一、摘要
作者提出了一种简单的动作迁移方法,实现了“do as I do”:给定一个人跳舞的源视频,作者可以在目标对象表演标准动作的短短几分钟后,将该表演转移到一个新的(业余的)目标上。作者提出了一个基于时空平滑的逐帧的时图像转换问题。用姿态检测作为源和目标之间的中间表示,作者学习了一个从姿态图片到目标对象外观的映射。作者将此设置应用于包括真实面部合成在内的时间上相干的视频生成。
二、引言
作者通过基于像素的端到端的原则实现两个对象之间的动作迁移,这种方法和以前的最近邻方法和动作重定位都有区别。在作者提出的框架上,作者创造出了很多视频。为了逐帧地实现两个视频对象的动作迁移,必须学习出两个独立图片之间的映射关系,即找到源和目标集合之间图像到图像的转换关系。然而没有两个对象表演相同的动作而产生的图像对,即使两个对象都在转圈,但是也没办法做到一模一样。
基于关键点的姿态内在地将人体姿势而不是外形进行编码。作者用姿势图作为每帧中人体的中间表示,对每帧图像进行姿态检测得到(姿态图像-目标人体图像)对应的图像对。有了这些图像对,作者便可以以有监督的学习出图像到图像的转换模型。为了将动作从源转换到对象上,作者将姿态图输入到训练好的模型上,然后在目标对象上得到和源相同的姿势。作者添加了两个部分来提结果的质量:为了让时序动作更流畅,在前一帧的基础上有条件地预测下一帧(we condition the prediction at each frame on that of the previous time step)。为了生成更加真实的脸部动作,作者训练了一个特殊的GAN来生成目标对象的面部。
作者提出了一种生成视频的方法,生成的视频将源视频的动作可以迁移到目标视频上,它不需要昂贵的3D或者动作捕捉数据就可以实现,作者主要提出了一种基于学习的不同视频人体动作迁移的方法。该方法可以实现复杂的动作迁移并且细节做的很好,做的很逼真,作者还在baseline上进行了各个部分的消融实验。
作者的故事讲得很好,在提到基于关节点的姿态之前,都让读者觉得让另外一个对象模拟源对象的动作是非常困难的事情,当作者提到姿态这个很常见的模式时,反过来看,才发现姿态原来很常见,但是作者前半段的叙述就让人很想看下去,看怎么去解决这个困难的问题
三、相关工作
作者是学习去合成新的动作,而不是操纵现有的视频帧。
人体动力学模型,得到3D节点估计
四、方法
给定一个源视频和另外一个目标人物,目标是生成一个新的视频,视频中的目标人物表演着和源视频中人物的相同的动作。这个任务分为三个部分进行:姿态检测、全局姿态归一化、从归一化的姿态图映射到目标对象上。在姿态检测中,作者用最优的姿态检测器生成源视频帧的姿态图。全局姿态归一化为了解决每一帧源和目标人体外形和未知的差异。设计了一个对抗训练系统将归一化的姿态图映射到目标对象上。
训练:
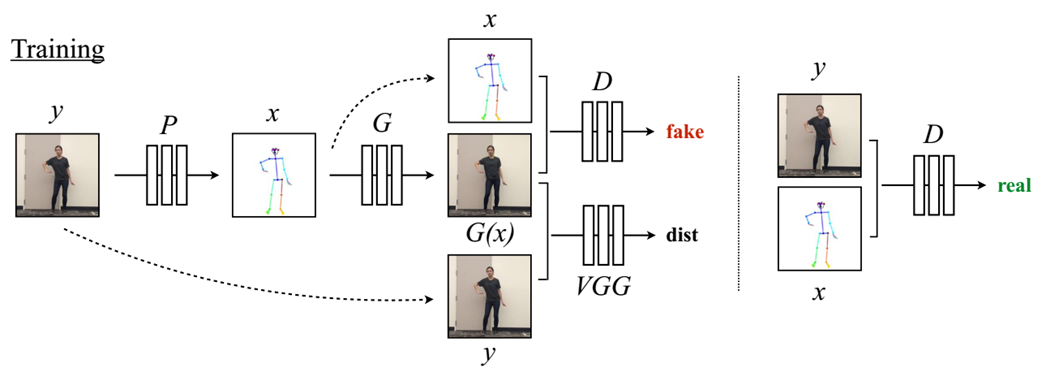
给定原始目标视频中的一帧(y),用姿态估计器(p)得到对应的姿态图(x = P(y)),在训练过程中,用((x,y))对学习出一个映射函数(G),映射函数将生产目标人物的姿态图的合成图片,通过判别器(D)和用VGGNet预训练的感知重建损失(dist)来优化生成的虚拟图像(G(x)),使其更接近真实帧(y),判别器(D)用来判断真实对(x,y)和虚假对(x,G(x))。
判别器:D判断real image pairs 和fake image pairs,即(x,y)和(x, G(x))
生成器:G用姿态图生成虚拟图像G(x)
损失:y和G(x)之间的感知重建损失dist
转换
将源视频中的一帧(y')用姿态估计器检测出姿态(x'),然后对其进行全局姿态归一化转化为(x),最后用生成器(G)生成最终的和(y')帧动作一致的虚拟图像(G(x))。
全局姿态归一化
分析每个对象姿态的高度和脚踝位置、在最近和最远脚踝位置用线性映射进行尺度和位移变化
1. 转换的具体过程

姿态检测→全局姿态归一化→从归一化的姿态图映射到目标对象上
- 用最优的姿态检测器生成源视频帧的姿态图
- 全局姿态归一化为了解决每一帧源和目标人体外形和未知的差异
- 设计了一个对抗训练系统将归一化的姿态图映射到目标对象上
2. 姿态估计
用openpose进行姿态估计产生关节点的二维坐标,作者将二维坐标点用线段连起来生成了如左图所示的火柴人。

3. 全局姿态归一化
- 为了解决源视频和目标视频中人体外形和未知差异
- 计算偏移量b
- 尺度缩放比例scale
4. 训练生成器G
以pix2pixHD作为baseline:
第一项为对抗损失、第二项为特征匹配损失、第三项为感知重建损失
- 对抗损失:(mathcal{L}_{mathrm{GAN}}(G, D)=mathbb{E}_{(x, y)}[log D(x, y)]+mathbb{E}_{x}[log (1-D(x, G(x))])
- 特征匹配损失:(mathcal{L}_{F mathcal{M}}left(G, D_{k} ight)=mathbb{E}_{(s, chi)} sum_{i=1}^{T} frac{1}{N_{i}}left[left|D_{k}^{(i)}(s, x)-D_{k}^{(i)}(s, G(s)) ight|_{1} ight])
- 感知重建损失:(ell_{f e a t}^{phi, j}(hat{y}, y)=frac{1}{C_{j} H_{j} W_{j}}left|phi_{j}(hat{y})-phi_{j}(y) ight|_{2}^{2})
相应参考文献:
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
Perceptual Losses for Real-Time Style Transfer and Super-Resolution.
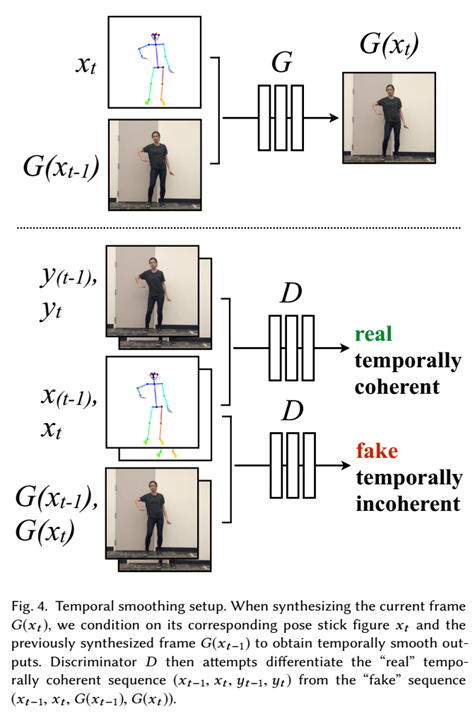
5.时间平滑
为了实现视频帧在时间上的连续性,作者修改单个图像生成设置来强制相邻帧之间的时间相干性。
-
生成器G的输入:当前帧t的姿态图+前一帧生成的虚拟图像
-
判别器:判断当前帧和前一帧成对的图像
-
在最大化D的能力的前提下,最小化D对G的判断能力
6.Face GAN
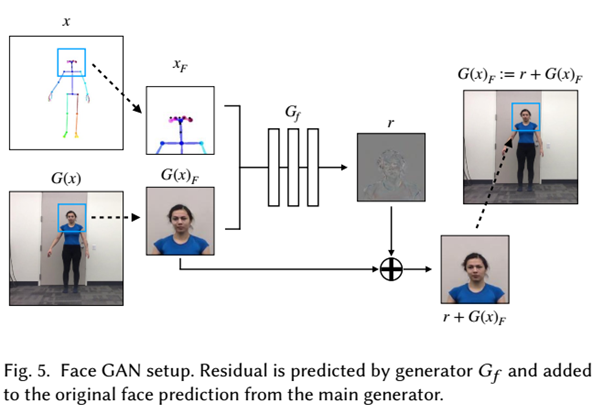
使用主生成器G生成场景的完整图像之后,输入以面部G(x)为中心的图像的较小部分和这个部分对应的姿势图。r为residual,最后的输出是残差r和原来生成的面部相加。
四、实验结果
由于生成图像,没有相应的真实图像来评价,为了评价单个图像的质量,作者用structural
similarity(SSIM)和Learned Perceptual Image Patch Similarity(LPIPS)两个指标来评价生成图像的性能
相关参考文献:
Image quality assessment:from error visibility to structural similarity.
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric.
身体图像输出比较:

面部图像输出比较:

姿态距离:(dleft(p, p^{prime} ight)=frac{1}{n} sum_{k=1}^{n}left|p_{k}-p_{k}^{prime} ight|_{2})

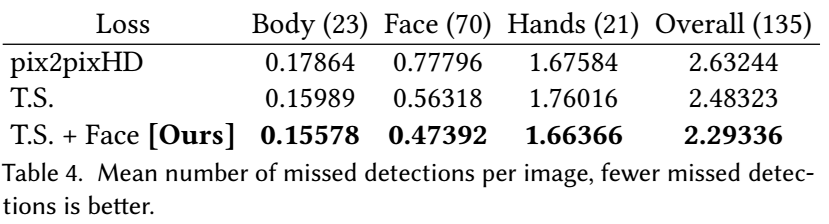
平均每幅图未检测到的连接点数量:
五、算法不足
-
姿态估计不准确导致生成的视频帧不准确、不连续,即使用时间平滑也无法完美解决这个问题
-
当输入的视频速度和训练的视频速度不相同时就会出现错误(作者使用120帧/秒的速度拍摄目标人物约20分钟)
-
实验结果还是会出现抖动和摇晃(对姿态图进行平滑处理会减少抖动现象)
参考博客
工程地址:https://carolineec.github.io/everybody_dance_now/
https://blog.csdn.net/gdymind/article/details/82696481
https://zhuanlan.zhihu.com/p/56808180
https://www.jiqizhixin.com/articles/2018-10-31-20
https://blog.csdn.net/weixin_39373480/article/details/86763715