In a recent paper by OpenAi —Solving Rubik’s Cube with a Robot Hand — researchers introduce the concept of training robots in simulations and then deploying them to real world robots. They used a technique called domain randomization that helps creating multiple environments with slight changes in them. For example in case of Rubix’s cube — they generate cubes of different sizes and dimensions, generating more generalization for the agent to learn.
In a Nature article, “Your robot surgeon will see you now”author describes robotic surgery bring performed in a autonomous manner.
“Researchers are showing how it can navigate to a patient’s leaking heart valve better than some surgeons can with years of training. First, the assembly is inserted into the base of the heart. From there, it propels itself using a motorized drive system along the pulsating ventricular wall to a damaged valve near the top of the ventricle, guided by vision and touch sensors.”
In another IEEE paper, mention about Smart Tissue Autonomous Robot (STAR) In Flesh-Cutting Task, Autonomous Robot Surgeon Beats Human Surgeons — The robot made more precise cuts with less tissue damage
“In 2016, the system sewed together two segments of pig intestine with stitches that were more regular and leak-resistant than those of experienced surgeons.” ….. “Before they tested the system against human surgeons, STAR first had to prove its ability to make precise cuts in these three types of irregular soft tissue, which can resist a cutting tool and then give way abruptly, causing the tool to make inaccurate cuts.”
But here’s the problem —Autonomous robots need training by actually doing the task, and we cant allow them to operate till there accuracy is tested. To deal with this issue, there is a growing research about using of simulations to train the agents and then later transfer them to real world robots for testing.
In pursuit of accelerate research on intelligent robots, OpenAi gym has released eight new simulated robotics environments — Mainly in two categories 1. Fetch robots 2. Hand manipulation
These environments are nice place to get into the world of robotics system. Once trained in simulation, these can be deployed on a physical robot, which can learn a new task after seeing it done once. This can remove the barrier of physical worlds —requirement of multiple robots to generate data quickly and possible damage caused by the agent in initial stages when it isn’t fully trained.
Prerequisite
Install
- OpenAI gym
- MuJoCo physics simulator
Fetch Robotics environments
We are going to discuss 4 environments —
- FetchReach-v0: Fetch has to move its end-effector to the desired goal position.
- FetchSlide-v0: Fetch has to hit a puck across a long table such that it slides and comes to rest on the desired goal.
- FetchPush-v0: Fetch has to move a box by pushing it until it reaches a desired goal position.
- FetchPickAndPlace-v0: Fetch has to pick up a box from a table

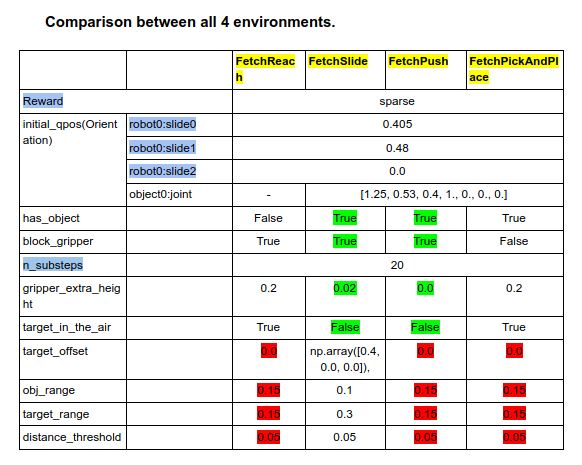
Comparison between different environments
All the findings highlighted in blue are common among all the 4 environments.
Green highlights are common between Sliding and pushing.
Red are common between Reach and Push and Pick&Place.
Tasks that can be accomplished with these environments
- Pushing. In this task a box is placed on a table in front of the robot and the task is to move it to the target location on the table. The robot fingers are locked to prevent grasping. The learned behaviour is a mixture of pushing and rolling.
- Sliding. In this task a puck is placed on a long slippery table and the target position is outside of the robot’s reach so that it has to hit the puck with such a force that it slides and then stops in the appropriate place due to friction.
- Pick-and-place. This task is similar to pushing but the target position is in the air and the fingers are not locked. To make exploration in this task easier we recorded a single state in which the box is grasped and start half of the training episodes from this state3 .
Environment
States: uses MuJoCo physics engine and consists of angles and velocities of all robot joints as well as positions, rotations and velocities (linear and angular) of all objects.
Initial Gripper position: For all tasks the initial position of the gripper is fixed, while the initial
position of the object and the target are randomized.
For all tasks the initial position of the gripper is fixed.
- pushing and sliding tasks it is located just above the table surface
- pushing it is located 20cm above the table.
Object position: The object is placed randomly on the table in the 30cm x 30cm (20c x 20cm for sliding) square with the center directly under the gripper (both objects are 5cm wide).
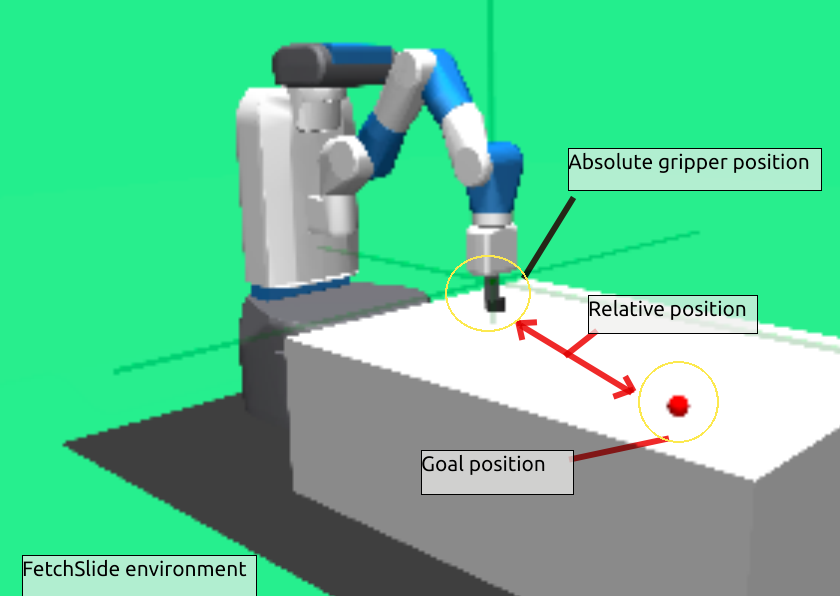
Goal state:
- For pushing, the goal state is sampled uniformly from the same square as the box position.
- In the pick-and-place task the target is located in the air in order to force the robot to grasp (and not just push). The x and y coordinates of the goal position are sampled uniformly from the mentioned square and the height is sampled uniformly between 10cm and 45cm.
- For sliding the goal position is sampled from a 60cm x 60cm square centered 40cm away from the initial gripper position.
- For all tasks we discard initial state-goal pairs in which the goal is already satisfied.
Goal position
Firstly, please import gym, then call gym.make() and reset().
import gym
env=gym.make('FetchPickPlace-v1')
env.reset()
print( env.goal)
Step -
Step defines individual action by the agent that leads to change in the state of the environment.
Each step consists of 4 parts — observations , reward , done , info
print(env.step(env.action_space.sample()))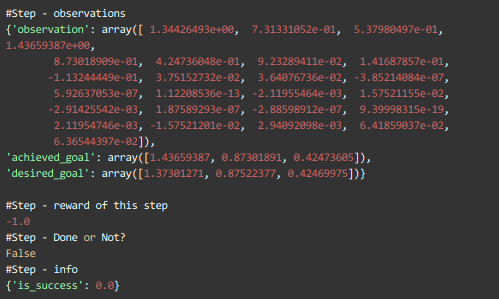
Reward can be either -1 or 0.
Done — tell if the task is actually complete or not!
2.1 Observation
The policy is given as input the
- absolute position of the gripper
- the relative position of the object and the target ,
- Distance between the fingers.
The Q-function is additionally given the linear velocity of the gripper and fingers as well as relative linear and angular velocity of the object.
print(env.observation_space)
print(env.observation_space.sample())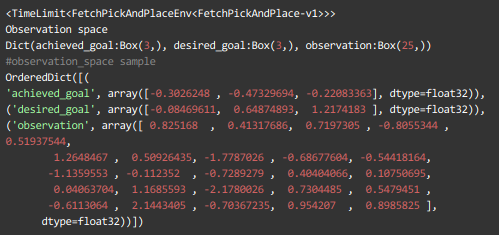
2.2 Actions
Actions: Action space is 4-dimensional.
None of the problems requires gripper rotation, hence it is kept fixed.
- First 3 dimensions — specify the desired relative gripper position at the next timestep.
- Last dimension — specifies the desired distance between the 2 fingers which are position controlled.
print( env.action_space)
print(env.action_space.sample())
2.3 Reward
All environments by default use a sparse reward of -1, if the desired goal was not yet achieved and 0 if it was achieved (within some tolerance).
Unless stated otherwise we use binary and sparse rewards r(s, a, g) = −[fg (s0) = 0]
where s0 if the state after the execution of the action a in the state s.
OpenAI gym also includes a variant with dense rewards for each environment. However, Sparse rewards are more realistic in robotics applications and highly encouraged.
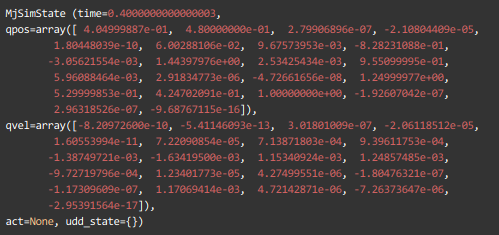
2.4 Starting State — by using print(env.initial_state)
print(env.initial_state)qpos = initial observation of the environment presented to the agent
qvel = is the initial velocity and angular velocity of the arm, joints.
2.5 Episode Termination
The episode terminates when:
1. Episode length is greater than 50
Terminologies in Code:
- model_path (string): path to the environments XML file
- n_substeps (int): number of substeps the simulation runs on every call to step
- gripper_extra_height (float): additional height above the table when positioning the gripper
- block_gripper (boolean): whether or not the gripper is blocked (i.e. not movable) or not
- has_object (boolean): whether or not the environment has an object
- target_in_the_air (boolean): whether or not the target should be in the air above the table or on the table surface
- target_offset (float or array with 3 elements): offset of the target
- obj_range (float): range of a uniform distribution for sampling initial object positions
- target_range (float): range of a uniform distribution for sampling a target
- distance_threshold (float): the threshold after which a goal is considered achieved
- initial_qpos (dict): a dictionary of joint names and values that define the initial configuration
- reward_type (‘sparse’ or ‘dense’): the reward type, i.e. sparse or dense
offset — The distance from a starting point, either the start of a file or the start of a memory address.
Looking into Code
gym/gym/envs/robotics/robot_env.py
class RobotEnv(gym.GoalEnv):
def __init__(self, model_path, initial_qpos, n_actions, n_substeps):
if model_path.startswith('/'):
fullpath = model_path
else:
fullpath = os.path.join(os.path.dirname(__file__), 'assets', model_path)
if not os.path.exists(fullpath):
raise IOError('File {} does not exist'.format(fullpath))
model = mujoco_py.load_model_from_path(fullpath)
self.sim = mujoco_py.MjSim(model, nsubsteps=n_substeps)
self.viewer = None
self._viewers = {}
self.metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': int(np.round(1.0 / self.dt))
}
self.seed()
self._env_setup(initial_qpos=initial_qpos)
self.initial_state = copy.deepcopy(self.sim.get_state())
self.goal = self._sample_goal()
obs = self._get_obs()
self.action_space = spaces.Box(-1., 1., shape=(n_actions,), dtype='float32')
self.observation_space = spaces.Dict(dict(
desired_goal=spaces.Box(-np.inf, np.inf, shape=obs['achieved_goal'].shape, dtype='float32'),
achieved_goal=spaces.Box(-np.inf, np.inf, shape=obs['achieved_goal'].shape, dtype='float32'),
observation=spaces.Box(-np.inf, np.inf, shape=obs['observation'].shape, dtype='float32'),
))gym/gym/envs/robotics/fetch/reach.py
class FetchReachEnv(fetch_env.FetchEnv, utils.EzPickle):
def __init__(self, reward_type='sparse'):
initial_qpos = {
'robot0:slide0': 0.4049,
'robot0:slide1': 0.48,
'robot0:slide2': 0.0,
}
fetch_env.FetchEnv.__init__(
self, MODEL_XML_PATH, has_object=False, block_gripper=True, n_substeps=20,
gripper_extra_height=0.2, target_in_the_air=True, target_offset=0.0,
obj_range=0.15, target_range=0.15, distance_threshold=0.05,
initial_qpos=initial_qpos, reward_type=reward_type)
utils.EzPickle.__init__(self)gym/gym/envs/robotics/fetch/slide.py
class FetchSlideEnv(fetch_env.FetchEnv, utils.EzPickle):
def __init__(self, reward_type='sparse'):
initial_qpos = {
'robot0:slide0': 0.05,
'robot0:slide1': 0.48,
'robot0:slide2': 0.0,
'object0:joint': [1.7, 1.1, 0.41, 1., 0., 0., 0.],
}
fetch_env.FetchEnv.__init__(
self, MODEL_XML_PATH, has_object=True, block_gripper=True, n_substeps=20,
gripper_extra_height=-0.02, target_in_the_air=False, target_offset=np.array([0.4, 0.0, 0.0]),
obj_range=0.1, target_range=0.3, distance_threshold=0.05,
initial_qpos=initial_qpos, reward_type=reward_type)
utils.EzPickle.__init__(self)gym/gym/envs/robotics/fetch/push.py
class FetchPushEnv(fetch_env.FetchEnv, utils.EzPickle):
def __init__(self, reward_type='sparse'):
initial_qpos = {
'robot0:slide0': 0.405,
'robot0:slide1': 0.48,
'robot0:slide2': 0.0,
'object0:joint': [1.25, 0.53, 0.4, 1., 0., 0., 0.],
}
fetch_env.FetchEnv.__init__(
self, MODEL_XML_PATH, has_object=True, block_gripper=True, n_substeps=20,
gripper_extra_height=0.0, target_in_the_air=False, target_offset=0.0,
obj_range=0.15, target_range=0.15, distance_threshold=0.05,
initial_qpos=initial_qpos, reward_type=reward_type)
utils.EzPickle.__init__(self)gym/gym/envs/robotics/fetch/pick_and_place.py
MODEL_XML_PATH = os.path.join('fetch', 'pick_and_place.xml')
class FetchPickAndPlaceEnv(fetch_env.FetchEnv, utils.EzPickle):
def __init__(self, reward_type='sparse'):
initial_qpos = {
'robot0:slide0': 0.405,
'robot0:slide1': 0.48,
'robot0:slide2': 0.0,
'object0:joint': [1.25, 0.53, 0.4, 1., 0., 0., 0.],
}
fetch_env.FetchEnv.__init__(
self, MODEL_XML_PATH, has_object=True, block_gripper=False, n_substeps=20,
gripper_extra_height=0.2, target_in_the_air=True, target_offset=0.0,
obj_range=0.15, target_range=0.15, distance_threshold=0.05,
initial_qpos=initial_qpos, reward_type=reward_type)
utils.EzPickle.__init__(self)Rendering modes — “Human mode” and “rgb array”
gym/gym/envs/robotics/robot_env.py
def render(self, mode='human', width=DEFAULT_SIZE, height=DEFAULT_SIZE):
self._render_callback()
if mode == 'rgb_array':
self._get_viewer(mode).render(width, height)
# window size used for old mujoco-py:
data = self._get_viewer(mode).read_pixels(width, height, depth=False)
# original image is upside-down, so flip it
return data[::-1, :, :]
elif mode == 'human':
self._get_viewer(mode).render()You can read more of my blogs on — https://amritpal001.wordpress.com/
To look at the code for my projects, browse my github account — https://github.com/Amritpal-001