一,id,is,==
在Python中,id是什么?id是内存地址,比如你利用id()内置函数去查询一个数据的内存地址:
name="guohui" print(id(name)) #2505979012296
那么 is 是什么? == 又是什么?
== 是比较的两边的数值是否相等,而 is 是比较的两边的内存地址是否相等。 如果内存地址相等,那么这两边其实是指向同一个内存地址。


可以说如果内存地址相同,那么值肯定相同,但是如果值相同,内存地址不一定相同。
代码块
Python程序是由代码块构造的。块是一个python程序的文本,他是作为一个单元执行的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
什么叫交互方式?就是咱们在cmd中进入Python解释器里面,每一行代码都是一个代码块,例如:

而对于一个文件中的两个函数,也分别是两个不同的代码块:

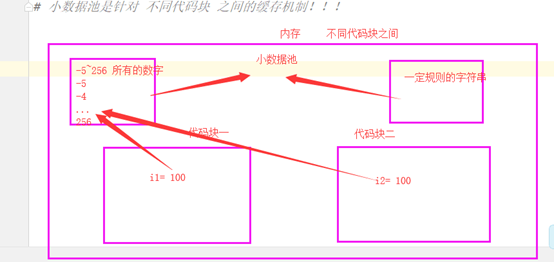
代码块的缓存机制
Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。
代码块的缓存机制的适用范围: int(float),str,bool。
int(float):任何数字在同一代码块下都会复用。
bool:True和False在字典中会以1,0方式存在,并且复用。
str:几乎所有的字符串都会符合缓存机制,具体规定如下(了解即可!):
那么对于字符串的规定呢?
str:字符串要从下面这几个大方向讨论(了解即可!):
1,字符串的长度为0或者1,默认都采用了驻留机制(小数据池)。

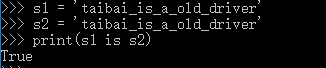
2,字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留。
3,用乘法得到的字符串,分两种情况。
3.1 乘数为1时:
仅含大小写字母,数字,下划线,默认驻留。

含其他字符,长度<=1,默认驻留。
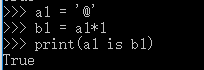
含其他字符,长度>1,默认驻留。
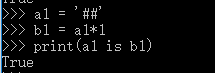
3.2 乘数>=2时:
仅含大小写字母,数字,下划线,总长度<=20,默认驻留。
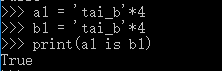
满足以上字符串的规则时,就符合小数据池的概念。
bool值就是True,False,无论你创建多少个变量指向True,False,那么他在内存中只存在一个。
看一下用了小数据池(驻留机制)的效率有多高:
显而易见,节省大量内存在字符串比较时,非驻留比较效率o(n),驻留时比较效率o(1)。
4,指定驻留。
from sys import intern a = intern('hello!@'*20) b = intern('hello!@'*20) print(a is b) #指定驻留是你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串。
集合
字典特点:
1.key是唯一的. 2.key必须是可以哈希的(不可变数据类型:字符串,元组,数值) 3.key是无序的. 3.6中dict的元素有序是解释器的特点,不是python源码的特点. xxx.py Cpython -> 有序 Jpython -> 无序
实际上就是一种特殊的字典.
所有value都是None的字典,就是集合.
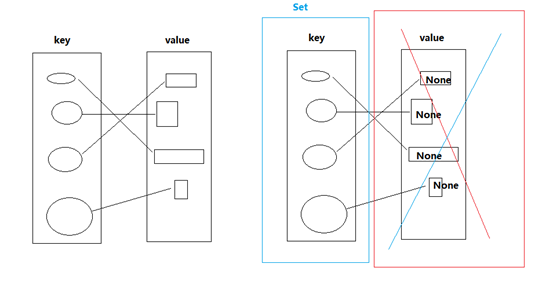
对比字典和集合的特点:

集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
如何获取集合?
1.手动创建集合. 1.创建空集合 d = {} 创建空集合,只有一种方式:调用set函数. S = set() 2.创建带元素集合 S = {1,2,3} 从可迭代对象中(字符串,列表,元组,字典)创建集合. s = set(‘abc’) S = set([1,2,3]) S = set((1,2,3)) S = set({‘name’:’Andy’,’age’:10}) 2.通过方法调用 -> str -> list -> set
集合的操作:
查看集合可用的方法: [x for x in dir(set) if not x.startswith(‘_’)] 增: add:如果元素存在,没有做任何动作. 删: Pop() :依次从集合中弹出一个元素,如果集合为空,报错 Discard(ele) :从集合中删除指定的元素,如果不存在,什么都不执行 Remove(ele) :从集合中删除指定的元素,如果不存在,报错 Clear() :清空
改(更新):
Update :用二者的并集更新当前集合
difference_update:用二者的差集更新当前集合
intersection_update:用二者的交集更新当前集合
symmetric_difference_update:用二者的对称差集更新当前集合
判断功能:
Isdisjoint:判断两个集合是否没有交集
Issubset:判断当前集合是否是后者的子集
Issuperset:判断后者是否是当前集合的子集
查
集合基本没有单独取其中元素的需求.
集合的四大常用操作:
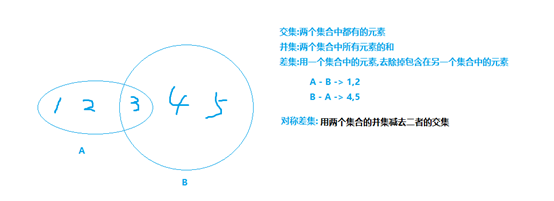
并集:union
交集:intersection
差集:difference
对称差:symmetric_difference
集合的使用场景:
1.判断一个元素是否在指定的范围之内. 2.方便数学上的集合操作. 并,交,差,对称差 有简化写法: 并:| 交:& 差:- 对称差:^ 3.对序列数据类型中的重复元素进行去重 如果想遍历集合中的元素. 通常用for循环.
frozenset:冻结的集合 最大的特点:不可变. ['copy', 'difference', 'intersection', 'isdisjoint', 'issubset', 'issuperset', 'symmetric_difference', 'union'] 少了添加,更新的方法. s = frozenset() s = frozenset('abcabc') s = frozenset([1,2,3]) s = frozenset((1,2,3)) s = frozenset({'name':'Andy','age':10}) 集合的四大方法:并,交,差,对称差. set,frozenset是否可以混用? 可以! 总结: 如果两种数据类型混用,方法的主调者的类型决定了最终结果的类型.