何谓哈夫曼树?——
百度百科:给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
哈夫曼树的应用?——
哈夫曼编码 与 哈夫曼译码。
哈夫曼树为基础的项目?——
文件压缩。
文件压缩分两种:1.有损压缩。2.无损压缩。
哈夫曼树为核心算法的压缩方式是无损压缩。
其实我们windows常用的zip类型的压缩包底层,哈夫曼树就是核心算法之一(当然不全是)。
生成一棵哈夫曼树并进行哈夫曼编码,再用哈弗曼编码和哈夫曼树还原——
比如看这条语句:aaaabbbccd
1.首先统计文件字符出现次数——
a 4
b 3
c 2
d 1
2.构建huffman树——见图
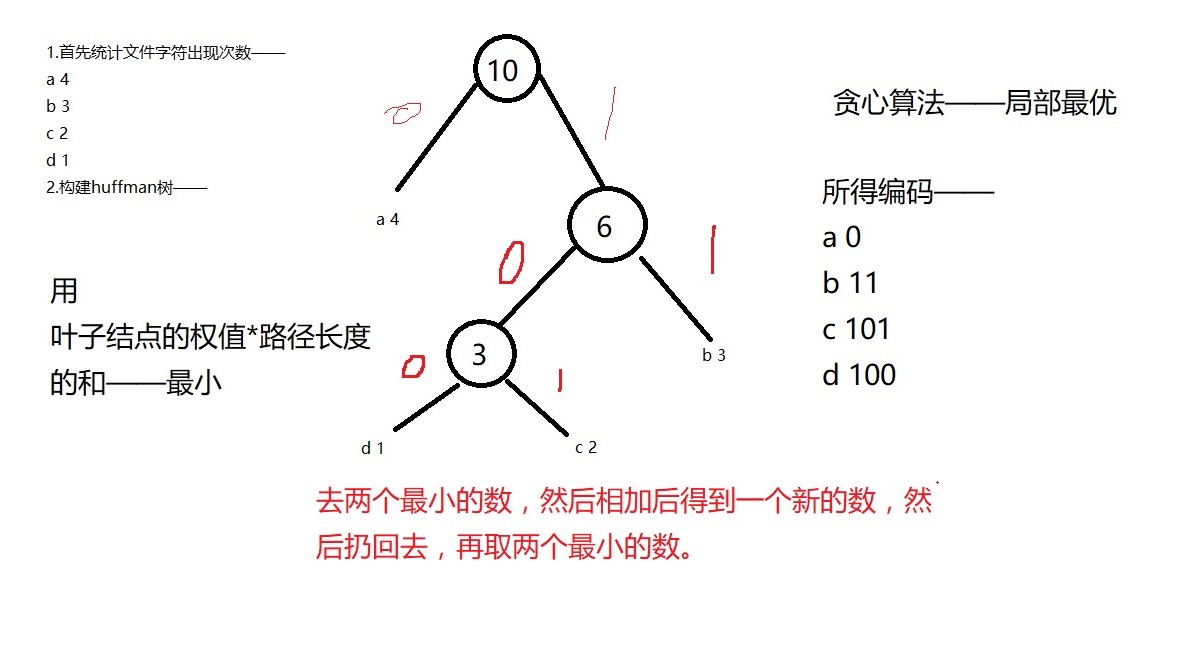
3.根据huffman树生成huffman编码(huffman code)
a --- 0 b --- 11 c --- 101 d --- 100
aaaabbbccd --- 0000111111101101100
4.压缩——
test.txt -----> test.huffman
每一个字符都有唯一的路劲,那么每一个字符都有唯一的编码,那么就可以替换完成无损压缩。
5.解压缩——
使用test.huffman------->test.txt
那么详细的让我们看代码——
.h文件——
该类模拟生成哈夫曼树。


1 #pragma once 2 3 #include<queue> 4 5 template<typename W> 6 struct HuffmanTreeNode 7 { 8 W val; 9 HuffmanTreeNode* right; 10 HuffmanTreeNode* left; 11 }; 12 13 //堆——优先级队列。priority_queue 14 15 template<typename W,typename T> 16 class HuffmanTree 17 { 18 //放在内部,方便且安全 19 typedef HuffmanTreeNode Node; 20 public: 21 //优先队列中放的是结点的指针。 22 //因为我放的是指针,但是比较的时候不能比较指针啊。 23 //所以在这里我需要写一个仿函数。 24 //让他用我的仿函数比较。但是要注意,仿函数是第三个模板参数,所以第二个模板参数还是要一样的。 25 26 //因为我们要杜绝出现出现次数为0的情况,这种情况不会被我们统计但是如果不管会占空间。 27 HuffmanTree(W* a,size_t n,const T& invalid); 28 29 //生成完哈夫曼树后那么接下来就是要生成哈夫曼编码了 30 //生成哈夫曼编码的方法 31 //1.三叉链法。添加一个parents指针在HuffmanNode结构体中,并且注意初始化。 32 //2.递归,左0右1。递归方法放在FileCompress类中。 33 34 //因为如果利用递归法,就很有可能需要在最后,将根的哈夫曼码变成当前结点结构体中的哈夫曼码。 35 //所以需要类提供一个接口 36 //返回root 37 Node* GetRoot(); 38 39 ~HuffmanTree(); 40 //因为涉及树,所以删除很有可能需要调用递归,要自觉习惯用一个函数来完成析构任务。 41 void destory(Node* root); 42 private: 43 //暂时用不到拷贝构造和=运算符重载 44 //所以直接用防拷贝的方法。 45 HuffmanTree(const HuffmanTree<W> &t); 46 HuffmanTree<W>& operator=(const HuffmanTree<T> &t); 47 protected: 48 Node* root; 49 };
接下来是用例案例——
模拟实现文件解析类。
1 #pragma once 2 3 #include<string> 4 #include <fstream> 5 #include <utility> 6 7 #include"HuffmanTree.h" 8 using namespace std; 9 10 //一个字符的信息—— 11 //我们会将这个值统计好传过去来生成哈夫曼树。 12 //但同时我们也知道哈夫曼树中有W的加的操作,>的操作,!=的操作。 13 //所以我们还需要重载+运算符,>运算符,!=运算符。 14 struct CharInfo 15 { 16 char _ch; 17 long long _count; 18 string _code; 19 CharInfo operator+(const CharInfo& info); 20 bool operator>(const CharInfo& info); 21 bool operator!=(const CharInfo& info); 22 CharInfo(long long count = 0) 23 :_count(count) 24 {} 25 }; 26 27 class FileCompress 28 { 29 public: 30 //构造函数就是写死,初始化哈希表。 31 FileCompress(); 32 //压缩 33 //1.首先要统计文件中字符出现的次数。 34 //2.用IO流的方式读字符串---因为是读,所以是ifstream,因为要从文件里读。 35 //C++reference里有些,构造函数就直接讲字符串当做参数(字符串实际为一个文件),读字符就用get。 36 void Compress(const char *file); 37 //解压缩 38 void Uncompress(const char *file); 39 void GenerateHuffmanCode(HuffmanTreeNode<CharInfo> *node); 40 protected: 41 CharInfo _hashInfos[256];//用来存放各个字符。 42 };
=============================================================================
今日完成,文件解析类和生成哈夫曼树类的定义实现(不包含编码解码和压缩部分)
同时因为我们用到了模板类,那么自然而然要回忆起模板类的相关概念——
模板类可以分离编译吗?
不能,为什么?C++编译器不支持,我们先了解分离式编译的概念,分离编译模式是指:一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件连接起来形成单一的可执行文件的过程。那么我们又知道,模板的代码其实并不能在编译汇编后生成对应的二进制代码的目标文件,必须要经过实例化,所以如果分离编译,编译器找不到.h文件中模板类的定义,那么那就只能寄希望于连接器,但是连接器链接了定义模板类中成员函数的.cpp文件后,就算它千辛万苦找到了obj,但是!!!没有实例化就没有二进制代码!!!连接器也惊了个呆,所以只能报出一个连接错误。
那么回到正题,继续:
1 #pragma once 2 3 #include<queue> 4 #include<vector> 5 6 template<typename W> 7 struct HuffmanTreeNode 8 { 9 W _val; 10 HuffmanTreeNode* _right; 11 HuffmanTreeNode* _left; 12 HuffmanTreeNode* _parent; 13 HuffmanTreeNode(const W& val) 14 :_val(val) 15 , _right(NULL) 16 , _left(NULL) 17 , _parent(NULL) 18 {} 19 }; 20 21 //堆——优先级队列。priority_queue 22 23 template<typename W> 24 class HuffmanTree 25 { 26 //放在内部,方便且安全 27 typedef HuffmanTreeNode<W> Node; 28 29 struct PtrNodeCompare 30 { 31 bool operator()(Node* n1, Node* n2) 32 { 33 return n1->_val > n2->_val; 34 } 35 }; 36 37 public: 38 //优先队列中放的是结点的指针。 39 //因为我放的是指针,但是比较的时候不能比较指针啊。 40 //所以在这里我需要写一个仿函数。 41 //让他用我的仿函数比较。但是要注意,仿函数是第三个模板参数,所以第二个模板参数还是要一样的。 42 43 //因为我们要杜绝出现出现次数为0的情况,这种情况不会被我们统计但是如果不管会占空间。 44 HuffmanTree(W* a, size_t n, const W& invalid) 45 { 46 priority_queue<Node*, vector<Node*>, PtrNodeCompare> q; 47 for (size_t i = 0; i < n; i++) 48 { 49 if (a[i] != invalid) 50 { 51 Node* _node = new Node(a[i]); 52 q.push(_node); 53 } 54 } 55 Node* _node = NULL; 56 57 while (q.size() > 1) 58 { 59 Node* node_left = q.top(); 60 q.pop(); 61 Node* node_right = q.top(); 62 q.pop(); 63 _node = new Node(node_left->_val + node_right->_val); 64 65 _node->_left = node_left; 66 _node->_right = node_right; 67 node_left->_parent = _node; 68 node_right->_parent = _node; 69 70 q.push(_node); 71 } 72 if (q.empty()) 73 _root = NULL; 74 else 75 _root = q.top(); 76 } 77 78 //生成完哈夫曼树后那么接下来就是要生成哈夫曼编码了 79 //生成哈夫曼编码的方法 80 //1.三叉链法。添加一个parents指针在HuffmanNode结构体中,并且注意初始化。 81 //2.递归,左0右1。递归方法放在FileCompress类中。 82 83 //因为如果利用递归法,就很有可能需要在最后,将根的哈夫曼码变成当前结点结构体中的哈夫曼码。 84 //所以需要类提供一个接口 85 //返回root 86 Node* GetRoot() 87 { 88 return _root; 89 } 90 91 ~HuffmanTree() 92 { 93 destory(_root); 94 _root = NULL; 95 } 96 //因为涉及树,所以删除很有可能需要调用递归,要自觉习惯用一个函数来完成析构任务。 97 void destory(Node* root) 98 { 99 if (root == NULL) 100 return; 101 102 destory(root->_left); 103 destory(root->_right); 104 105 delete root; 106 } 107 private: 108 //暂时用不到拷贝构造和=运算符重载 109 //所以直接用防拷贝的方法。 110 HuffmanTree(const HuffmanTree<W> &t); 111 HuffmanTree<W>& operator=(const HuffmanTree<W> &t); 112 protected: 113 Node* _root; 114 };
1 #include"FileCompress.h" 2 3 CharInfo CharInfo::operator+(const CharInfo& info) 4 { 5 CharInfo ret; 6 ret._count = _count + info._count; 7 return ret; 8 } 9 bool CharInfo::operator>(const CharInfo& info) 10 { 11 return _count > info._count; 12 } 13 bool CharInfo::operator!=(const CharInfo& info) 14 { 15 return _count != info._count; 16 } 17 18 FileCompress::FileCompress() 19 { 20 for (size_t i = 0; i < 256; i++) 21 { 22 _hashInfos[i]._ch = i; 23 _hashInfos[i]._count = 0; 24 _hashInfos[i]._code = ""; 25 } 26 } 27 void FileCompress::Compress(const char *file) 28 { 29 string _str = file; 30 ifstream f(_str); 31 char _c; 32 while ((_c = f.get()) != EOF) 33 _hashInfos[_c - '�']._count++; 34 //得到一棵哈夫曼树 35 HuffmanTree<CharInfo> MyHuffman(_hashInfos, 256,CharInfo(0)); 36 //编码 37 GenerateHuffmanCode(MyHuffman.GetRoot()); 38 } 39 void FileCompress::Uncompress(const char *file) 40 {} 41 //递归法 42 typedef HuffmanTreeNode<CharInfo> Node; 43 void FileCompress::GenerateHuffmanCode(Node *node) 44 { 45 //得到根节点,一直所有有哈夫曼码的成员都是叶子节点。 46 if (node == NULL)//空 47 return; 48 if (node->_left == NULL && node->_right == NULL)//叶子 49 { 50 _hashInfos[node->_val._ch - '�']._code = (node->_val)._code; 51 } 52 if (node->_left != NULL) 53 { 54 node->_left->_val._code = node->_val._code + '0'; 55 GenerateHuffmanCode(node->_left); 56 } 57 if (node->_right != NULL) 58 { 59 node->_right->_val._code = node->_val._code + '1'; 60 GenerateHuffmanCode(node->_right); 61 } 62 }