- 环境安装
- Windows:Anaconda---python环境的一键安装包(通过文件镜像安装比较快)
- Anaconda中Scripts文件夹:各种各样的可执行文件coda,pip等
- coda list:列出所有Anaconda安装的包
- 官方安装python
- 官网下载对应版本安装包,点击运行,下一步,增加环境变量即可
- PyCharm:python非常好用的IDE
- Linux
- 切换成root账户
-
sudo su
-
- 安装对应的依赖库和python3
- 切换成root账户
- Mac OS
- 安装Homebrew
- 安装python3
-
brew install python3
-
- Windows:Anaconda---python环境的一键安装包(通过文件镜像安装比较快)
-
MongoDB环境安装
-
Windows
-
官网下载安装包
-
打开--下一步--环境变量
- 建立存储数据的文件夹data,在其里面建立db文件夹
- shif+右键(bin目录下)--配置数据存储信息

- 在localhost:27017会启动成功
- 连接客户端:mongo
- 配置成服务--增加日志文件
- 可视化工具:Robomongo---下载安装即可
-
- Linux
- Mac OS
-
- Redis环境安装
- Windows:
- 下载msi文件---一直下一步就行
- 安装redis desktop---0.8.8版本的exe文件 ----可视化工具
- linux

- 进入客户端
- 进行远程链接和访问权限密码的设置
- Mac OS
- Windows:
- MySQL的环境安装
- Windows
- 下载msi安装包---下一步--设置默认端口和密码
- 会自动添加MySQL的服务
- 可视化工具MySQL-Front---直接百度安装就行
- Linux

- 修改配置文件

- 限制只能本地访问---注释掉即可
- Mac OS
- Windows
- pyhton多版本共存的问题
- 根据环境变量的搜索规则---将不同的python版本路径配置进环境变量,将python.exe改成python3.exe就不会名字冲突
- where python ----查找几个python
- Windows
- 将python.exe改成python3.exe---输入python3就只会调用python3--保留python.exe
- 将python2的版本改成python2.exe--保留pyhton.exe
- 依旧冲突的python.exe通过更改环境变量的顺序,让其先调用Anaconda中的python.exe即可
- pip的版本冲突也是完全一样的,通过改名实现多版本共存
- Linux和Mac OS

- 找路径

- 利用软链接实现多版本共存
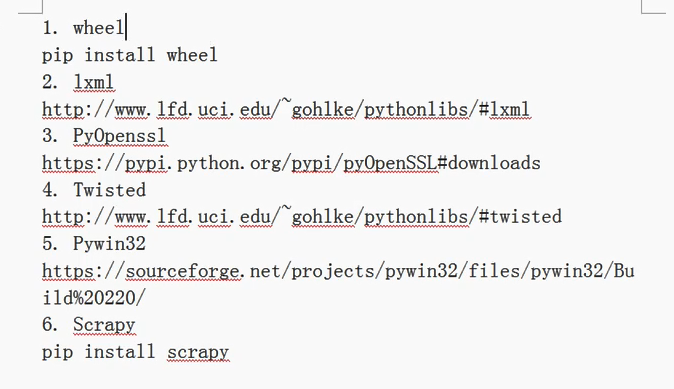
- 爬虫常用库的安装
- Windows
- urllib re---内置的库,不需要你安装
- requests
- pip install requests
- Selenium---主要是做自动化测试

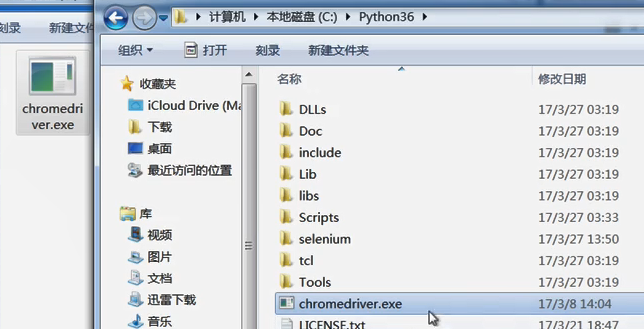
- 需要安装chromdriver---
- phantomjs
- 下载--解压-将bin目录加入环境变量即可
- lxml---xpath的解析方式
- beautifulsoup
- pyquery--网页解析库--跟jquery一样
- pymysql--存储库
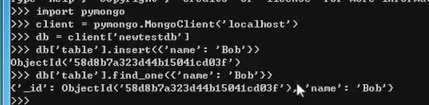
- pymongo
- redis
- flask--简单的web服务器
- django--web服务器框架
- pip3 install django
- jupyter--记事本--在线编程
- Linux Mac OS
- Windows
- 基础篇
- 什么是爬虫?
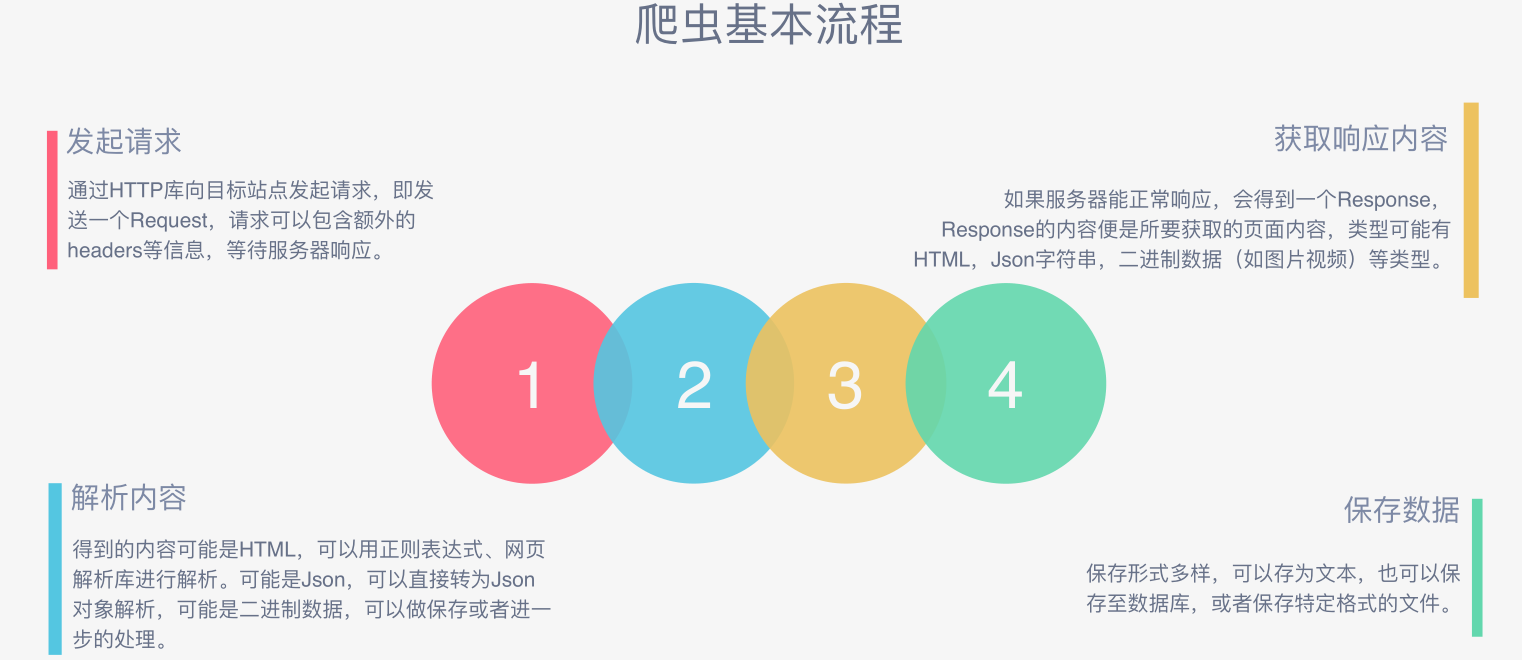
- 基本流程
- request和response
- request包含什么
- response包含什么
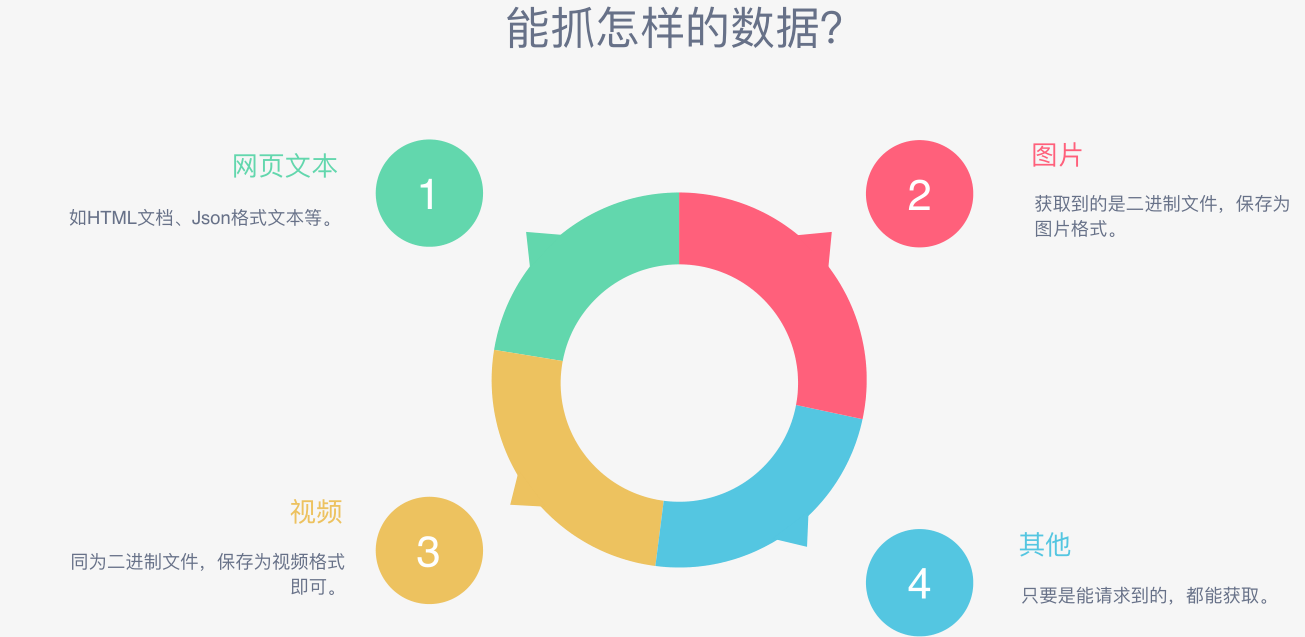
- 能抓什么数据
- 抓起来的数据,解析方式都有哪些
- 为什么我抓到的和浏览器看到的不一样?

- 分析,模仿,splash也是模拟
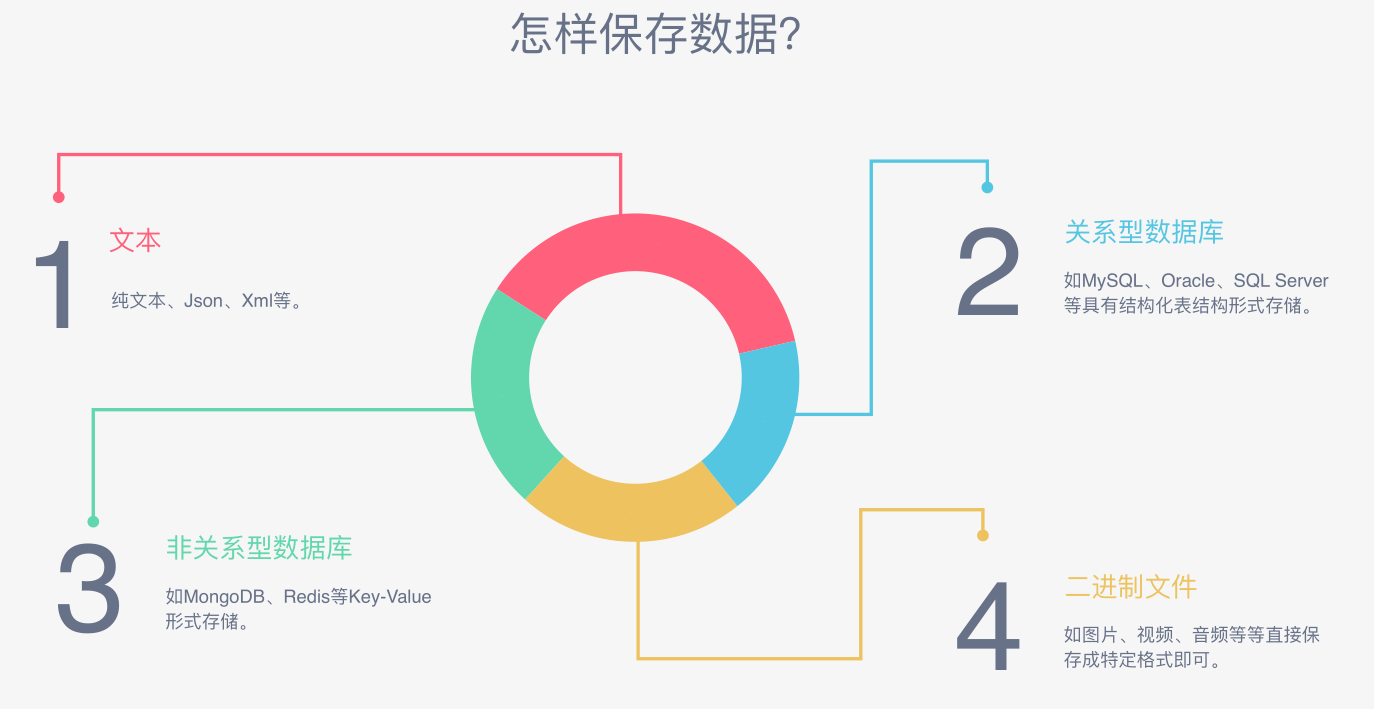
- 怎么保存数据
- Urllib库
- requests库
- 正则
- Selenium
- pyquery
- bs4
- 什么是爬虫?
- pySpider
- 安装
- pip install pyspider
- 启用pyspider所有组件
- pyspider all
- 安装
- scrapy