一、DGA域名原理
- 僵尸网络(Botnet):互联网上在蠕虫、木马、后门工具等,传统恶意代码形态的基础上发展、融合而产生的一种新型攻击方法。
- DNS(Domain Name System) :基于 UDP 的应用层协议。主要用途是将一个域名解析成 IP 地址,这个过程叫做域名解析 (Name resolution)。
- 域名生成算法(Domain Generation Algorithm):是一种利用随机字符来生成C&C域名,从而逃避域名黑名单检测的技术手段。
|
僵尸网络&恶意软等程序,随着检测手段的更新(在早期,僵尸主机通产采用轮询的方法访问硬编码的C&C域名或IP来访问服务器获取域名,但是这种方式在安全人员进行逆向之后会得到有效的屏蔽),黑客们也升级了肉鸡的C&C手段;用DGA算法在终端生成大量备选域名,而攻击者与恶意软件运行同一套DGA算法,生成相同的备选域名列表。 当需要发动攻击的时候,选择其中少量进行注册,便可以建立通信,并且可以对注册的域名应用速变IP技术,快速变换IP,从而域名和IP都可以进行快速变化。目前,黑客攻击者为了防止恶意域名被发现,会使用Domain Flux或者IP Flux来快速生成大量的恶意域名。(Domain Flux是通过不断变换域名,指向同一个IP,IP Flux是只有一个域名,不断变换IP,一个域名可以使用多个IP)。 很显然,在这种方式下,传统基于黑名单的防护手段无法起作用,一方面,黑名单的更新速度远远赶不上DGA域名的生成速度,另一方面,防御者必须阻断所有的DGA域名才能阻断C2通信,因此,DGA域名的使用使得攻击容易,防守困难。 |
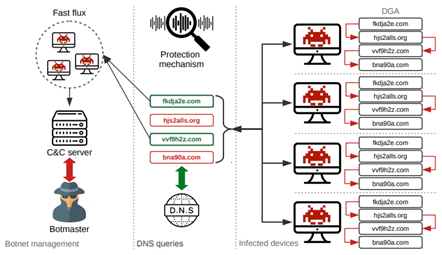
二、DGA分类
DGA算法由两部分构成,种子(算法输入)和算法,可以根据种子和算法对DGA域名进行分类
种子分类:
1.基于时间的种子(Time dependence)。DGA算法将会使用时间信息作为输入,如:感染主机的系统时间,http响应的时间等。
2.是否具有确定性(Determinism)。主流的DGA算法的输入是确定的,因此AGD可以被提前计算,但是也有一些DGA算法的输入是不确定的,如:Bedep[4]以欧洲中央银行每天发布的外汇参考汇率作为种子,Torpig[5]用twitter的关键词作为种子,只有在确定时间窗口内注册域名才能生效。
算法分类:
现有DGA生成算法一般可以分为如下4类:
1.基于算术。该类型算法会生成一组可用ASCII编码表示的值,从而构成DGA域名,流行度最高。
2.基于哈希。用哈希值的16进制表示产生DGA域名,被使用的哈希算法常有:MD5,SHA256。
3.基于词典。该方式会从专有词典中挑选单词进行组合,减少域名字符上的随机性,迷惑性更强,字典内嵌在恶意程序中或者从公有服务中提取。
4.基于排列组合。对一个初始域名进行字符上的排列组合。
DGA域名存活时间:
DGA域名的存活时间一般较短,大部分域名的存活时间为1-7天
三、检测方法
3.1 收集数据
3.2 数据准备
3.2.1 数据分类
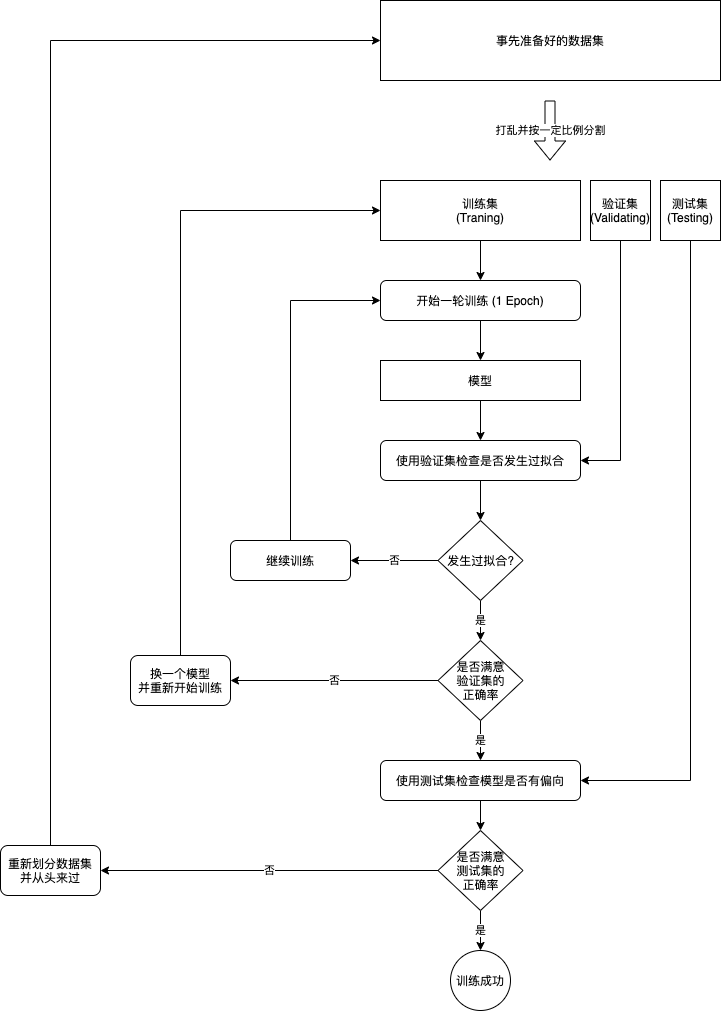
- 训练集 (Training Set):训练集中的输入与输出用于传给模型并且调整模型的参数【60%】
- 验证集 (Validating Set): 验证集中的输入与输出不会参与训练,用于在经过每一轮训练后判断模型在遇到未知的输入时可以得出的正确率,如果模型针对训练集可以得出 99 % 的正确率,但针对验证集只能得出 50 % 的正确率,那么就可以判断发生了过拟合【20%】
- 测试集 (Testing Set): 测试集用于在最终训练完成后判断模型是否过度偏向于训练集与验证集中的数据,如果针对测试集都可以得出比较高的正确率,那么就可以说这个模型训练成功了【20%】
3.2.2 数值正规化(Normalization):
例如一个输入数值的取值范围在 0 ~ 10 的时候,我们可以把数值全部除以 10,用 0 代表最小的值,用 1 代表最大的值,这个手法可以改善模型的学习速度与提升最终的效果。
3.2.3输入批次:
- 计算机不会有足够的内存处理它们
- 防止过拟合
3.3 选择模型
- 选择算法
3.4 训练
- 运行就行了,数据质量和算法选择才是重点
3.5 评估
- 通过验证数据集和测试数据集,准确率、召回率、F值
3.6 调整模型参数
- 给模型的参数 (非固定部分) 随机赋值,然后给模型传入预先准备好的输入,然后模型返回预测的输出,第一次因为参数是随机的,返回的预测输出与正确输出可能会差很远。
- 接下来你需要纠正模型,把预测输出的数值与正确输出的数值通过某种方法得到它们的相差值 (也叫损失 - Loss),然后根据损失来调整模型的参数 (修改参数使得损失接近 0),让下一次模型的预测输出的数值更接近正确输出的数值。
- 如果把事先准备的所有输入 (批次) 都传给了模型,并且根据模型的预测输出与正确输出调整了模型的参数,那么就可以说经过了一轮训练 (1 Epoch),通常我们需要经过好几轮训练才能达到理想的效果。
- 评价模型是否达到理想的效果通常会使用正确率 (Accuracy, 很多文章会缩写成 Acc),例如传入 100 个输入给模型,模型返回的 100 个预测输出中有 99 个与正确输出是一致的,那么正确率就是 99 %。如果模型足够强大,我们可以让模型针对参与训练的输入达到 100 % 的正确率,但这并不能说明模型训练成功,我们还需要使用没有参与训练的输入与输出来评价模型是否成功摸索出规律。
- 如果模型能力不足,或者用了与业务不匹配的模型,那么模型会给出很低的正确率,并且经过再多训练都不会改善,这个时候我们就需要换一个模型了。模型通过训练达到很高的正确率又称收敛 (Converge),我们首先需要确定模型能收敛,再确定模型是否能成功摸索出规律。
3.7 预测
- 找一个真实的场景搞一下
代码如下:
【参考】:
文献:
https://www.secrss.com/articles/14369
https://github.com/360netlab/DGA
https://www.cnblogs.com/zkweb/p/12642710.html
DGA数据:
https://osint.bambenekconsulting.com/feeds/
https://data.netlab.360.com/dga/
http://s3.amazonaws.com/alexa-static/top-1m.csv.zip
LSTM https://github.com/endgameinc/dga_predict
CNN https://twitter.com/keeghin