.max: req = self.scheduler.next_request() if not req: return #print req.url self.crawling.append(req) #print self.crawling d = getPage(req.url.encode('utf-8')) d.addCallback(self.get_response_callback,req) d.addCallback(lambda _:reactor.callLater(0,self._next_request)) @defer.inlineCallbacks def open_spider(self,start_requests): self.scheduler = Scheduler() yield self.scheduler.open() while True: try: req = next(start_requests) self.scheduler.enqueue_request(req) except StopIteration as e: break reactor.callLater(0, self._next_request) @defer.inlineCallbacks def start(self): self._close = defer.Deferred() yield self._close class Crawler(object): def __init__(self,spider_cls_path): self.spider_cls_path = spider_cls_path def _create_engine(self): return ExecutionEngine() def _create_spider(self): module_path, cls_name = self.spider_cls_path.rsplit('.',1) import importlib module = importlib.import_module(module_path) cls = getattr(module,cls_name) #print cls,'----' return cls() @defer.inlineCallbacks def crawl(self): spider = self._create_spider() start_requests = iter(spider.start_request()) engine = self._create_engine() yield engine.open_spider(start_requests) yield engine.start() class CrawlProcess(object): def __init__(self): self.active = set() def crawl(self,spider_cls_path): crawler =Crawler(spider_cls_path) d=crawler.crawl() self.active.add(d) def start(self): dd=defer.DeferredList(self.active) dd.addBoth(lambda _:reactor.stop()) reactor.run() class Command(object): def run(self): spider_cls_paths=['spider.chouti.ChoutiSpider','spider.cnblogs.CnblogsSpider'] #'spider.cnblogs.CnblogsSpider' crawlProcess = CrawlProcess() for spider_cls_path in spider_cls_paths: crawlProcess.crawl(spider_cls_path) crawlProcess.start() if __name__ == '__main__': c = Command() c.run()
#coding:utf-8 from engine import Request class CnblogsSpider(object): name = 'Cnblogs' def start_request(self): start_url = ['https://www.cnblogs.com/','https://www.baidu.com/' ] #'https://www.baidu.com/' for url in start_url: yield Request(url, self.parse) def parse(self, response): print response #print response.text
#coding:utf-8 from engine import Request class ChoutiSpider(object): name = 'chouti' def start_request(self): start_url = ['https://dig.chouti.com/','https://www.baidu.com/'] for url in start_url: yield Request(url, self.parse) def parse(self,response): #print response yield Request('https://www.sina.com.cn/',self.call) #print response.text def call(self,response): print '爬取新浪'
参考博客:http://www.cnblogs.com/wupeiqi/articles/6229292.html