redis:存储中间键-----remote dictionary service(远程字典服务)
相对于Memcache,redis更加容易理解、使用和控制
分布锁:很重要
redis可以干什么:
- 记录帖子的点赞数、评论数和点击数(hash)
- 记录用户的帖子ID列表,便于快速显示用户的帖子列表(zset)
- 记录帖子的标题、摘要、作者和封面信息、用于列表页的展示(hash)
- 记录帖子的点赞用户ID列表、评论ID列表、用于显示和去重技术(zset)
- 等等。。。
请求压力不打的情况下,很多数据都是直接从数据库中查询。但是如果请求压力很大,以前通过数据库直接存取的数据则必须挪到缓存中操作
redis基础数据结构
基本是在Linux和Mac环境下安装
所有的数据结构都是Key-Value结构,以下讲的基础数据结构都是Value
公共指令:
# 判断是否存在key这个键 exists key #删除key这个值 del key #设置过期时间(单位秒) expire key 2
String
底层是一个变长的数据存储的。
用途:缓存用户的基本信息。Json将用户信息序列化成字符串,然后塞进redis中存储
数组实际长度大于字符串的实际长度,方便扩充;假如不够了,那就double扩容,假如扩容到了1MB,那就不再double了,每次扩容直接+1MB
一些常见的指令:
# 增加一个Key=name;Value=li的存储变量 set name li #追加 append name si #获取 get name #集体添加 mset name li age 1 gender male #集体获取 mget name age gender
#假如value是一个数字,可以增加一个随意数
incrby age 5;
#假如value是一个数字,那么自增1,但是数字是有最大值和最小值的哦
incr age
List
双向列表
用途:做消息队列
简单指令
# 从右端开始作业 rpush list-name value rpop list_name # 从左端开始作业 lpush list_name value lpop list_name value #通过下表获得指定元素,下边这东西,只能从左到右,符合常理 lindex list_name 1 #获取下标范围的元素,-1指的是末尾元素,下标从0开始 lrange list_name 1 -1 #范围保留,除了这个范围内的元素全部删除掉 ltrim 1 -1
至于越界,哈哈哈,自己试试吧。----是没问题的,查多少算多少
至于左边大于右边界:都查不出来的。
底层结构:quickList
一个一个的连续区域块组成,连续区域快叫做zipList
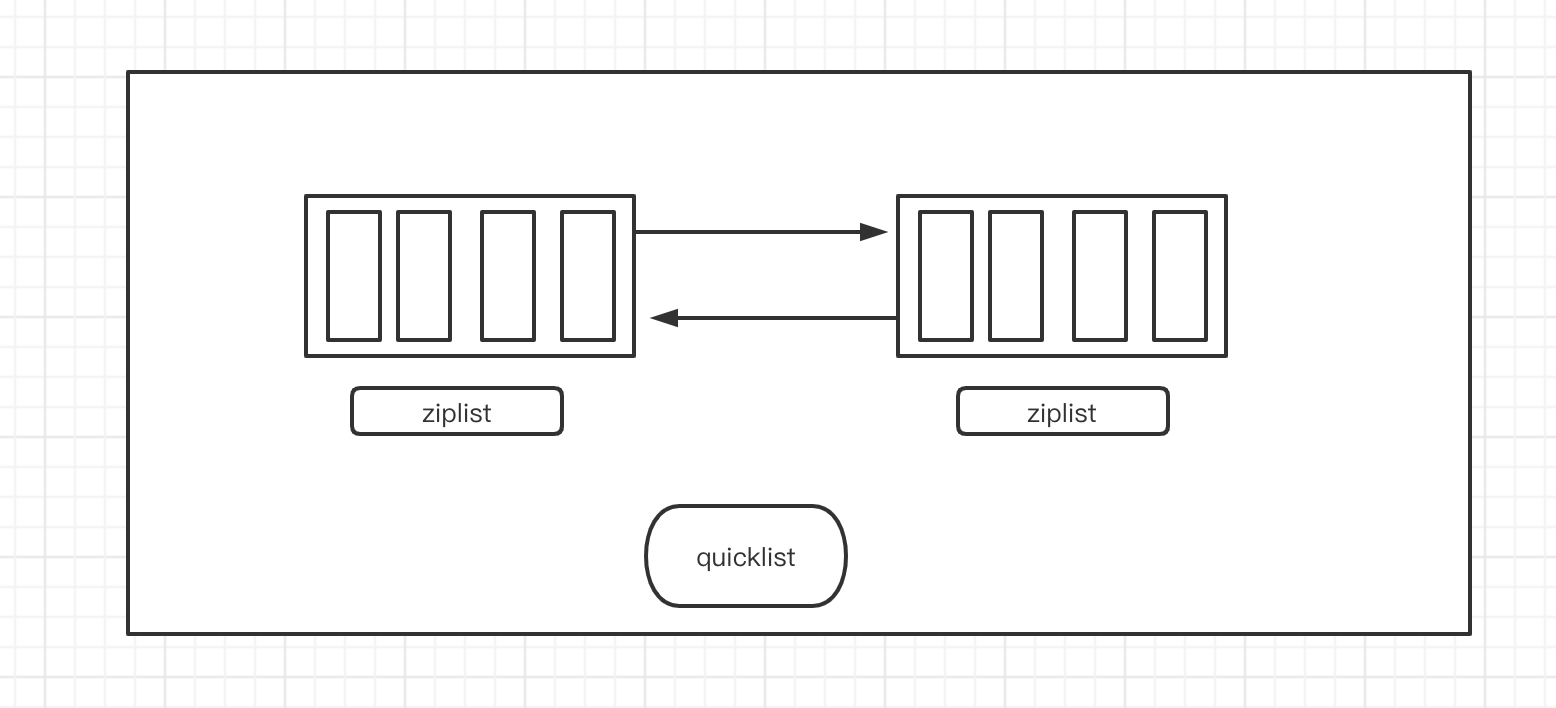
假如list存储的是数字,假如用单纯的链表存储,太浪费空间了,因为包含两个指针,所以用这种存储就节省空间
hash
跟hashMap差不多,但是这里的key必须是字符串。
扩容、或者缩容时也与hashmap不一样
渐进式rehash:会保留新旧两个hash结构,慢慢的搬运,直至完成,删除旧hash
当hash移除了最后一个元素后,该数据结构会自动删除,内存被回收
常见指令:
# 设置hash hset books java "think in java" #统一设置 hmset books java one python two #获取 hget books java #统一获取 hgetall books #查询长度 hlen books #增长int类型 hincrby books age 10
set
无序不重复,内部是hash实现,value为null
最后一个元素移除之后,数据结构被自动删除
常用指令
sadd books java
sadd books java python # java插入不进去,但是python会插入进去
smember books #查看所有的books内容
sismember books java #假如java在里面就会返回1,不在返回0
scard books #查看books的长度
zset
set的升级版本,有序无重复的set,底层是hash实现,value是分数,用于比较。
跳跃列表
最后一个value被删除之后,数据结构会被自动删除,内存被回收
/* score必须是浮点数,排序是从小到大排列 */ zadd books 9 java zadd books 9 python zadd books 8 go /* 范围取值 */ zrange books 0 1 /* zrevrange:先将zset反转之后再按照zrange的方式取值 */ zrevreange books 0 1 /* zcard :算集合中的个数 */ zcard books /* zrem,移除那些元素 */ zrem books java
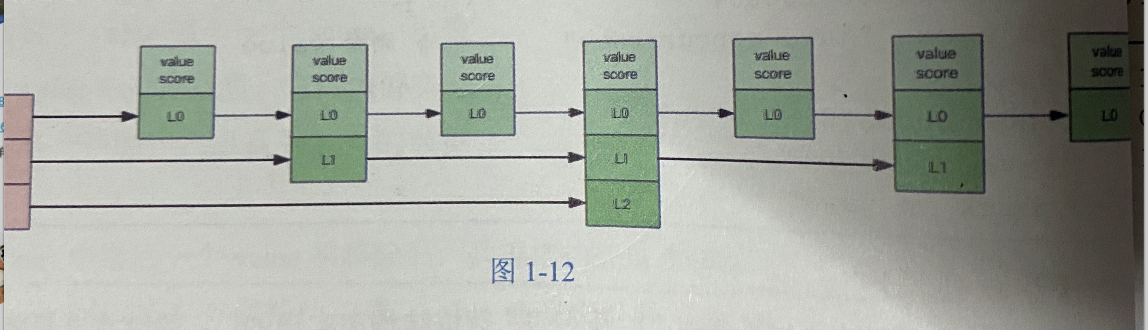
跳跃列表
支持随机的插入和删除,链表按照score排序。
层级制:最下面的一层所有的元素都会串起来。然后每隔几个元素挑选一个代表,再将这几个代码使用另外一级指针串起来。然后在这些代表里挑选第二级代表,再串起来。
容器型数据结构的通用规则
容器不存在,那就常见一个,没有元素就会被删除
过期时间
一个hash结构的过期是整个hash对象的过期,而不是某个key的过期
分布式锁
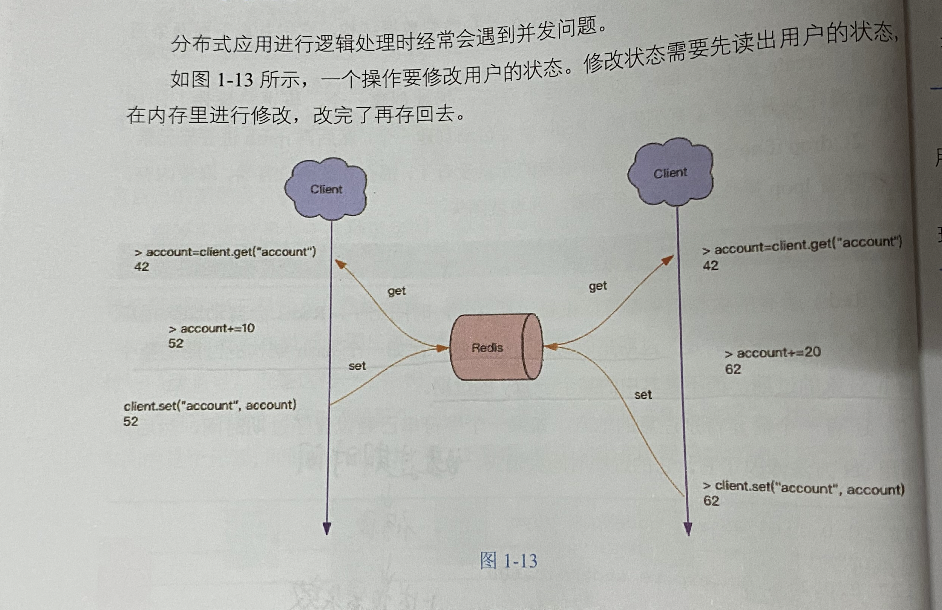
两个都读了改,那有可能造成不一致的问题。所以虽然是单线程,在分布式环境下还是得加锁
分布式锁的本质:在redis里面占一个坑,当别的进程也要来占坑时,发信那里已经有一根大萝卜,就治好放弃或者稍后再试;;------简单来说,不是单线程嘛,一个用户加锁,进去,整个操作完成之后再出来。不能说是,你进去弄以下,我也进去弄以下。
实现分布式锁
setnx key value # 加锁 expire key 10 #设置锁的时间 /*执行想要执行的操作*/ del key #释放锁
上述简单的加锁容易造成以下问题:
1、setnx和expire不是原子性的,死锁
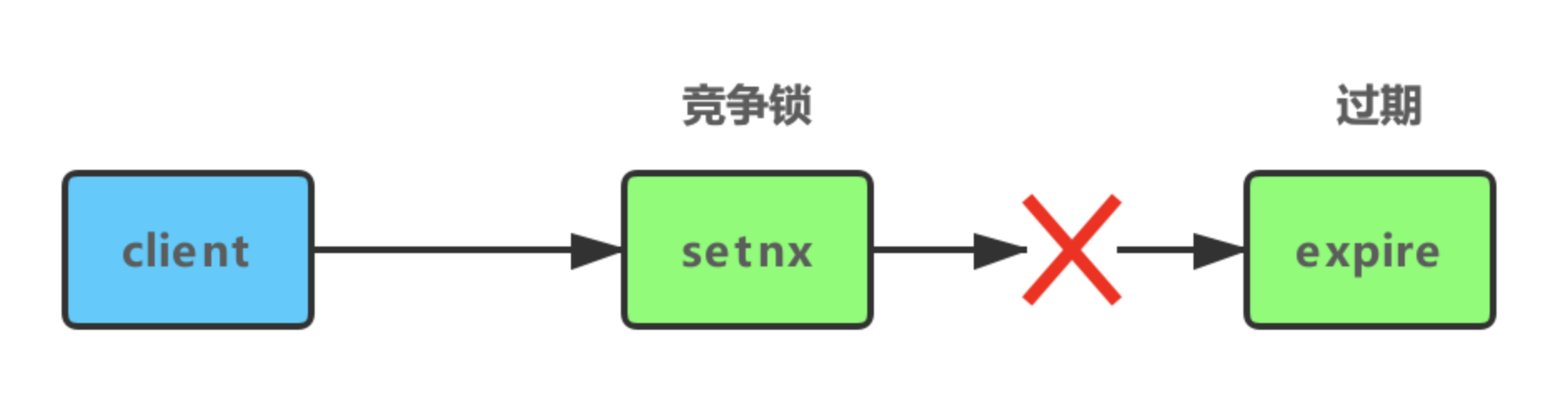
解决:将加锁和时间一起执行
set lock:lock_name true ex 5 nx /*do something*/ del lock:lock_name
2、锁误解除
A获取了锁,但是超时执行了,所以被迫释放了锁;B获取了锁,执行的途中,A执行完了,就顺手释放锁,把B的锁释放了。
解决:删除锁的时候,判断当前锁是不是当前线程持有的,不是的话删不了
3、超时解锁导致并发执行
如果线程 A 成功获取锁并设置过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁,线程 A 和线程 B 并发执行。
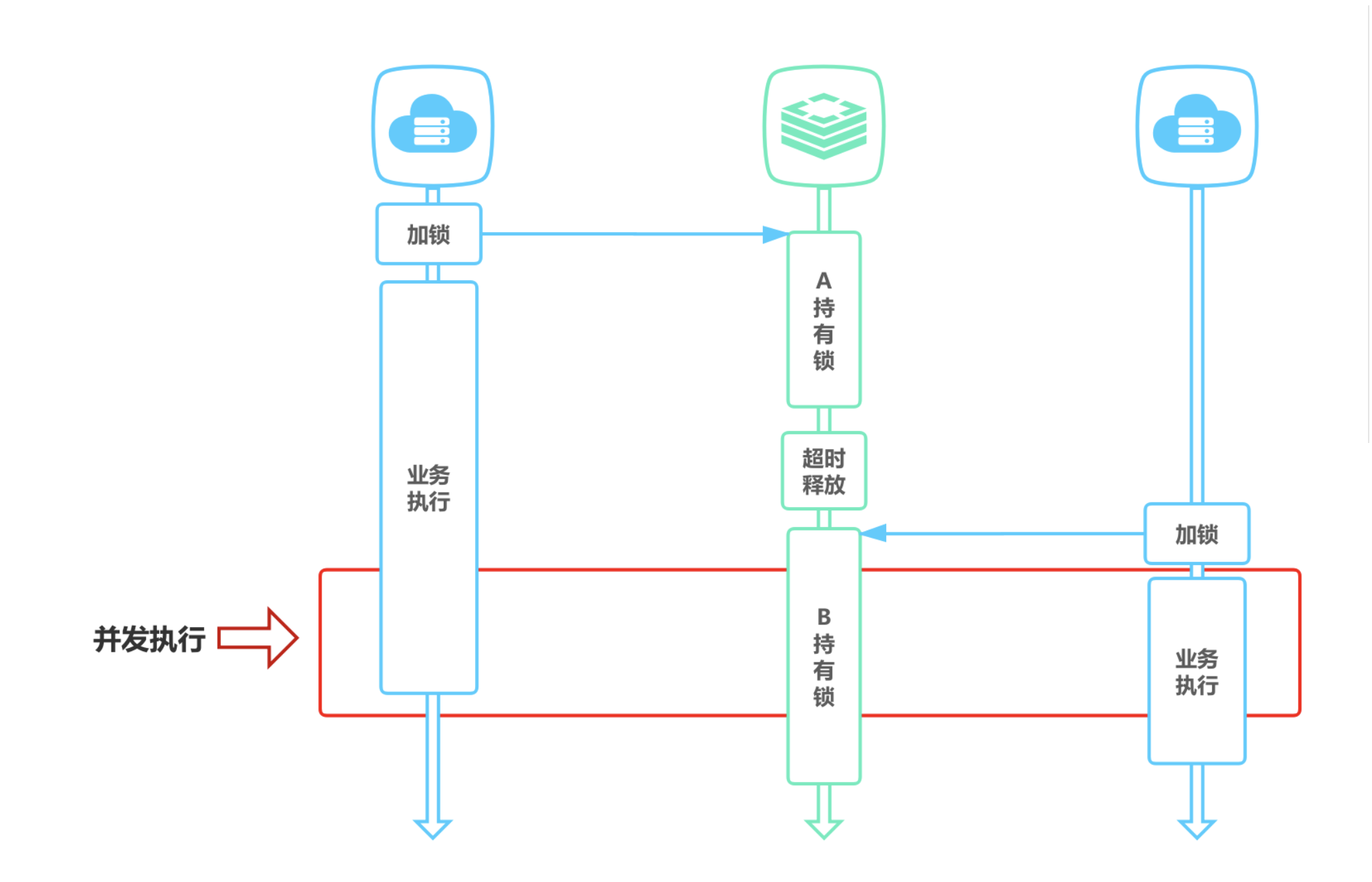
解决方案:
A、B 两个线程发生并发显然是不被允许的,一般有两种方式解决该问题:
- 将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成。
- 为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
4、不可重入(不推荐,因为会增加客户端的复杂性)
当线程在持有锁的情况下再次请求加锁,如果一个锁支持一个线程多次加锁,那么这个锁就是可重入的。如果一个不可重入锁被再次加锁,由于该锁已经被持有,再次加锁会失败。Redis 可通过对锁进行重入计数,加锁时加 1,解锁时减 1,当计数归 0 时释放锁。
在本地记录记录重入次数,如 Java 中使用 ThreadLocal 进行重入次数统计,简单示例代码:
private static ThreadLocal<Map<String, Integer>> LOCKERS = ThreadLocal.withInitial(HashMap::new); // 加锁 public boolean lock(String key) { Map<String, Integer> lockers = LOCKERS.get(); if (lockers.containsKey(key)) { lockers.put(key, lockers.get(key) + 1); return true; } else { if (SET key uuid NX EX 30) { lockers.put(key, 1); return true; } } return false; } // 解锁 public void unlock(String key) { Map<String, Integer> lockers = LOCKERS.get(); if (lockers.getOrDefault(key, 0) <= 1) { lockers.remove(key); DEL key } else { lockers.put(key, lockers.get(key) - 1); } }
3、无法等待锁释放
如果客户端可以等待锁释放就无法使用。
- 可以通过客户端轮询的方式解决该问题,当未获取到锁时,等待一段时间重新获取锁,直到成功获取锁或等待超时。这种方式比较消耗服务器资源,当并发量比较大时,会影响服务器的效率。
- 另一种方式是使用 Redis 的发布订阅功能,当获取锁失败时,订阅锁释放消息,获取锁成功后释放时,发送锁释放消息。
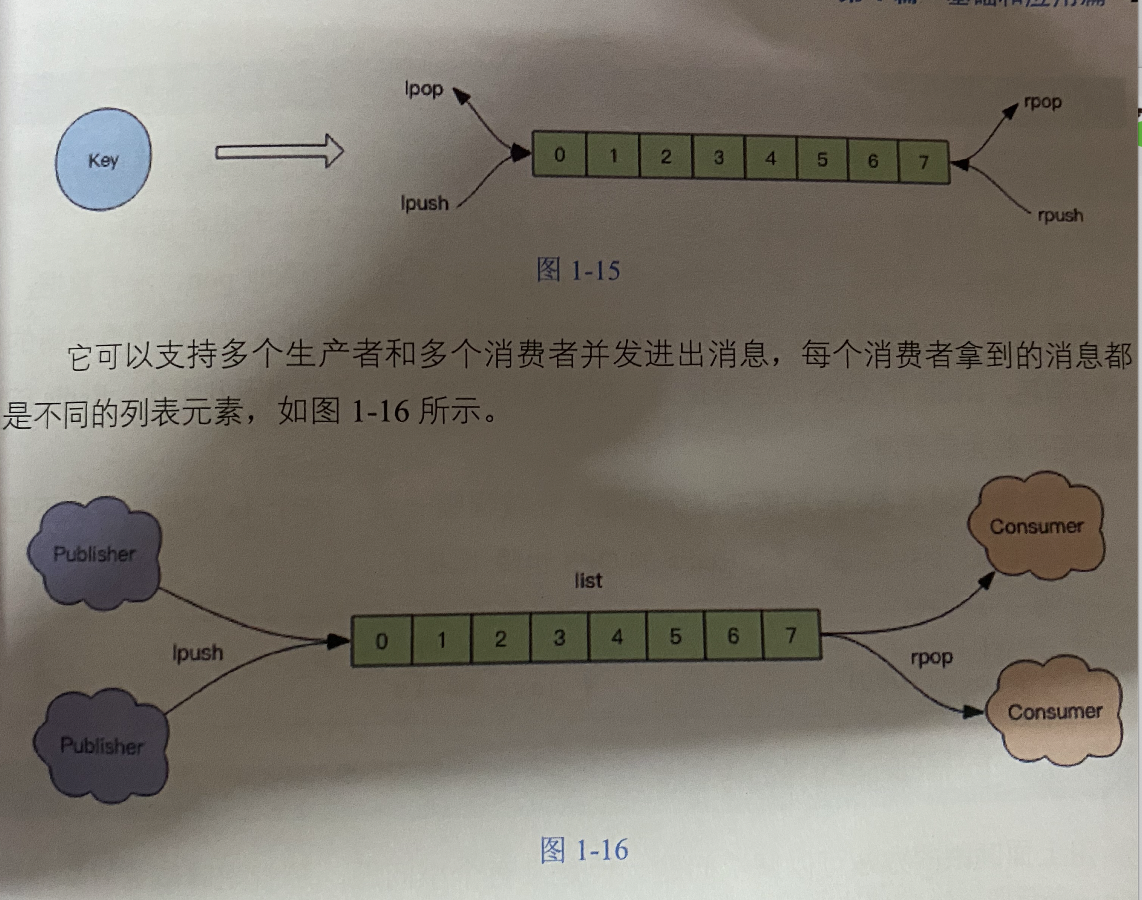
延时队列
那些只有一组消费者的消息队列,使用redis可以非常轻松的搞定。需要注意的是,redis的消息队列不是专业的队列,它没有非常多的高级特性,没有ack保证,如果对消息的可靠性有着极高的要求,那么它就不适合使用
队列空了怎么办
QPS:Queries Per Second,没秒查询频率
如果老是空轮询的话,那就太惨了,QPS会越来越高。
- 睡眠1s----假如有好多消费者,难道每个消费者睡眠1s嘛?那肯定不行,因为每个消费者的开始睡眠的时间都不是一样的。
- 阻塞读-----blpop/prpop,没有数据就进入睡眠状态,一旦数据来了就唤醒。
- 空闲连接自动断开
分布式锁加锁失败怎么办?
- 直接抛出异常
- sleep一会,然后尝试
- 将请求转移至延时队列,过会再试
位图
会有一些bool型数据需要存取,比如用户一年的签到记录,签了1,没签0,要记录365天。如果使用简单的key/value,每个用户要记录365个,当用户数量上亿的时候,需要的存储空间是惊人的。
为了解决上述问题:redis提供了位图数据结构,这样每天签到记录只占据一个位。
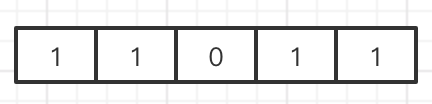
位图其实不是什么特殊的结构,就是简单的字符串,redis提供给你操作位的功能。getbit/setbit
基本用法
记住字符的二进制表示,setbit是从高位开始的。
#创建一个变量 ,该字母的asc表示为:01100000 setbit key 1 0 setbit key 2 1 #获取第二位是0 还是1 getbit key 1 #获取了这个字符 get key
零存零取:一位一位的设置,最后将每一位取出来
整存零取:整存。取每一位。
统计和查找
基于位图的统计指令---bitcount
位图查找指令----bitpost
bitcount key #统计字符串的二进制中1的个数
bitpos key 0 2 #查找位图中0 到2 中的第一个1的位置
一次性操作几个位
bitfield:一次性进行多个位的操作
需要搭配子指令
set w hello
#从下标0开始取4位,当作无符号数 bitfield w get u4 0
#有符号数 bitfield w get i3 2
# 从下标8开始,设置8个数位97 bitfield w set u8 8 97
#增加 bitfield w incrby u4 2 3
累加小心溢出问题。
默认是折返:假如读取4位,每位累加,然后1111再加就会溢出了,那再加就折返,变成0000,重新来咯
可以设置成截断,就是不加了。
bitfield w overflow sat incrby u4 2 1
也可以失败不执行
bitfield w overflow fail incrby u4 2 1
HyperLogLog
UV:user view
PV:page view
需要统计网站页面的用户访问次数,需要去重的
- 使用set,但是无法面对巨大的访问量
- 使用HyperLogLog
高级数据结构
HyperLogLog提供了两个指令:pfadd和pfcount
pfadd user user1
pfadd user user2
pfadd user user3
pfcount user
3
但是不是精确的统计
pfmerge场合:将多个pf计数值累计起来形成一个新的pf值
需要12kB的存储空间,不适合存储单个用户的数据
- 在存储数量很小的时候,存储空间采用稀疏矩阵,空间占用很小。
- 当存储的数量很大时,那就变成稠密矩阵。
- 实现原理,看不懂
布隆过滤器
无法判断一个元素是否在集合当中
应用场景:别给用户推荐相同的的内容,那么就需要存储历史记录,新一次推荐的时候就需要去重。
此时布隆过滤器拯救你的不开心
Bloom Filter
但是不是很精确
- 如果通过布隆过滤器加入的记录,那么它肯定能识别出来在集合中;但是没经过的,有可能识别成存在;
- 如果布隆说:没见过,那么肯定是没见过
- 如果布隆说:我见过,不一定见过的。
所以布隆过滤器能准确的过滤掉那些用户已经看过的内容,那些用户没有看过的内容可能会过滤一部分。
redis4之后需要加载插件之后才能使用
- bf.add添加元素
- bf.exists判断元素是否存在
- bf.madd、bf.mexists
有那么一些误差,但是没关系
布隆过滤器可以设置参数调节误差
- key
- error_rate错误率:越低,需要的空间越大
- initial_size初始化大小:预计放入的元素数量,当实际数量超过这个数值时,误判率会上升,所以需要提前设置一个较大的数值避免超出导致误判率升高。
默认的error_rate是0.01,默认的initial_size大小是100
注意事项:
- initial_size设置的过大,会浪费存储时间,设置的过小,就会影响准确率,所以使用之前一定要尽可能的精确估计元素的数量;当然还需要加上一些冗余空间避免元素可能会意外高出。
过滤器的原理
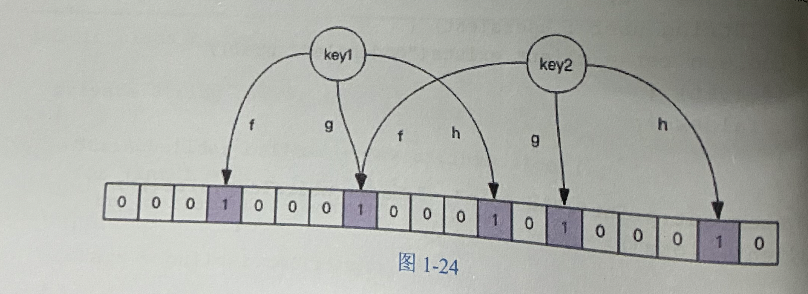
- 将key1添加到布隆过滤器
- 将key进行fgh三个哈希函数进行哈希,得到一个整数,然后取余,将initial_size大小的数组相应位置设置成1
- 判断key2是否存在,那么就是hash,得到三个位置,看一下3个位置是不是都位1,都为1,那就证明存在。------这就是为什么会把没有的看成有的原因。
- 当布隆过滤器容量远小于实际数量时,应该重建布隆过滤器。
布隆过滤器有几个参数:
- 预计元素数量n
- 错误率f
根据上述的两个参数得出两个输出:
- 数组长度l
- 输出hash函数的最佳数量k----也就是一个key被hash成几位

当元素超过实际长度后,错误率会增加。
简单限流
当系统的处理能力有限时,如何阻止计划外的请求继续对系统施压
-----控制用户行为,避免垃圾请求
解决方案:滑动窗口(定宽)-----zset
用score存储当前时间,value的话唯一就好;
然后通过过滤某一个时段的请求,如果数量大了,就不行哦。
漏斗限流
一个漏斗样,出水速度一样。
Funnel对象的make_space方法是漏斗算法的核心,其在每次灌水前都会被调用以触发漏水,给漏斗腾出空间来。能腾出多少空间取决于过去了多久以及流水的速度。
----hash结构可以实现
------redis-cell模块
cl.throttle laoqian:reply 15 30 60 1
参数:
- key
- 容量
- 出水速度
- 可选参数,默认为1
如果被拒绝了,会返回重试的时间。
GeoHash
地理模块
Geo算法:将二维数据映射到一维的整数;划分小格子。
redis会将那个整数进行编码放进zset中,value是元素的key,score是GeoHash的52位整数值
本质是zset,跳跃链表
增加
geoadd company 116.48 39.996 jujin geoadd company 66.48 39.996 meituan geoadd company 61.48 109.996 ali
距离
geodist company juejin meituan km
geodist company juejin ali km
获取元素位置
geopos company juejin
获取元素的hash值
# 获取编码的值----score
geohash company juejin
附近的公司
georadiusbymember company ireader 20km count 3 asc georadiusbymember company ireader 20km count 3 desc georadiusbymember company ireader 20km withcoord withdist withhash count 3 asc
在集群环境中单个key对应的数据量不宜超过1MB,否则集群迁移的时候出现卡顿现象
建议GEO的数据使用单独的Redis实例部署,不使用集群。
Scan
在Redis的key中找特定前缀的key列表,修改它的值;如何从海量的key中找出满足特定前缀的key列表
- 简单粗暴的指令keys用来满足特定正则表达式
- 没有offset、limit参数
- 遍历算法复杂度n
- scan
- 复杂度也是n
- 提供limit参数
- 同keys一样,模式匹配
- 服务器不需要为游标保存状态,游标的唯一状态就是scan返回
- 返回的结果会有重复,需要客户端去重。
- 遍历的过程中如果有数据修改,改动后的数据能不能被遍历不能确定的
- 单次返回结果是空的并不意味着遍历,而要着返回的游标值是否为零。
scan 0 match key99* count 1000
可能找不到
字典的结构
游标就是第一维数组的位置索引,我们将这个位置索引称为槽
limit参数就表示需要遍历的槽位数,之所以返回的结果可能多可能少,是因为不是所有的槽位上都挂接链表。
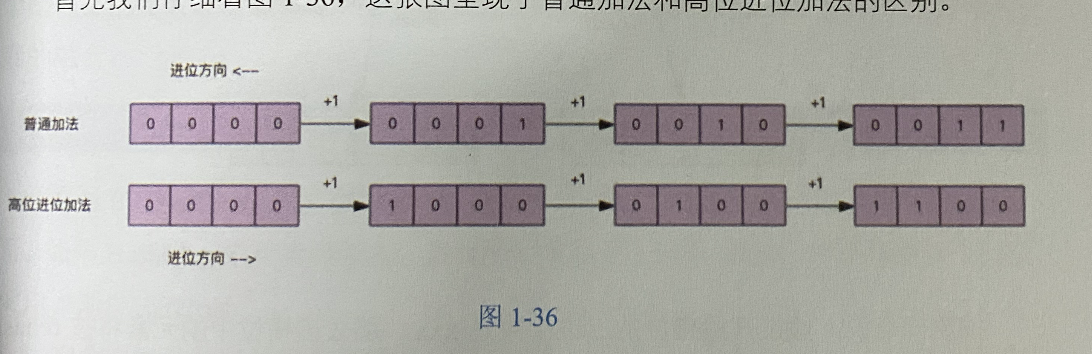
scan的遍历顺序非常特别,它不是从第一维数组的第0位一直遍历到末尾,是才用了高位进位法来遍历,考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
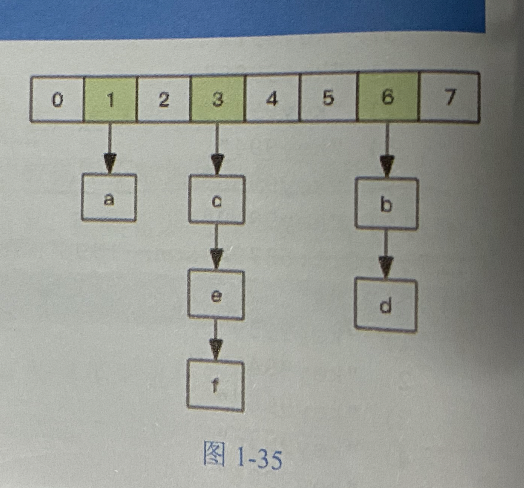
高位进位加法:遍历的所有的槽位并且没有重复
字典扩容
扩容缩容也就是在高位添加1和0的差别,因为扩容都是double的
橙色的为即将访问的

缩容会造成一部分的重复
渐进rehash
如果在旧数组下面找不到元素,还需要去新数组下面寻找,最后将结果融合发送给客户端
对容器指定的集合进行遍历
zscan
hscan
sscan遍历set集合的元素
大key扫描
避免大key的产生
影响。回收、扩容、迁移