https://blog.csdn.net/laizi_laizi/article/details/105519290
上一篇写到head部分就感觉太长了,还是分开来写:FCOS官方代码详解(一):Architecture(backbone)
这一篇就继续把architecture中的fcos_head分析一下,脑海中一直要有这图的印象: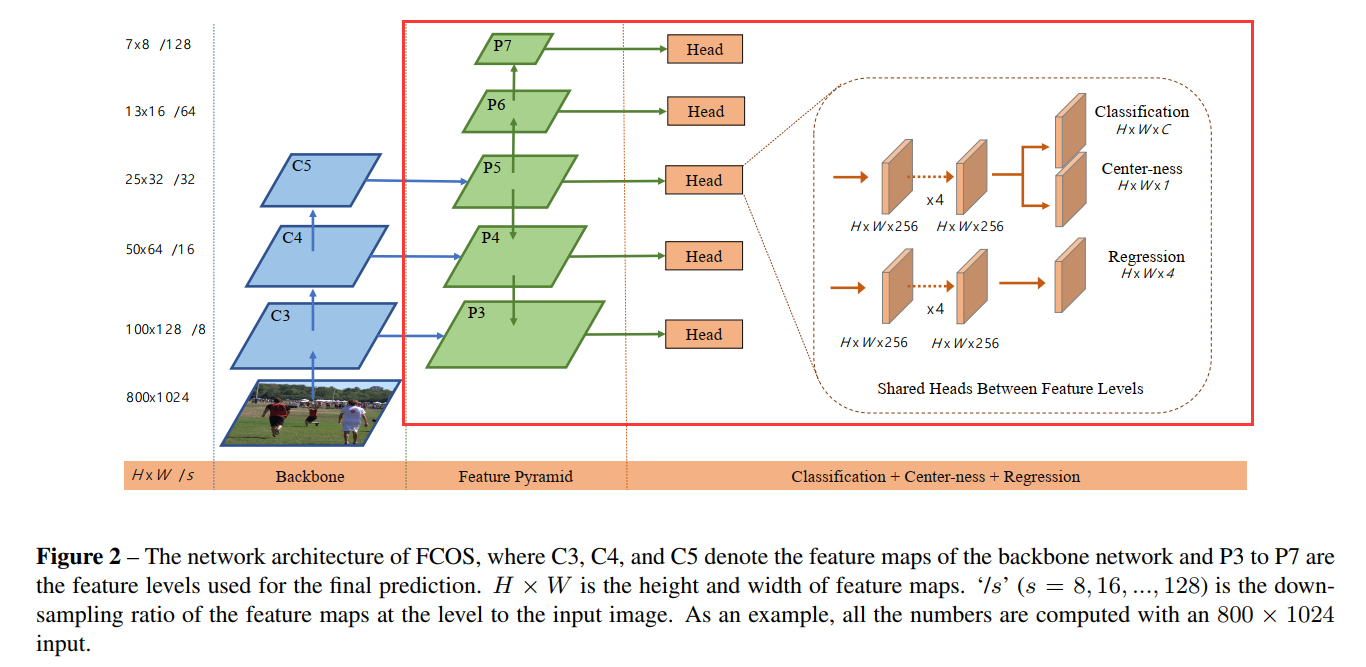
fcos_head
在类GeneralizedRCNN初始化的时候还有这么一句:self.rpn = build_rpn(cfg, self.backbone.out_channels),其实这里没改过来,实际构造的是fcos_head,返回的是build_fcos(cfg, in_channels),具体代码在fcos_core/modeling/rpn/fcos/fcos.py
然后build_fcos返回的是FCOSModule
def build_fcos(cfg, in_channels):
return FCOSModule(cfg, in_channels)
- 1
- 2
看一下FCOSModule()的初始化部分
class FCOSModule(torch.nn.Module):
"""
Module for FCOS computation. Takes feature maps from the backbone and
FCOS outputs and losses. Only Test on FPN now.
"""
def __init__(self, cfg, in_channels):
super(FCOSModule, self).__init__()
head = FCOSHead(cfg, in_channels) # 构造fcos的头部
box_selector_test = make_fcos_postprocessor(cfg)
loss_evaluator = make_fcos_loss_evaluator(cfg)
self.head = head
self.box_selector_test = box_selector_test
self.loss_evaluator = loss_evaluator
self.fpn_strides = cfg.MODEL.FCOS.FPN_STRIDES # eg:[8, 16, 32, 64, 128]
def forward(self, images, features, targets=None): # 调用的时候:self.rpn(images, features, targets)
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
那就转过去看一下FCOSHead:
class FCOSHead(torch.nn.Module):
def __init__(self, cfg, in_channels):
"""
Arguments:
in_channels (int): number of channels of the input feature
这个就是fpn每层的输出通道数,根据之前分析,都是一样的,如256
"""
super(FCOSHead, self).__init__()
# TODO: Implement the sigmoid version first.
num_classes = cfg.MODEL.FCOS.NUM_CLASSES - 1 # eg:80
self.fpn_strides = cfg.MODEL.FCOS.FPN_STRIDES # eg:[8, 16, 32, 64, 128]
self.norm_reg_targets = cfg.MODEL.FCOS.NORM_REG_TARGETS # eg:False 直接回归还是归一化后回归
self.centerness_on_reg = cfg.MODEL.FCOS.CENTERNESS_ON_REG # eg:False centerness和哪个分支共用特征
self.use_dcn_in_tower = cfg.MODEL.FCOS.USE_DCN_IN_TOWER # eg:False
cls_tower = []
bbox_tower = []
# eg: cfg.MODEL.FCOS.NUM_CONVS=4头部共享特征时(也称作tower)有4层卷积层
for i in range(cfg.MODEL.FCOS.NUM_CONVS):
if self.use_dcn_in_tower and
i == cfg.MODEL.FCOS.NUM_CONVS - 1:
conv_func = DFConv2d
else:
conv_func = nn.Conv2d
# cls_tower和bbox_tower都是4层的256通道的3×3的卷积层,后加一些GN和Relu
cls_tower.append(
conv_func(
in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1,
bias=True
)
)
cls_tower.append(nn.GroupNorm(32, in_channels))
cls_tower.append(nn.ReLU())
bbox_tower.append(
conv_func(
in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1,
bias=True
)
)
bbox_tower.append(nn.GroupNorm(32, in_channels))
bbox_tower.append(nn.ReLU())
self.add_module('cls_tower', nn.Sequential(*cls_tower))
self.add_module('bbox_tower', nn.Sequential(*bbox_tower))
# cls_logits就是网络的直接分类输出结果,shape:[H×W×C]
self.cls_logits = nn.Conv2d(
in_channels, num_classes, kernel_size=3, stride=1,
padding=1
)
# bbox_pred就是网络的回归分支输出结果,shape:[H×W×4]
self.bbox_pred = nn.Conv2d(
in_channels, 4, kernel_size=3, stride=1,
padding=1
)
# centerness就是网络抑制低质量框的分支,shape:[H×W×1]
self.centerness = nn.Conv2d(
in_channels, 1, kernel_size=3, stride=1,
padding=1
)
# initialization 这些层里面的卷积参数都进行初始化
for modules in [self.cls_tower, self.bbox_tower,
self.cls_logits, self.bbox_pred,
self.centerness]:
for l in modules.modules():
if isinstance(l, nn.Conv2d)