1.代理服务器(中间人)
# -*- coding: utf8 -*-
import requests
if __name__ == '__main__':
url = "https://www.baidu.com"
# 1.设置代理地址
proxy = '163.204.246.126:9999'
# 需要验证
# proxy = '账号:密码@47.112.24.110:8226'
# 2.设置proxies
proxies = {
'http': "http://" + proxy,
# 'https': "https://" + proxy,
}
try:
response = requests.get(url, proxies=proxies, timeout=10)
print(response.content.decode())
except requests.exceptions.ConnectionError as e:
print("Error", e.args)
2.Cookie和Session
1.1:手动复制,最笨的方法
import requests
from urllib.parse import urlencode
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',
'cookie':'xxxx自己的cookie'
}
params = {
# 传入一些参数
}
# 将参数拼接在网址上
url = 'http://www.renren.com/972196941' + urlencode(params)
s = requests.Session()
response = s.get(url,headers=headers,verify=False).text
print(response)
1.2 账号密码自动获取cookie并登录---崔大大的-记得多学习
# coding: utf-8
import requests
from scrapy import Selector
from http.cookiejar import LWPCookieJar
session = requests.session()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
session.headers = headers
session.cookies = LWPCookieJar(filename='DouBanCookies.txt') # 实例化一个LWPCookieJar对象
def login():
name = input("输入账户:")
password = input("输入密码:")
url = "https://accounts.douban.com/j/mobile/login/basic"
data = {
"ck": "",
"name": name,
"password": password,
"remember": "True",
"ticket": "",
}
response = session.post(url, data=data)
print(response.text)
session.cookies.save()
verify_login()
def verify_login():
mine_url = "https://www.douban.com/mine/"
mine_response = session.get(mine_url)
selector = Selector(text=mine_response.text)
user_name = selector.css(".info h1 ::text").extract_first("")
print(f"豆瓣用户名:{user_name.strip()}")
def cookie_login():
try:
# 从文件中加载cookies(LWP格式)
session.cookies.load(ignore_discard=True)
print(session.cookies)
except Exception:
print("Cookies未能加载,使用密码登录")
login()
else:
verify_login()
if __name__ == "__main__":
cookie_login()
使用最常用的!!!!!
# 最常用的cookie使用
import requests
from urllib.parse import urlencode
# 实例化session
session = requests.session()
# 先发送post请求,获取cookie,在带上cookie
post_url = "http://www.renren.com/PLogin.do"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',
}
# name="email",name="password"
post_data = {
"email": "xxxx",
"password": "xxx",
}
session.post(post_url, headers=headers, data=post_data)
params = {
# 传入一些参数
}
# 将参数拼接在网址上
url = 'http://www.renren.com/972196941' + urlencode(params)
response = session.get(url, headers=headers, verify=False)
with open("renren.html", 'w', encoding='utf-8') as f:
f.write(response.content.decode())
print(response)
1.3 Fiddler抓取电脑代理
1.翻墙安装SwitchyOmega一个代理设置工具 ----Chrome的扩展
2.设置代理为Fiddler的地址和端口
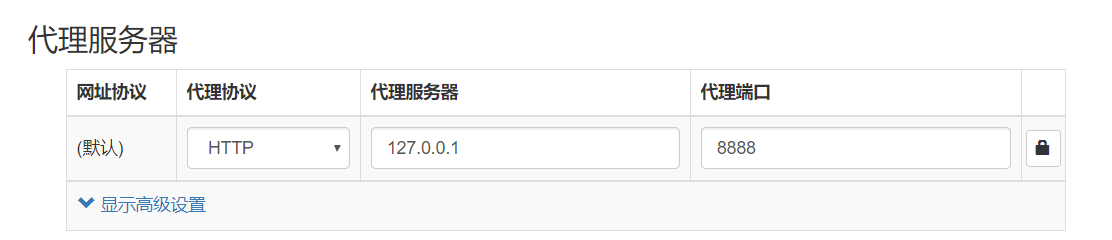
3.启用代理
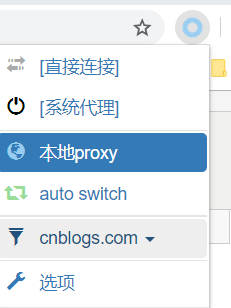
1.4 Fiddler抓取手机代理
1.查询本机的IP地址