内容来自《What Every Programmer Should Know About Memory》的 3.3.4 节 Multi-Processor Support。
这篇文章是按论文的格式写的,与其说是文章,说是书更加合适,毕竟总共有 114 页。作者 Ulrich Drepper 是真大牛,如果你想要在编程领域走的深的话,文章名说的一点也不夸张,内存是每个程序员都应该知道的。而且这篇文章的内容也确实配得上所有程序员都应该阅读的水平。
本文以直译为主,尽量不改变原文的意思。括号里一般是我的总结和理解。
3.3.4 Multi-Processor Support(原章节标题)
It is completely impractical to provide direct access from one processor to the cache of another processor. The connection is simply not fast enough, for a start. The practical alternative is to transfer the cache content over to the other processor in case it is needed. Note that this also applies to caches which are not shared on the same processor.
从一个处理器直接访问另一个处理器的缓存是完全不切实际的。无非是因为连接速度还不够快。实际的替代方案是,把当前缓存内容传输给其它需要的处理器。注意,这也适用于不在同一个处理器上共享的缓存。(简而言之,就是当前处理器可以得到其它处理器私有缓存里的内容。)
The question now is when does this cache line transfer have to happen? This question is pretty easy to answer: when one processor needs a cache line which is dirty in another processor’s cache for reading or writing. But how can a processor determine whether a cache line is dirty in another processor’s cache? Assuming it just because a cache line is loaded by another processor would be suboptimal (at best). Usually the majority of memory accesses are read accesses and the resulting cache lines are not dirty. Processor operations on cache lines are frequent (of course, why else would we have this paper?) which means broadcasting information about changed cache lines after each write access would be impractical.
现在的问题是什么时候必须进行缓存行的传输?这个问题很容易回答:当一个处理器需要读写一个缓存行,而这个缓存行在其它处理器的缓存中是脏的(即,被修改过)。但是处理器如何判断一个缓存行在其他处理器中是脏的呢?仅仅依据该缓存行被另一个处理器加载过不是最优的判断方式。通常,大多数内存访问都是读访问,因此产生的缓存行不是脏的。处理器操作缓存行是频繁的,这意味着在每次写访问之后广播缓存行的更改信息是不切实际的。
What developed over the years is the MESI cache coherency protocol (Modified, Exclusive, Shared, Invalid).The protocol is named after the four states a cache line can be in when using the MESI protocol:
这导致了 MESI 缓存一致性协议(修改的、独占的、共享的、无效的)的出现。该协议是以使用 MESI 协议时缓存行的四种状态命名的:
Modified: The local processor has modified the cache line. This also implies it is the only copy in any cache.
Exclusive: The cache line is not modified but known to not be loaded into any other processor’s cache.
Shared: The cache line is not modified and might exist in another processor’s cache.
Invalid: The cache line is invalid, i.e., unused.
修改的: 本地处理器修改了缓存行。这也意味着它是任何缓存中的唯一副本。
独占的: 缓存行没有被修改,而且知道该缓存行没有被其它任何处理器的缓存加载。
共享的: 缓存行没有被修改,而且该缓存行可能存在于另一个处理器的缓存中。(S 状态不要求精确,原因就是想尽可能的减小通信量)
无效的: 缓存行失效,即,不能使用。
This protocol developed over the years from simpler versions which were less complicated but also less efficient. With these four states it is possible to efficiently implement write-back caches while also supporting concurrent use of read-only data on different processors.
多年来,这个协议从简单的版本发展而来,简单的版本不那么复杂,但也不那么高效。有了这四种状态,就可以有效地实现回写缓存,同时还支持不同的处理器并发使用只读数据。
The state changes are accomplished without too much effort by the processors listening, or snooping, on the other processors’ work. Certain operations a processor performs are announced on external pins and thus make the processor’s cache handling visible to the outside. The address of the cache line in question is visible on the address bus. In the following description of the states and their transitions (shown in Figure 3.18) we will point out when the bus is involved.
通过处理器监听或嗅探其它处理器的工作,可以很容易的更改状态。处理器执行某些操作被公布在外部引脚上,因此处理器对缓存的操作是外部可见的。使用中的缓存行地址在地址总线上可见。在下面对状态及其转换的描述(如图3.18所示)中,我们将指出何时涉及到总线。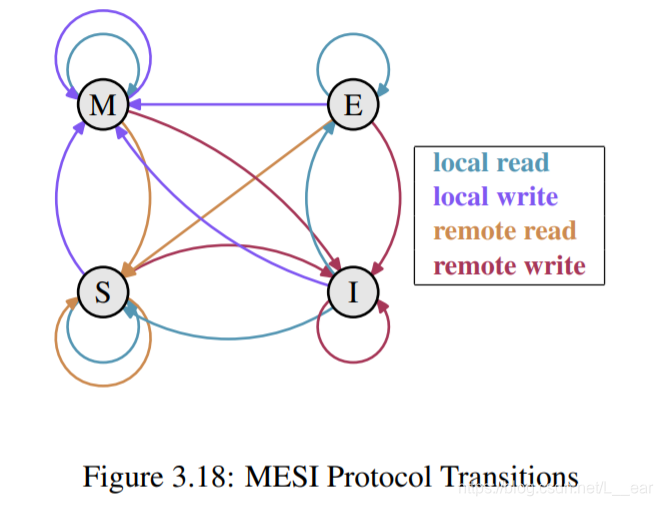
Initially all cache lines are empty and hence also Invalid. If data is loaded into the cache for writing the cache changes to Modified. If the data is loaded for reading the new state depends on whether another processor has the cache line loaded as well. If this is the case then the new state is Shared, otherwise Exclusive.
最初,所有缓存行都是空的,因此也是无效的。如果数据因为写而被载入缓存,对应缓存行改为 Modified。如果数据因为读而被载入缓存,则对应缓存行的状态取决于是否有另一个处理器也载入了该缓存行。如果载入了,则新状态是 Shared,否则是 Exclusive。
If a Modified cache line is read from or written to on the local processor, the instruction can use the current cache content and the state does not change. If a second processor wants to read from the cache line the first processor has to send the content of its cache to the second processor and then it can change the state to Shared. The data sent to the second processor is also received and processed by the memory controller which stores the content in memory. If this did not happen the cache line could not be marked as Shared. If the second processor wants to write to the cache line the first processor sends the cache line content and marks the cache line locally as Invalid. This is the infamous “Request For Ownership” (RFO) operation. Performing this operation in the last level cache, just like the I→M transition is comparatively expensive. For write-through caches we also have to add the time it takes to write the new cache line content to the next higher-level cache or the main memory, further increasing the cost.
如果本地处理器读取或写入一个状态为 Modified 的缓存行,则该缓存行的状态不会改变。如果另一个处理器想要从该缓存行读取数据,那么本地处理器必须将该缓存行的内容发送给另一个处理器,然后它可以将该缓存行的状态改为 Shared。发送给另一个处理器的数据也会被内存控制器接收和处理并存储到内存中(这里介绍了 M→S 的过程中,缓存行是什么时候被刷新到内存的)。如果没有发生这种情况,就不能将该缓存行标记为 Shared。如果另一个处理器想要写入该缓存行,那么本地处理器将发送该缓存行的内容并在本地将该缓存行标记为 Invalid。这就是声名狼藉的“所有权请求”(RFO)操作。这个操作会在最后一级缓存中执行,与 I→M 转换一样,开销比较大。对于写直达方式的缓存,我们还必须增加将新的缓存行内容写入下一个更高级缓存或主内存所需的时间,从而进一步增加成本。
If a cache line is in the Shared state and the local processor reads from it no state change is necessary and the read request can be fulfilled from the cache. If the cache line is locally written to the cache line can be used as well but the state changes to Modified. It also requires that all other possible copies of the cache line in other processors are marked as Invalid. Therefore the write operation has to be announced to the other processors via an RFO message. If the cache line is requested for reading by a second processor nothing has to happen. The main memory contains the current data and the local state is already Shared. In case a second processor wants to write to the cache line (RFO) the cache line is simply marked Invalid. No bus operation is needed.
如果缓存行处于 Shared 状态,本地处理器读这个缓存行,不需要更改状态。如果本地处理器是要写这个缓存行,则需要把状态改为 Modified。它还要求其它缓存中的该缓存行被改为 Invalid。因此,write 操作必须通过一条 RFO 消息通知其他处理器。如果这个缓存行正在被另一个处理器 read,则什么也不会发生。主内存包含当前数据,并且本地状态已经为 Shared。如果另一个处理器想要 write 这个缓存行(RFO),那么这个缓存行会被简单地标记为 Invalid。不需要总线操作。
(这一段表述的不是很清楚,我的理解是:1. 当前处理器要写缓存行时,另一个处理器正在读这个缓存行(不在同一个缓存中,但内容一样),那么在另一个处理器读缓存行结束前,当前处理器什么都不做。2. 当前处理器已经写了这个缓存行,并且广播了 RFO 消息。此时如果有另一个处理器想要写这个缓存行,则它不会去写,而是把这个缓存行标记为 Invalid。)
The Exclusive state is mostly identical to the Shared state with one crucial difference: a local write operation does not have to be announced on the bus. The local cache is known to be the only one holding this specific cache line. This can be a huge advantage so the processor will try to keep as many cache lines as possible in the Exclusive state instead of the Shared state. The latter is the fallback in case the information is not available at that moment. The Exclusive state can also be left out completely without causing functional problems. It is only the performance that will suffer since the E→M transition is much faster than the S→M transition.
独占状态除了本地 write 操作不需要在总线上广播之外,基本和共享状态相同。本地缓存已经知道它是唯一一个有此缓存行的缓存。这是一个巨大的优势,因此处理器将尽量保持尽可能多的缓存行为独占状态,而不是共享状态。后者是前者不得已情况下的后备选择。独占状态甚至可以被排除,也不会导致功能性问题。只有性能会受到影响,因为 E→M 转换要比 S→M 转换快得多。
From this description of the state transitions it should be clear where the costs specific to multi-processor operations are. Yes, filling caches is still expensive but now we also have to look out for RFO messages. Whenever such a message has to be sent things are going to be slow.
从对状态转换的描述中,应该可以清楚地看到多处理器操作的具体成本。是的,填充缓存仍然很昂贵,但是现在我们还必须注意 RFO 消息。每当需要发送这样的消息时,速度就会变慢。
There are two situations when RFO messages are necessary:
- A thread is migrated from one processor to another and all the cache lines have to be moved over to the new processor once.
- A cache line is truly needed in two different processors. (At a smaller level the same is true for two cores on the same processor. The costs are just a bit smaller. The RFO message is likely to be sent many times.)
有两种情况下,RFO 消息是必要的:
- 一个线程从一个处理器迁移到另一个处理器,所有缓存行必须迁移到新处理器一次。
- 一个缓存行确实需要在两个不同的处理器中。(在较小的级别上,同一处理器上的两个内核也是如此。成本只是小了一点。RFO 消息可能会被发送很多次。)
In multi-thread or multi-process programs there is always some need for synchronization; this synchronization is implemented using memory. So there are some valid RFO messages. They still have to be kept as infrequent as possible. There are other sources of RFO messages, though. In section 6 we will explain these scenarios. The Cache coherency protocol messages must be distributed among the processors of the system. A MESI transition cannot happen until it is clear that all the processors in the system have had a chance to reply to the message. That means that the longest possible time a reply can take determines the speed of the coherency protocol. Collisions on the bus are possible, latency can be high in NUMA systems, and of course sheer traffic volume can slow things down. All good reasons to focus on avoiding unnecessary traffic.
在多线程或多进程程序中,总是需要同步;这种同步是使用内存实现的。所以有一些有效的 RFO 消息。他们仍然必须保持尽可能少的频率。不过,还有其他的 RFO 消息来源。在第 6 节中,我们将解释这些场景。缓存一致性协议消息必须分布在系统的各个处理器之间。MESI 状态的转换必须发生在系统中所有处理器回复消息之后。这意味着一个应答可能花费的最长时间决定了一致性协议的速度。总线上的冲突是可能的,NUMA 系统的延迟可能很高,当然,庞大的通信量会降低速度。这些都是避免不必要通信的好理由。
后面是原文为了过渡到下一话题的内容,可以不管。
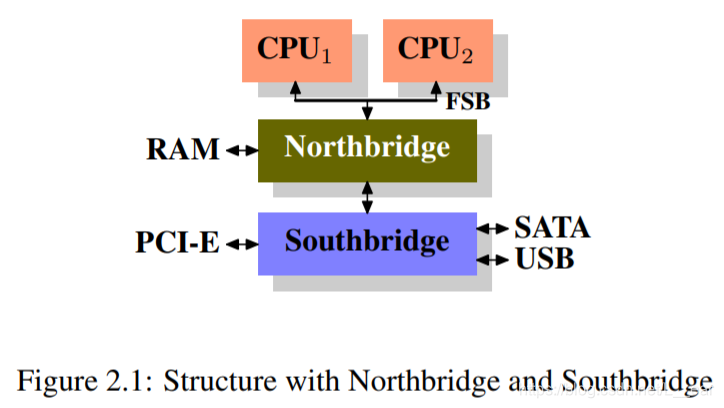
There is one more problem related to having more than one processor in play. The effects are highly machine specific but in principle the problem always exists: the FSB is a shared resource. In most machines all processors are connected via one single bus to the memory controller (see Figure 2.1). If a single processor can saturate the bus (as is usually the case) then two or four processors sharing the same bus will restrict the bandwidth available to each processor even more.
还有一个问题与使用多个处理器有关。这些影响是与机器高度相关的,但原则上问题总是存在:FSB 是一个共享资源。在大多数机器中,所有处理器通过一个总线连接到内存控制器(参见图 2.1)。如果单个处理器可以使总线饱和(通常是这种情况),那么共享同一总线的两个或四个处理器将进一步限制每个处理器的可用带宽。
Even if each processor has its own bus to the memory controller as in Figure 2.2 there is still the bus to the memory modules. Usually this is one bus but, even in the extended model in Figure 2.2, concurrent accesses to the same memory module will limit the bandwidth.
即使每个处理器都有自己的到内存控制器的总线,如图 2.2 所示,仍然有到内存模块的总线。通常这是一个总线,但是,即使在图 2.2 的扩展模型中,对同一个内存模块的并发访问也会限制带宽。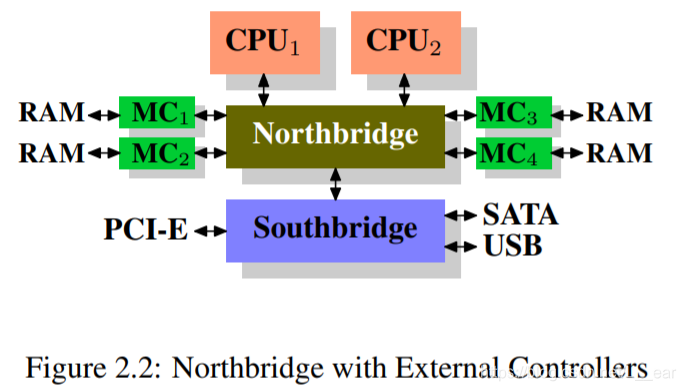
The same is true with the AMD model where each processor can have local memory. All processors can indeed concurrently access their local memory quickly, especially with the integrated memory controller. But multithread and multi-process programs–at least from time to time–have to access the same memory regions to synchronize.
AMD 模型也是如此,每个处理器都可以有本地内存。所有处理器确实可以并发地快速访问它们的本地内存,特别是使用集成的内存控制器。但是多线程和多进程程序—至少有时—必须访问相同的内存区域来进行同步。
Concurrency is severely limited by the finite bandwidth available for the implementation of the necessary synchronization. Programs need to be carefully designed to minimize accesses from different processors and cores to the same memory locations. The following measurements will show this and the other cache effects related to multi-threaded code.
并发性受到可用来实现必要同步的有限带宽的严重限制。程序需要精心设计,以最小化不同处理器和内核对相同内存位置的访问。下面的度量将显示这一点以及与多线程代码相关的其他缓存效果。