https://blog.csdn.net/u010417185/article/details/52119863#
https://blog.csdn.net/hjimce/article/details/49248231
lmdb用于单标签数据。为了简单起见,我后面通过一个性别分类作为例子,进行相关数据制作讲解。
1、数据准备
首先我们要准备好训练数据,然后新建一个名为train的文件夹和一个val的文件夹:

train文件存放训练数据,val文件存放验证数据。然后我们在train文件下面,把训练数据猫、狗图片各放在一个文件夹下面:
同样的我们在val文件下面也创建文件夹:
两个文件也是分别存我们用于验证的图片数据猫与狗图像文件。我们在test_cat下面存放了都是猫的图片,然后在test_dog下面存放的都是验证数据的狗图片。
将train 与 val 文件夹放到一个文件夹内,本文中放到了Data_Test文件夹内。
2、标签文件.txt文件制作.
接着我们需要制作一个train.txt、val.txt文件,这两个文件分别包含了我们上面的训练数据的图片路径,以及其对应的标签,如下所示。
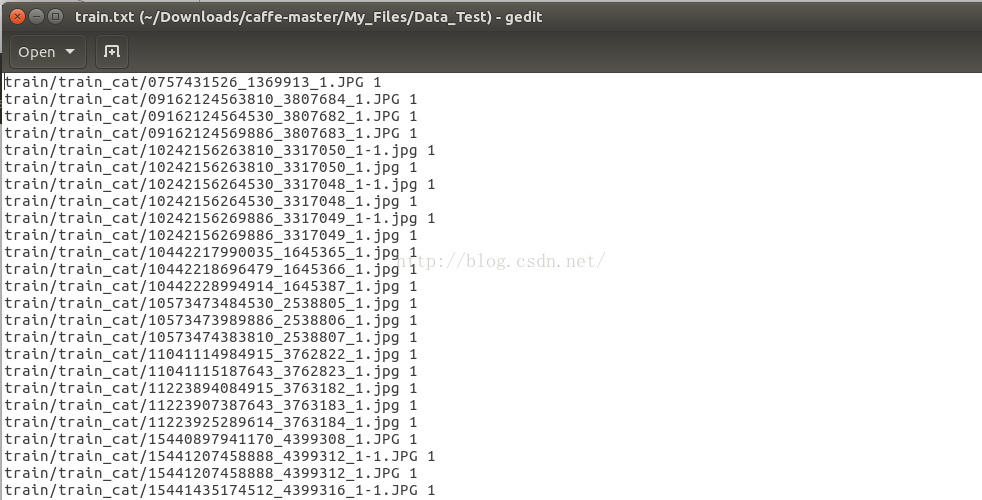
我们把猫图片标号为1,狗图片标记为0。标签数据文件txt的生成可以通过如下代码,通过扫描路径猫、狗下面的图片,得到标签文件train.txt和val.txt:
需要注意的是,路径与标签之间是一个空格,标签最好从0开始。
-
<pre class="python" name="code">#coding:utf-8
-
'''
-
Created on Jul 29, 2016
-
-
@author: sgg
-
'''
-
-
"<span style=""font-family:Arial;font-size:18px;"">"
-
"<span style=""font-size:18px;"">"
-
"<span style=""font-size:18px;"">"
-
import os
-
-
def IsSubString(SubStrList,Str):
-
flag=True
-
for substr in SubStrList:
-
if not(substr in Str):
-
flag=False
-
-
return flag
-
-
#扫面文件
-
def GetFileList(FindPath,FlagStr=[]):
-
FileList=[]
-
FileNames=os.listdir(FindPath)
-
if len(FileNames)>0:
-
for fn in FileNames:
-
if len(FlagStr)>0:
-
if IsSubString(FlagStr,fn):
-
fullfilename=os.path.join(FindPath,fn)
-
FileList.append(fullfilename)
-
else:
-
fullfilename=os.path.join(FindPath,fn)
-
FileList.append(fullfilename)
-
-
if len(FileList)>0:
-
FileList.sort()
-
-
return FileList
-
-
-
-
train_txt=open('train.txt','w')
-
#制作标签数据,如果是狗的,标签设置为0,如果是猫的标签为1
-
imgfile=GetFileList('train/train_cat')#将数据集放在与.py文件相同目录下
-
for img in imgfile:
-
str1=img+' '+'1'+' ' #用空格代替转义字符
-
train_txt.writelines(str1)
-
-
-
imgfile=GetFileList('train/train_dog')
-
for img in imgfile:
-
str2=img+' '+'0'+' '
-
train_txt.writelines(str2)
-
train_txt.close()
-
-
-
#测试集文件列表
-
test_txt=open('val.txt','w')
-
#制作标签数据,如果是男的,标签设置为0,如果是女的标签为1
-
imgfile=GetFileList('val/test_cat')#将数据集放在与.py文件相同目录下
-
for img in imgfile:
-
str3=img+' '+'1'+' '
-
test_txt.writelines(str3)
-
-
-
imgfile=GetFileList('val/test_dog')
-
for img in imgfile:
-
str4=img+' '+'0'+' '
-
test_txt.writelines(str4)
-
test_txt.close()
-
-
print("成功生成文件列表")
注:本文中生成txt文件时,Data_Test文件夹与生成文件列表的代码.py文件位于同一个目录下。
3、生成lmdb数据
接着我们的目的就是要通过上面的四个文件(两个txt文件列表、train与val两个图库),把图片的数据和其对应的标签打包起来,打包成lmdb数据格式:
在caffe-master创建My_Files文件夹,然后将caffe-master下的imagenet文件夹的create_imagenet.sh复制到该文件夹下进行修改,进行训练和测试路径的设置,运行该sh.
注意:这里是对.sh文件进行修改,在终端打开该文件后进行修改并保存。这里为了排版所以代码类型选择了Python代码类型。
-
<pre class="python" name="code">#!/usr/bin/env sh
-
# Create the imagenet lmdb inputs
-
# N.B. set the path to the imagenet train + val data dirs
-
set -e
-
-
-
EXAMPLE=My_Files/Build_lmdb #生成模型训练数据文件夹,即create_imagenet.sh所在文件夹
-
DATA=My_Files/Data_Test #python脚本处理数据路径,即生成的文件列表.txt文件所在文件夹
-
TOOLS=build/tools #caffe的工具库,不用更改
-
-
TRAIN_DATA_ROOT=<span style="font-size:14px;">/home/sgg/workspace/caffe_learn/scr/Data_Test/</span> #待处理的训练数据
-
VAL_DATA_ROOT=<span style="font-size:14px;">/home/sgg/workspace/caffe_learn/scr/Data_Test/</span> #待处理的验证数据
-
-
-
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
-
# already been resized using another tool.
-
RESIZE=true #是否需要对图片进行resize
-
if $RESIZE; then
-
RESIZE_HEIGHT=256
-
RESIZE_WIDTH=256
-
else
-
RESIZE_HEIGHT=0
-
RESIZE_WIDTH=0
-
fi
-
-
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
-
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
-
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path"
-
"where the ImageNet training data is stored."
-
exit 1
-
fi
-
-
if [ ! -d "$VAL_DATA_ROOT" ]; then
-
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
-
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path"
-
"where the ImageNet validation data is stored."
-
exit 1
-
fi
-
-
echo "Creating train lmdb..."
-
-
rm -rf $EXAMPLE/train_lmdb
-
rm -rf $EXAMPLE/val_lmdb #删除已存在的lmdb格式文件,若在已存在lmdb格式的文件夹下再添加lmdb文件,会出现错误
-
-
GLOG_logtostderr=1 $TOOLS/convert_imageset
-
--resize_height=$RESIZE_HEIGHT
-
--resize_width=$RESIZE_WIDTH
-
--shuffle
-
$TRAIN_DATA_ROOT
-
$DATA/train.txt
-
$EXAMPLE/train_lmdb
-
-
-
echo "Creating val lmdb..."
-
-
GLOG_logtostderr=1 $TOOLS/convert_imageset
-
--resize_height=$RESIZE_HEIGHT
-
--resize_width=$RESIZE_WIDTH
-
--shuffle
-
$VAL_DATA_ROOT
-
$DATA/val.txt
-
$EXAMPLE/val_lmdb
-
-
echo "Done."
-
这里对程序中所涉及的几个路径做简单说明:
先通过几张图了解一下每个文件夹所包含的内容与位置:
1、训练与测试图像库,即 train 与 val 文件夹所在位置,可以通过查看属性来确定其位置,本文中其位置是位于/home/sgg/workspace/caffe_learn/scr/Data_Test下
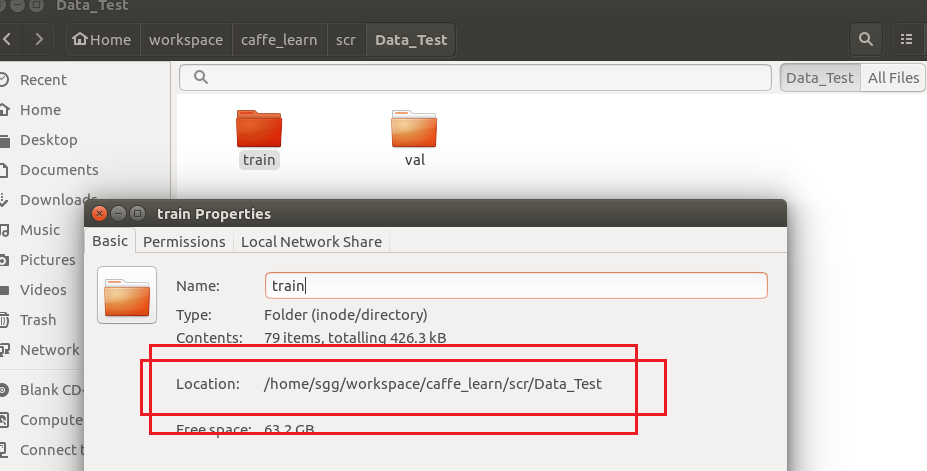
2、生成的txt文件,即 train.txt 与 test.txt 文件所在位置,可以通过查看属性来确定其位置,本文中其位置是位于/home/sgg/Downloads/caffe-master/My_Files/Data_Test下
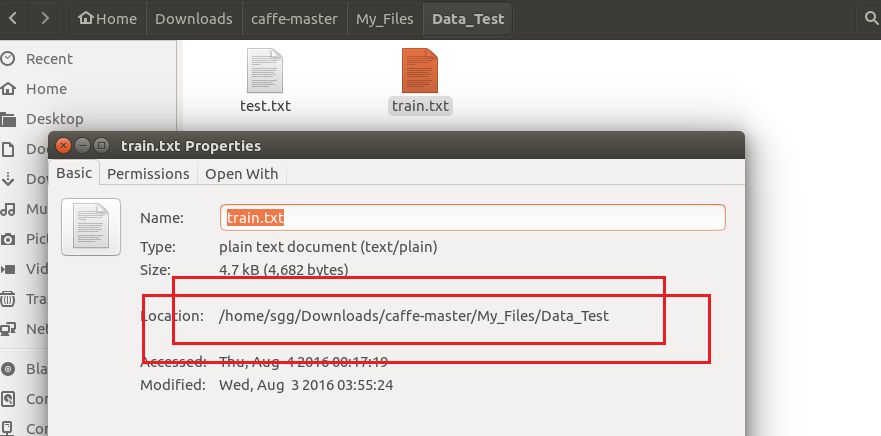
3、生成lmdb的.sh文件,即 进行修改后的create_imagenet.sh文件所在位置,可以通过查看属性来确定其位置,本文中其位置是位于/home/sgg/Downloads/caffe-master/My_Files/Build_lmdb下
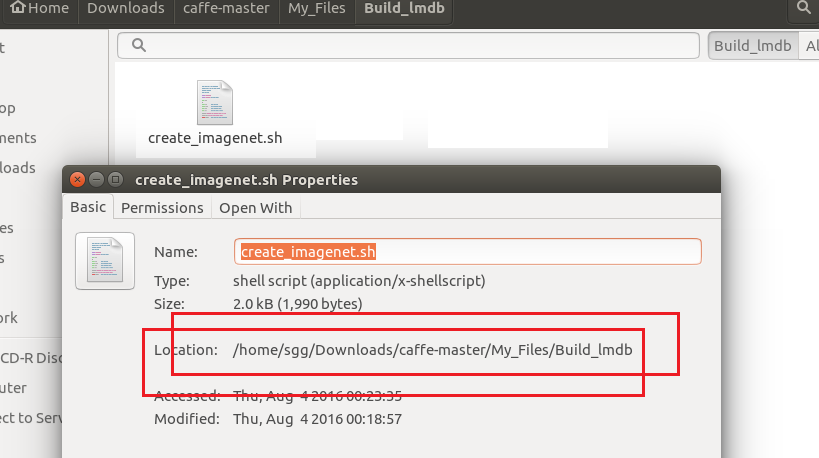
4、生成后的lmdb格式文件,即 生成的train_lmdb与val_lmdb文件夹所在位置,其位置与生成文件create_imagenet.sh位于同一目录下,本文中其位置是位于/home/sgg/Downloads/caffe-master/My_Files/Build_lmdb下
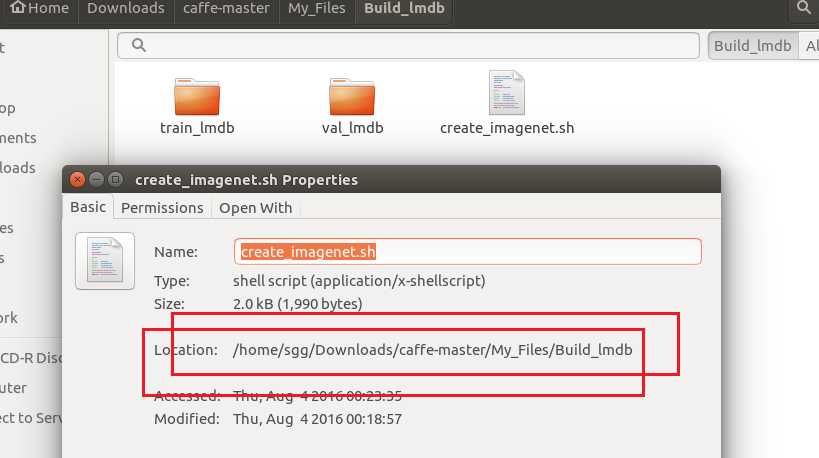
正式介绍文件中的几个路径值:
1、EXAMPLE
EXAMPLE 表示生成模型训练数据文件夹,即create_imagenet.sh所在文件夹
本文设为EXAMPLE=My_Files/Build_lmdb ,其中My_Files文件夹位于caffe-master文件夹下
2、DATA
DATA 表示python脚本处理数据路径,即生成的文件列表.txt文件所在文件夹
本文设为 DATA=My_Files/Data_Test
注:(1)本文开始为了测试DATA 值的设定,在该目录下直接拷贝了eclipse工作空间下的Data_Test文件,所以这里要注意这里是含有Data_Test文件夹的。
(2)该DATA路径直接写为 My_Files/Data_Test ,不用将其变为 /home/sgg/Downloads/caffe-master/My_Files/Data_Test ,写成这样是错误的。具体原因尚不明确。
3、TOOLS
TOOLS 表示caffe的工具库,为 TOOLS=build/tools 不用更改
4、TRAIN_DATA_ROOT
TRAIN_DATA_ROOT 表示待处理的训练数据,即 train 训练图像库所在位置。
注:
(1)这里需要写具体地址,这就是为什么看地址时需要通过文件的属性进行查看具体地址,写的地址为属性中所显示的地址。
像本文train 训练图像库所在位置为 /home/sgg/workspace/caffe_learn/scr/Data_Test/train/ ,我们经常在终端定位时写的比较简单,在终端定位时的地址为: /workspace/caffe_learn/scr/Data_Test/train/ ,会直接省略 /home/sgg ,但如果在程序中省略的话是出错误的,所以这里的地址要是完整地址。
(2)由于我们在生成txt 文件时路径中包含了 “train” 与" val ",所以在 .sh 文件中写路径时去掉了train,将其路径定义为 /home/sgg/workspace/caffe_learn/scr/Data_Test/ ,TRAIN_DATA_ROOT所设定的值与 txt 文件中路径两者合起来是图像的整体路径。
5、VAL_DATA_ROOT
VAL_DATA_ROOT 表示待处理的验证数据,即 val 训练图像库所在位置,其要求与TRAIN_DATA_ROOT 相同。
4、验证生成的lmdb数据
通过运行上面的脚本,我们将得到文件夹train_lmdbval_lmdb:
方法一:
我们打开train_lmdb文件夹

并查看一下文件data.mdb数据的大小,如果这个数据包好了我们所有的训练图片数据,查一下这个文件的大小是否符合预期大小,如果文件的大小才几k而已,那么就代表你没有打包成功,估计是因为路径设置错误。
方法二:
通过代码将lmdb中的图像信息显示出来,即通过Python代码,将lmdb中的图像在重塑出来,同时也可以观察到图像的信息。具体代码如下:
-
#coding:utf-8
-
'''
-
Created on Aug 9, 2016
-
-
@author: sgg
-
'''
-
#加载必要的库
-
import matplotlib.pyplot as plt
-
import sys
-
from caffe.proto import caffe_pb2
-
import lmdb
-
import numpy
-
-
-
# 编写一个函数,将二进制的均值转换为python的均值
-
def read_lmdb(path,visualize = False):
-
env = lmdb.open(path,readonly=True)
-
-
x=[]
-
y=[]
-
with env.begin() as txn:
-
cursor = txn.cursor()
-
-
for key,value in cursor:
-
print 'key:',key
-
datum = caffe_pb2.Datum()#datum类型
-
#转换维datum
-
datum.ParseFromString(value)
-
#转换成numpy
-
#flat_x=numpy.fromstring(datum.dta,dtype=numpy.uint8)
-
flat_x=numpy.array(bytearray(datum.data))
-
#reshape大小
-
img_data = flat_x.reshape(datum.channels,datum.height,datum.width)
-
-
#读取datum数据
-
print img_data.shape
-
x.append(img_data)
-
y.append(datum.label)
-
if visualize:
-
img_data=img_data.transpose([1,2,0])
-
img_data = img_data[:,:,::-1]
-
plt.imshow(img_data)
-
plt.show()
-
print datum.label
-
-
-
-
-
#调用read_lmdb
-
read_lmdb("/home/sgg/Downloads/caffe-master/examples/sgg_datas/train_lmdb",True)
-
-
-
-
在生成过程中遇到了如下问题:
1、如果文件夹下含有lmdb格式的文件,那么生成时会出现错误,所以在生成之前需要对create_imagenet.sh 所在文件夹进行检查,删除之前的 lmdb 文件。代码中添加了代码,来辅助完成此检查:
-
rm -rf $EXAMPLE/train_lmdb
-
rm -rf $EXAMPLE/val_lmdb #删除已存在的lmdb格式文件,若在已存在lmdb格式的文件夹下再添加lmdb文件,会出现错误
首先,查看路径是否正确,若路径不正确,则需要更改相应的图像路径。再运行,看问题是否解决。
若问题还没有解决,则检查train.txt中,路径和标签之间是否只有一个空格!
在一些程序中,在对图像加标签时,标签与路径之间的空格使用转义字符 “ ”来生成,可是在生成txt中,路径与标签之间的距离往往多于一个空格,所以在生成标签文档时,程序中用空格代替转义字符 。如下方程序所示:
str1=img+' '+'1'+'
'将文件中的路径换成绝对路径,在尝试。