101.描述用浏览器访问 www.baidu.com 的过程
先要解析出 baidu.com 对应的 ip 地址
要先使用 arp 获取默认网关的 mac 地址
组织数据发送给默认网关(ip 还是 dns 服务器的 ip,但是 mac 地址是默认网关的 mac 地址)
默认网关拥有转发数据的能力,把数据转发给路由器
路由器根据自己的路由协议,来选择一个合适的较快的路径转发数据给目的网关
目的网关(dns 服务器所在的网关),把数据转发给 dns 服务器
dns 服务器查询解析出 baidu.com 对应的 ip 地址,并原路返回请求这个域名的 client
得到了 baidu.com 对应的 ip 地址之后,会发送 tcp 的 3 次握手,进行连接
使用 http 协议发送请求数据给 web 服务器
web 服务器收到数据请求之后,通过查询自己的服务器得到相应的结果,原路返回给浏览器。
浏览器接收到数据之后通过浏览器自己的渲染功能来显示这个网页。
浏览器关闭 tcp 连接,即 4 次挥手结束,完成整个访问过程
102.Python 函数调用的时候参数的传递方式是值传递还是引用传递
不可变参数用值传递:
像整数和字符串这样的不可变对象,是通过拷贝进行传递的,因为你无论如何都不可能在原处改变
不可变对象
可变参数是引用传递的:
比如像列表,字典这样的对象是通过引用传递、和 C 语言里面的用指针传递数组很相似,可变对象
能在函数内部改变。
103. Python 的内存管理机制及调优手段?
内存管理机制:引用计数、垃圾回收、内存池。
引用计数:
引用计数是一种非常高效的内存管理手段, 当一个 Python 对象被引用时其引用计数增加 1, 当
其不再被一个变量引用时则计数减 1. 当引用计数等于 0 时对象被删除。
垃圾回收 :
1. 引用计数
引用计数也是一种垃圾收集机制,而且也是一种最直观,最简单的垃圾收集技术。当 Python 的某
个对象的引用计数降为 0 时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如
某个新建对象,它被分配给某个引用,对象的引用计数变为 1。如果引用被删除,对象的引用计数为 0,
那么该对象就可以被垃圾回收。不过如果出现循环引用的话,引用计数机制就不再起有效的作用了
2. 标记清除
如果两个对象的引用计数都为 1,但是仅仅存在他们之间的循环引用,那么这两个对象都是需要被
回收的,也就是说,它们的引用计数虽然表现为非 0,但实际上有效的引用计数为 0。所以先将循环引
用摘掉,就会得出这两个对象的有效计数。
3. 分代回收(多次没清除的保留,下次不回收这些内容)
从前面“标记-清除”这样的垃圾收集机制来看,这种垃圾收集机制所带来的额外操作实际上与系统
中总的内存块的数量是相关的,当需要回收的内存块越多时,垃圾检测带来的额外操作就越多,而垃圾
回收带来的额外操作就越少;反之,当需回收的内存块越少时,垃圾检测就将比垃圾回收带来更少的额
外操作。
内存池:
1. Python 的内存机制呈现金字塔形状,-1,-2 层主要有操作系统进行操作;
2. 第 0 层是 C 中的 malloc,free 等内存分配和释放函数进行操作;
3. 第 1 层和第 2 层是内存池,有 Python 的接口函数 PyMem_Malloc 函数实现,当对象小于
256K 时有该层直接分配内存;
4. 第 3 层是最上层,也就是我们对 Python 对象的直接操作;
Python 在运行期间会大量地执行 malloc 和 free 的操作,频繁地在用户态和核心态之间进行切
换,这将严重影响 Python 的执行效率。为了加速 Python 的执行效率,Python 引入了一个内存池
机制,用于管理对小块内存的申请和释放。
Python 内部默认的小块内存与大块内存的分界点定在 256 个字节,当申请的内存小于 256 字节
时,PyObject_Malloc 会在内存池中申请内存;当申请的内存大于 256 字节时,PyObject_Malloc 的
行为将蜕化为 malloc 的行为。当然,通过修改 Python 源代码,我们可以改变这个默认值,从而改
变 Python 的默认内存管理行为
104.字典按照值排序
d = {'a': 3, 'b': 1, 'c': 2, 'd': 4}
# 有返回值
d_reverse = sorted(d.items(), key=lambda x:x[1], reverse=True)
d_sorted = sorted(d.items(), key=lambda x:x[1], reverse=False)
print(d_reverse,d_sorted)
105.输入某年某月某日,判断这一天是这一年的第几天?
# 今年的第几天
import datetime
year = int(input("请输入年份:"))
month = int(input("请输入月份:"))
day = int(input("请输入天数:"))
data1 = datetime.date(year=year, month=month, day=day)
data2 = datetime.date(year=year, month=1, day=1)
result = data1 - data2
# <class 'datetime.timedelta'> 1 day, 0:00:00
result = result.days + 1
print(result)
106.简述你对 input()函数的理解?
在 Python3 中,input()获取用户输入,不论用户输入的是什么,获取到的都是字符串类型的。
在 Python2 中,input()获取用户输入,不论用户输入的是什么,获取到的就是什么数据类型的。
107. 阅读下面的代码,写出 A0,A1 至 An 的最终值。
详情见:https://www.cnblogs.com/shuimohei/p/10232668.html
108.补充缺失的代码?
https://www.cnblogs.com/shuimohei/p/10232473.html
109.进程
进程:程序运行在操作系统上的一个实例,就称之为进程。进程需要相应的系统资源:内存、时间
片、pid。
https://www.cnblogs.com/shuimohei/p/10500266.html
https://www.cnblogs.com/shuimohei/p/10500299.html
110.下面这段代码的输出结果将是什么?请解释?
class Parent(object): x = 1 class Child1(Parent): pass class Child2(Parent): pass # 继承指向父类x所在地址:1635999904 print(id(Parent.x), id(Child1.x), id(Child2.x)) # 1 1 1 print(Parent.x, Child1.x, Child2.x) Child1.x = 2 # 1 2 1 print(Parent.x, Child1.x, Child2.x) Parent.x = 3 # 3 2 3 print(Parent.x, Child1.x, Child2.x)
111.简述read、readline、readlines的区别
read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读 取至文件结束为止,它范围为字符串对象
readline()从字面意思可以看出,该方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存
112、 面向对象中super的作用?
在子类派生出新的方法中重用父类的功能
113、 列举面向对象中特殊成员(带双下划线的特殊方法,如:__init__、等)
- # __new__ 可以调用其他类的构造方法或者直接返回别的对象来作为本类的实例。
- # __init__ 负责将类的实例化
- # __call__ 对象后面加括号,触发执行
- # __str__ print打印一个对象时触发
- # __repr__ 和__str__
- # __doc__ 类的注释,改属性是无法继承的
- # __getattr__ 在使用调用属性(方式.属性)不存在的时候触发
- # __setattr__ 添加/修改属性会触发它的执行
- #__delattr__ 删除属性的时候会触发
- # __delete__ 采用del删除属性时,触发
114.Python是如何进行内存管理的?
Python的内存管理是由Python得解释器负责的,开发人员可以从内存管理事务中解放出来,致力于应用程序的开发,这样就使得开发的程序错误更少,程序更健壮,开发周期更短
115.如何用Python删除一个文件?
使用os.remove(filename)或者os.unlink(filename);
116.Redis 存储的指纹过多怎么办
设置生存时间
定时清理
主从
持久化
117.文件备份
import os
#备份文件的路径
file_address = input("输入需要备份文件所在的路径:")
os.chdir(file_address)
#备份文件命名
file_name = input("请输入要备份文件的名字:")
if os.path.isfile(file_name):
new_file_name = file_name + ".backup"
old_file = open(file_name,"r")
new_file = open(new_file_name,"w")
old_file_data = old_file.read()
new_file.write(old_file_data)
old_file.close()
new_file.close()
print("备份成功!")
else:
print("您输入的文件不存在!")
运行结果:


118.求质数
num= input("请输入您要求质数的范围(以逗号结尾):")
down,up = num.split(',',1)
down,up = int(down),int(up)
if down < 2:
print("输入有误,请重新输入!")
num = input("请输入您要求质数的范围(以逗号结尾):")
down, up = num.split(',', 1)
down, up = int(down), int(up)
a = []
for i in range(down,up):
if i == 2:
a.append(i)
else:
for j in range(2,i):
if i % j == 0:
break
else:
a.append(i)
break
print(a)
运行结果:

119.以文件夹名称作为参数,返回该文件夹下所有文件的路径
'''
分析:
1.知道文件夹名称(假设是形如:E:\software\Notepad++),很显然可以通过OS模块去求
2.OS.listdir(sPath),列出文件夹内所有的文件和文件夹,以列表的形式返回(可以迭代)
3.将sPath的路径和求得的文件夹或文件的名字拼接,if判断该路径是否为文件夹,是则递归调用原函数,不是则写入列表
思考:
如果只知道文件夹名字(形如:Notepad++),怎么求得该文件夹的绝对路径,以及该文件夹中所有文件的路径
'''
def print_directory_contents(sPath):
"""
这个函数接受文件夹的名称作为输入参数,
返回该文件夹中文件的路径,
以及其包含文件夹中文件的路径。
"""
sPath_files = []
import os
for sSon in os.listdir(sPath):
sSonPath = os.path.join(sPath,sSon)
if os.path.isdir(sSonPath):
print_directory_contents(sSonPath)
else:
sPath_files.append(sSonPath)
return sPath_files
运行结果:

120.求运行结果
'''
分析:
1.列表解析:迭代机制的一种应用
语法:
[expression for iter_val in iterable]
[expression for iter_val in iterable if cond_expr]
2.zip函数:以可迭代的对象作为参数,将对应元素打包成一个元组,形如:zip([a,b],[c,d])→[(a,c),(b,d)]
dict函数:可以以可迭代方式创建字典,形如:dict([(a,b),(c,d)])→{a:b,c:d}
'''
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
A1 = range(10)
A2 = [i for i in A1 if i in A0]
A3 = [A0[s] for s in A0]
A4 = [i for i in A1 if i in A3]
A5 = {i:i*i for i in A1}
A6 = [[i,i*i] for i in A1]
'''
解答:
A0→A0=dict([("a",1),("b",2),("c",3),("d",4),("e",5])→A0={"a":1,"b":2,"c":3,"d":4,"e":5}
A1→A1=[0,1,2,3,4,5,6,7,8,9]
A2→
A2 = []
for i in A1:
if i in A0: #字典进行in判断的时候判断的是key
A2.append(i) →A2=[]
A3→
A3 = []
for s in A0:
A3.append(A0[s]) →A3=[1, 2, 3, 4, 5]
A4→
A4=[]
for i in A1:
if i in A3:
A4.append(i)→A4=[1, 2, 3, 4, 5]
A5→
A5 = {}
for i in A1:
A5.update({i:i*i})→A5={0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
A6→
A6 = []
for i in A1:
A6.append([i,i*i])→A6=[[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36], [7, 49], [8, 64], [9, 81]]
'''
运行结果:

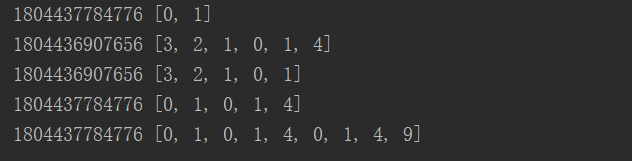
121.列表赋值面试题
'''
分析:
python赋值是通过指针来进行的。
很显然第一、三、四次调用都指向同一个列表,并未完成清空,
第二次调用只是指向了另一个列表,也未完成清空,很显然结果是累计的
结果:
[0, 1]
[3, 2, 1, 0, 1, 4]
[3, 2, 1, 0, 1]
[0, 1, 0, 1, 4]
[0, 1, 0, 1, 4, 0, 1, 4, 9]
'''
def f(x,l=[]):
for i in range(x):
l.append(i*i)
print(id(l),l)
f(2)
f(3,[3,2,1])
f(2,[3,2,1])
f(3)
f(4)
运行结果:
122.继承相关面试题
class A(object):
def go(self):
print("go A go!")
def stop(self):
print("stop A stop!")
def pause(self):
raise Exception("Not Implemented")
class B(A):
def go(self):
super().go()
print( "go B go!")
class C(A):
def go(self):
super().go()
print("go C go!")
def stop(self):
super().stop()
print("stop C stop!")
class D(B,C):
def go(self):
super().go()
print("go D go!")
def stop(self):
super().stop()
print("stop D stop!")
def pause(self):
print("wait D wait!")
class E(B,C): pass
a = A()
b = B()
c = C()
d = D()
e = E()
# 说明下列代码的输出结果
print("--------------")
a.go()
#"go A go!"
b.go()
#B继承A:"go A go!" "go B go!"
c.go()
#C继承A:"go A go!" "go C go!"
d.go()
#D继承B,C:从后往前C继承A:"go A go!" "go C go!" B继承A: "go B go!" "go D go!"只继承一次
e.go()
#E继承B,C:C继承A:"go A go!" "go C go!" B继承A:"go B go!"
print("-------------")
a.stop()
#"stop A stop!"
print('123')
b.stop()
#B继承A:B本身没有stop方法:"stop A stop!"
print("123")
c.stop()
#C继承A:"stop A stop!" "stop C stop!"
d.stop()
#D继承B,C:C继承A:"stop A stop!" "stop C stop!" "stop D stop!"
e.stop()
#E继承B,C:C继承A:"stop A stop!" "stop C stop!"
print("$$$$$$$$$$$$$$")
a.pause()
#直接抛出异常了,程序结束,后面的程序都不会执行了
# 关键字raise是用来抛出异常的,一旦抛出异常后,后续的代码将无法运行。这实际上的将不合法的输出直接拒之门外,避免黑客通过这种试探找出我们程序的运行机制,从而找出漏洞,获得非法权限。
print("!!!!!!!!!!!!")
b.pause()
c.pause()
d.pause()
e.pause()
运行结果:



123.对象组合和对象构造面试题(深度优先和广度优先的问题)
class Node(object):
def __init__(self,sName):
self._lChildren = []
self.sName = sName
def __repr__(self):
return "<Node '{}'>".format(self.sName)
def append(self,*args,**kwargs):
self._lChildren.append(*args,**kwargs)
def print_all_1(self):
print(self)
for oChild in self._lChildren:
oChild.print_all_1()
def print_all_2(self):
def gen(o):
lAll = [o,]
while lAll:
oNext = lAll.pop(0)
lAll.extend(oNext._lChildren)
yield oNext
for oNode in gen(self):
print(oNode)
oRoot = Node("root")
oChild1 = Node("child1")
oChild2 = Node("child2")
oChild3 = Node("child3")
oChild4 = Node("child4")
oChild5 = Node("child5")
oChild6 = Node("child6")
oChild7 = Node("child7")
oChild8 = Node("child8")
oChild9 = Node("child9")
oChild10 = Node("child10")
oRoot.append(oChild1)
oRoot.append(oChild2)
oRoot.append(oChild3)
oChild1.append(oChild4)
oChild1.append(oChild5)
oChild2.append(oChild6)
oChild4.append(oChild7)
oChild3.append(oChild8)
oChild3.append(oChild9)
oChild6.append(oChild10)
# 说明下面代码的输出结果
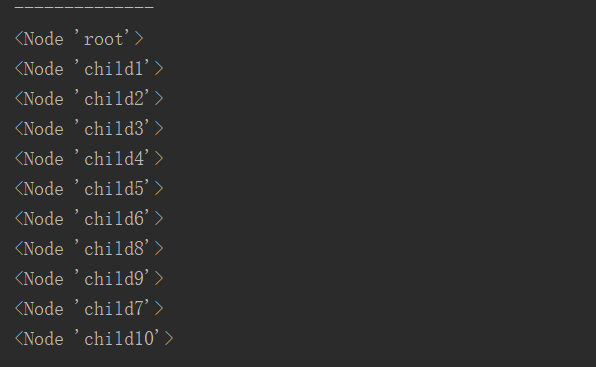
'''
就是print_all_1会以深度优先(depth-first)的方式遍历树(tree),而print_all_2则是宽度优先(width-first)
'''
oRoot.print_all_1()
'''
print()函数的调用顺序__str__ > __repe__ > object
先调用__repe__:<Node 'root'>
oRoot._lChildren:[oChild1]
oRoot.append(oChild1) <Node 'oChild1'>
oChild1.append(oChild4) <Node 'child4'>
oChild4.append(oChild7) <Node 'child7'>
oChild1.append(oChild5) <Node 'child5'>
oRoot.append(oChild2) <Node 'child2'>
oChild2.append(oChild6) <Node 'child6'>
oChild6.append(oChild10) <Node 'child10'>
oRoot.append(oChild3) <Node 'child3'>
oChild3.append(oChild8) <Node 'child8'>
oChild3.append(oChild9) <Node 'child9'>
'''
print("--------------")
oRoot.print_all_2()
'''
先调用__repe__:<Node 'root'>
oRoot._lChildren:
oRoot.append(oChild1) <Node 'child1'>
oRoot.append(oChild2) <Node 'child2'>
oRoot.append(oChild3) <Node 'child3'>
oChild1._lChildren:
oChild1.append(oChild4) <Node 'child4'>
oChild1.append(oChild5) <Node 'child5'>
oChild2._lChildren:
oChild2.append(oChild6) <Node 'child6'>
oChild3._lChildren:
oChild3.append(oChild8) <Node 'child8'>
oChild3.append(oChild9) <Node 'child9'>
oChild4._lChildren:
oChild4.append(oChild7) <Node 'child7'>
oChild5._lChildren: 无
oChild6._lChildren:
oChild6.append(oChild10) <Node 'child10'>
'''
运行结果:

124.简单的程序执行效率面试题
# 将下面的函数按照执行效率高低排序。它们都接受由0至1之间的数字构成的列表作为输入。这个列表可以很长。一个输入列表的示例如下:[random.random() for i in range(100000)]。你如何证明自己的答案是正确的。
def f1(lIn):
l1 = sorted(lIn)
l2 = [i for i in l1 if i<0.5]
return [i*i for i in l2]
def f2(lIn):
l1 = [i for i in lIn if i<0.5]
l2 = sorted(l1)
return [i*i for i in l2]
def f3(lIn):
l1 = [i*i for i in lIn]
l2 = sorted(l1)
return [i for i in l1 if i<(0.5*0.5)]
'''
先筛选肯定用时最短f2用时最短,f3最后才筛选用时最长(这点不太准确,算是猜的),执行效率的顺序是f2>f1>f3
f1和f3的效率需要准确的计算才能确定结果
'''
import random
import cProfile
lIn = [random.random() for i in range(100000)]
cProfile.run('f1(lIn)')# 7 function calls in 0.041 seconds
cProfile.run('f2(lIn)')# 7 function calls in 0.022 seconds
cProfile.run('f3(lIn)')# 7 function calls in 0.047 seconds
125.已知一个长度n的无序列表,元素均是数字,要求把所有间隔为d的组合找出来
def select_d(list,d):
# list = sorted(list)
sum = {}
for i in list:
if i+d in list:
sum[i] = i+d
return sum
list = [1,2,3,4,5,6,7,8,9,0,1213,12,31,2,13,21,21,221,11,10]
print(select_d(list,2))
运行结果:
{1: 3, 2: 4, 3: 5, 4: 6, 5: 7, 6: 8, 7: 9, 8: 10, 9: 11, 0: 2, 11: 13, 10: 12}
126.求小球下落的高度
题目:小东和三个朋友一起在楼上抛小球,他们站在楼房的不同层,假设小东站的楼层距离地面N米,球从他手里自由落下,每次落地后反跳回上次下落高度的一半,并以此类推知道全部落到地面不跳,求4个小球一共经过了多少米?(数字都为整数)
给定四个整数A,B,C,D,请返回所求结果。
100,90,80,70
返回:1020
下落的距离明显是个极限的问题,一个小球距离N米,下降距离一共经过N(2+1/2+1/4+1/8...)求极限等于3N
class Balls:
def calcDistanc(self,a,b,c,d):
return 3*(a+b+c+d)
if __name__=="__main__":
print(Balls().calcDistanc(100, 90, 80, 70))
、
127.集合求并集并排序
题目描述
输入描述:
每组输入数据分为三行,第一行有两个数字n,m(0 ≤ n,m ≤ 10000),分别表示集合A和集合B的元素个数。后两行分别表示集合A和集合B。每个元素为不超过int范围的整数,每个元素之间有个空格隔开。
输出描述:
针对每组数据输出一行数据,表示合并后的集合,要求从小到大输出,每个元素之间有一个空格隔开,行末无空格。
import sys
a = sys.stdin.readline().strip()
b = sys.stdin.readline().strip().split(' ')
c = sys.stdin.readline().strip().split(' ')
print(' '.join(sorted(set(b+c), key=int)))