一、redis工作机制
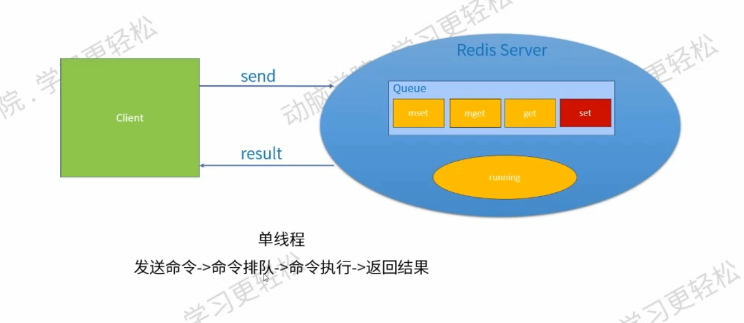
redis是 单线程,所有命令(set,get等)都会加入到队列中,然后一个个执行。
二、为什么redis速度快?
1、基于内存
2、redis协议resp 简单、可读、效率高
三、什么是resp
redis是一个ServerSocket服务器,而Jedis是一个Socket客户端类似redis-cli,用于与redis通讯,而redis和jedis之间通讯用的就是resp,如下图,如果jedis要设置一个值,命令是:set name shyroke,转为resp协议为:
*3 $3 set $4 name $7 shyroke
而如果jedis想要获取一个值,发送指令:get name,转为resp为:
*2 $3 get $4 name

四、redis分表分库
如果数据量太大,一个redis存不下,那么此时就需要分表分库。

最简单的做法编写一个代理服务器,不管是数据库还是客户的缓存都通过代理,然后key进行路由,具体做法是对key长度进行取模,所得的结果就是相应的redis服务器。
案例:
(1)启动3个redis服务器,只要复制3份redis的配置文件(redis.window.conf),修改其中的端口号,然后分别脚本启动启动:redis-serve.exe 配置1.conf redis-serve.exe 配置2.conf redis-serve.exe 配置3.conf
(2)客户端请求代理服务器,代理服务器解析resp协议,并使用代理算法(key长度取模)计算相应的redis服务器,然后进行操作。代理算法:此时有3台服务器,此时执行:set name shyroke ,key的值为name,那么对key长度取模 = 4%3 = 1 ,所以此时会执行第二台redis服务器,也就是会往第二台代理服务器中存数据。

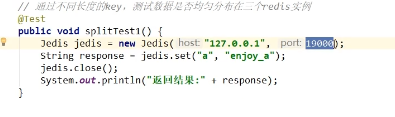
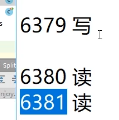
(3)测试如下图,19000是代理服务器的端口,此时jedis连接代理服务器,然后存一个值a=enjoy_a,a的长度是1,此时服务器有3台,所以1%3=1,所以此时会向第二台服务器也就是127.0.0.1:6380这台服务器存一个值。
五、redis之读写分离
如果有读多写少或者读少写多的场景,尤其是电商项目,读多写少,此时可以进行读写分离,也就是说可以用一台服务器用于写操作,多台服务器进行读操作。
案例
以三台服务器为例如下图,关键是数据同步,也就是说写的那台数据库的数据如何同步到其他用于读的数据库里。
1、修改两台读的redis服务器的配置文件,如下图,需要注意的是,加了下图的配置后就不能进行写(set)操作,只能往主节点(即写服务器)中写,只能进行读操作(get)

2、主节点(本例中为写服务器)挂了怎么办?
使用哨兵机制。即设置定时器,定时去ping主节点,如果pign不通则说明主节点(写服务器)挂了,此时就需要从子节点(读服务器)中选一个作为主节点,然后其他子节点作为新主节点的子节点。主节点中执行redis命令:info application 中可以获取主节点中所有子节点。
1、检查主节点状态
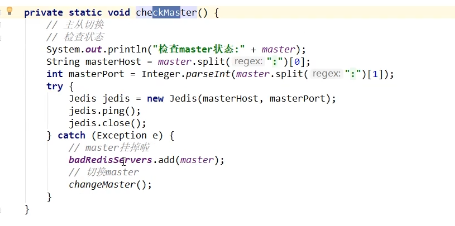
2、切换主节点。
