HDFS由三个基本组件组成:NameNode,SecondaryName,DataNode,其思想类似于Linux的文件系统,可以进行类比。
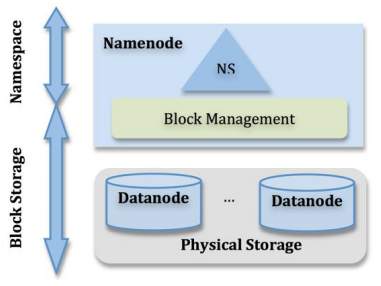
1.NameNode介绍:
1.管理整个文件系统的命名空间,内部维护了命名树。
2.存储元数据:文件层级关系,文件所有者及权限,每个文件由哪些文件块组成(但元信息中不包括每个块的位置)。内容通过fsimage及edits维护,后文会详述。
3.接受客户端请求
2.为什么HDFS倾向于存储大文件:
首先,NameNode中存储一条元信息需要200byte,而元信息是保存在NameNode的内存中的,不能分布式存储,文件越小,存储同样大小的内容元信息越大,NameNode的内存有可能会成为系统存储的瓶颈。
其次,大文件减少了磁盘的寻道时间。但是数据块过大也会出现问题,MapReduce框架通常会为每个数据块启动一个进程,数据块过大会使并行数量减少,降低任务处理效率。
3.元信息持久化:
fsimage是NameNode的元数据镜像文件,用于存储某一时段内存的元数据信息,而系统运行期间所有元信息的操作都保存在内存中并被持久化到另一个文件edits中,edits会被周期性合并进fsimage中。合并两个日志的操作显然会占用大量的CPU,内存及IO,而NameNode中的计算及存储资源是很宝贵的,因此,通常合并操作通常交给SecondaryNameNode(注意,SecondaryNameNode作用不是热备!)。而NameNode本身通常也不会参与MapReduce计算和数据存储。
4.单点问题:
可以发现,HDFS中NameNode是一个单点,除了定期保存fsimage用于故障恢复外,也可以在元数据写入同时将其实时同步到一个远程挂载的NFS上。
5.SecondaryNameNode作用:
1. 减少启动时NameNode合并日志的时间
2. 一定程度上减少了NameNode的单点问题
2.DataNode
1.负责存储数据块,响应客户端读写(注意,客户端直接读写DataNode,而非经过NameNode)。
2.根据NameNode发送的指令创建,删除和复制文件。
3.定期向NameNode发送心跳,报告文件块列表信息。
4.为了安全,提供了数据块冗余,默认为3个副本。数据块默认为64MB
5.数据完整性问题:
存储和处理数据时数据有可能发生错误或丢失,HDFS会对写入的数据计算校验和。
参考:
http://www.cnblogs.com/sunddenly/category/611923.html