HadoopHA
1.zookeeper配置
zoo.cfg


# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/module/zookeeper-3.4.10/datas
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
server.101=hadoop101:2888:3888
server.102=hadoop102:2888:3888
server.103=hadoop103:2888:3888
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
bin/zkEnv.sh
#!/usr/bin/env bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # This script should be sourced into other zookeeper # scripts to setup the env variables # We use ZOOCFGDIR if defined, # otherwise we use /etc/zookeeper # or the conf directory that is # a sibling of this script's directory ZOOBINDIR="${ZOOBINDIR:-/usr/bin}" ZOOKEEPER_PREFIX="${ZOOBINDIR}/.." if [ "x$ZOOCFGDIR" = "x" ] then if [ -e "${ZOOKEEPER_PREFIX}/conf" ]; then ZOOCFGDIR="$ZOOBINDIR/../conf" else ZOOCFGDIR="$ZOOBINDIR/../etc/zookeeper" fi fi if [ -f "${ZOOCFGDIR}/zookeeper-env.sh" ]; then . "${ZOOCFGDIR}/zookeeper-env.sh" fi if [ "x$ZOOCFG" = "x" ] then ZOOCFG="zoo.cfg" fi ZOOCFG="$ZOOCFGDIR/$ZOOCFG" if [ -f "$ZOOCFGDIR/java.env" ] then . "$ZOOCFGDIR/java.env" fi if [ "x${ZOO_LOG_DIR}" = "x" ] then ZOO_LOG_DIR="/opt/module/zookeeper-3.4.10/logs" fi if [ "x${ZOO_LOG4J_PROP}" = "x" ] then ZOO_LOG4J_PROP="ERROR,CONSOLE" fi if [ "$JAVA_HOME" != "" ]; then JAVA="$JAVA_HOME/bin/java" else JAVA=java fi #add the zoocfg dir to classpath CLASSPATH="$ZOOCFGDIR:$CLASSPATH" for i in "$ZOOBINDIR"/../src/java/lib/*.jar do CLASSPATH="$i:$CLASSPATH" done #make it work in the binary package #(use array for LIBPATH to account for spaces within wildcard expansion) if [ -e "${ZOOKEEPER_PREFIX}"/share/zookeeper/zookeeper-*.jar ]; then LIBPATH=("${ZOOKEEPER_PREFIX}"/share/zookeeper/*.jar) else #release tarball format for i in "$ZOOBINDIR"/../zookeeper-*.jar do CLASSPATH="$i:$CLASSPATH" done LIBPATH=("${ZOOBINDIR}"/../lib/*.jar) fi for i in "${LIBPATH[@]}" do CLASSPATH="$i:$CLASSPATH" done #make it work for developers for d in "$ZOOBINDIR"/../build/lib/*.jar do CLASSPATH="$d:$CLASSPATH" done #make it work for developers CLASSPATH="$ZOOBINDIR/../build/classes:$CLASSPATH" case "`uname`" in CYGWIN*) cygwin=true ;; *) cygwin=false ;; esac if $cygwin then CLASSPATH=`cygpath -wp "$CLASSPATH"` fi #echo "CLASSPATH=$CLASSPATH"
在数据结点配置myid,和zoo.cfg集群server配置相对应,创建datas,logs目录,并在datas下配置myid
myid
101
2.Hadoop使用zookeeper实现高可用的配置
etc/core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>hadoop102:2181,hadoop103:2181,hadoop101:2181</value> </property> </configuration>
etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- 集群中NameNode节点都有哪些 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop101:9000</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop102:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop101:50070</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop102:50070</value> </property> <!-- 指定NameNode元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop102:8485;hadoop103:8485;hadoop101:8485/mycluster</value> </property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh无秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/layman/.ssh/id_rsa</value> </property> <!-- 声明journalnode服务器存储目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/module/hadoop-2.7.2/data/jn</value> </property> <!-- 关闭权限检查--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
etc/yarn-site.xml
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop102</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop103</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop102:2181,hadoop103:2181,hadoop103:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
etc/mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop101:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop101:19888</value> </property> <!--第三方框架使用yarn计算的日志聚集功能 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop101:19888/jobhistory/logs</value> </property> </configuration>
etc/slaves
hadoop101
hadoop102
hadoop103
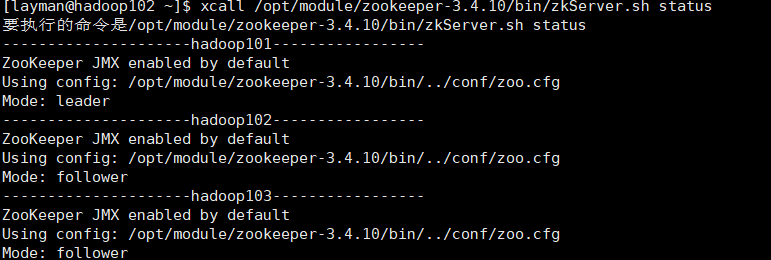
先启动zk,在启动hdfs,在启动yarn;本次在从单机zookeeper的时候可以正常使用,搭建集群就结点报错,后来才发现是zkServer开启,然后会有pid,而三台机器配置集群,只有两台及以上正常,才能正常使用(要么不配集群,要配就保证半数以上正常开启)!!!
3.zookeeper的javaAPI
pom.xml(注意配置slf4j,官网会给出解决方案)
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.shun</groupId> <artifactId>Zookeeper</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13</version> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.10</version> </dependency> <dependency> <groupId>org.apache.cassandra</groupId> <artifactId>cassandra-all</artifactId> <version>0.8.1</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> </exclusions> </dependency> </dependencies> </project>
TestZK.java
import org.apache.zookeeper.CreateMode; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.ZooDefs.Ids; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.data.Stat; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.util.List; public class TestZK { private String connectString="hadoop101:2181,hadoop102:2181"; private int sessionTimeout=6000; private ZooKeeper zooKeeper; // zkCli.sh -server xxx:2181 @Before public void init() throws Exception { // 创建一个zk的客户端对象 zooKeeper = new ZooKeeper(connectString, sessionTimeout, new Watcher() { //回调方法,一旦watcher观察的path触发了指定的事件,服务端会通知客户端,客户端收到通知后 // 会自动调用process() @Override public void process(WatchedEvent event) { } }); System.out.println(zooKeeper); } @After public void close() throws InterruptedException { if (zooKeeper !=null) { zooKeeper.close(); } } // ls @Test public void ls() throws Exception { Stat stat = new Stat(); List<String> children = zooKeeper.getChildren("/", null, stat); System.out.println(children); System.out.println(stat); } // create [-s] [-e] path data @Test public void create() throws Exception { zooKeeper.create("/idea", "hello".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } // get path @Test public void get() throws Exception { byte[] data = zooKeeper.getData("/idea", null, null); System.out.println(new String(data)); } // set path data @Test public void set() throws Exception { zooKeeper.setData("/idea", "hi".getBytes(), -1); } // delete path @Test public void delete() throws Exception { zooKeeper.delete("/idea", -1); } // rmr path @Test public void rmr() throws Exception { String path="/data"; //先获取当前路径中所有的子node List<String> children = zooKeeper.getChildren(path, false); //删除所有的子节点 for (String child : children) { zooKeeper.delete(path+"/"+child, -1); } zooKeeper.delete(path, -1); } // 判断当前节点是否存在 @Test public void ifNodeExists() throws Exception { Stat stat = zooKeeper.exists("/idea1", false); System.out.println(stat==null ? "不存在" : "存在"); } }
TestZKWatch
import org.apache.zookeeper.KeeperException; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.ZooKeeper; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.util.List; import java.util.concurrent.CountDownLatch; public class TestZKWatch { private String connectString="hadoop101:2181,hadoop102:2181"; private int sessionTimeout=6000; private ZooKeeper zooKeeper; // zkCli.sh -server xxx:2181 @Before public void init() throws Exception { // 创建一个zk的客户端对象 zooKeeper = new ZooKeeper(connectString, sessionTimeout, new Watcher() { //回调方法,一旦watcher观察的path触发了指定的事件,服务端会通知客户端,客户端收到通知后 // 会自动调用process() @Override public void process(WatchedEvent event) { //System.out.println(event.getPath()+"发生了以下事件:"+event.getType()); //重新查询当前路径的所有新的节点 } }); System.out.println(zooKeeper); } @After public void close() throws InterruptedException { if (zooKeeper !=null) { zooKeeper.close(); } } // ls path watch @Test public void lsAndWatch() throws Exception { //传入true,默认使用客户端自带的观察者 zooKeeper.getChildren("/data2",new Watcher() { //当前线程自己设置的观察者 @Override public void process(WatchedEvent event) { System.out.println(event.getPath()+"发生了以下事件:"+event.getType()); List<String> children; try { children = zooKeeper.getChildren("/data2", null); System.out.println(event.getPath()+"的新节点:"+children); } catch (KeeperException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } }); //客户端所在的进程不能死亡 while(true) { Thread.sleep(5000); System.out.println("我还活着......"); } } private CountDownLatch cdl=new CountDownLatch(1); // 监听器的特点: 只有当次有效 // get path watch @Test public void getAndWatch() throws Exception { //zooKeeper = new ZooKeeper(connectString, sessionTimeout, true) 会自动调用Before里面的process //是Connect线程调用 byte[] data = zooKeeper.getData("/data2", new Watcher() { // 是Listener线程调用 @Override public void process(WatchedEvent event) { System.out.println(event.getPath()+"发生了以下事件:"+event.getType()); //减一 cdl.countDown(); } }, null); System.out.println("查询到的数据是:"+new String(data)); //阻塞当前线程,当初始化的值变为0时,当前线程会唤醒 cdl.await(); } // 持续watch: 不合适 @Test public void lsAndAlwaysWatch() throws Exception { //传入true,默认使用客户端自带的观察者 zooKeeper.getChildren("/data2",new Watcher() { // process由listener线程调用,listener线程不能阻塞,阻塞后无法再调用process //当前线程自己设置的观察者 @Override public void process(WatchedEvent event) { System.out.println(event.getPath()+"发生了以下事件:"+event.getType()); System.out.println(Thread.currentThread().getName()+"---->我还活着......"); try { lsAndAlwaysWatch(); } catch (Exception e) { e.printStackTrace(); } } }); //客户端所在的进程不能死亡 while(true) { Thread.sleep(5000); System.out.println(Thread.currentThread().getName()+"---->我还活着......"); } } // 持续watch: 不合适 @Test public void testLsAndAlwaysWatchCurrent() throws Exception { lsAndAlwaysWatchCurrent(); //客户端所在的进程不能死亡 while(true) { Thread.sleep(5000); System.out.println(Thread.currentThread().getName()+"---->我还活着......"); } } @Test public void lsAndAlwaysWatchCurrent() throws Exception { //传入true,默认使用客户端自带的观察者 zooKeeper.getChildren("/data2",new Watcher() { // process由listener线程调用,listener线程不能阻塞,阻塞后无法再调用process //当前线程自己设置的观察者 @Override public void process(WatchedEvent event) { System.out.println(event.getPath()+"发生了以下事件:"+event.getType()); System.out.println(Thread.currentThread().getName()+"---->我还活着......"); try { //递归调用 lsAndAlwaysWatchCurrent(); } catch (Exception e) { e.printStackTrace(); } } }); } }