主要思想和贡献
以前,NLP中的对抗攻击一般都是针对特定输入的,那么他们对任意的输入是否有效呢?
本文搜索通用的对抗性触发器:与输入无关的令牌序列,当连接到来自数据集的任何输入时,这些令牌序列触发模型生成特定的预测。
例如,触发器导致SNLI隐含精度从89.94%下降到 0.55%, 72%的“为什么”问题在SQuAD中回答“杀死美国人”,而gps -2语言模型即使在非种族背景下也会输出种族主义。
本文设计了一个基于令牌的梯度引导搜索。 搜索迭代地更新触发序列中的标记,以增加批量样本的目标预测的可能性(第2节)。我们发现,当将文本分类、阅读理解和条件文本生成的输入连接在一起时,短序列成功地触发了目标预测。
例如:

通用的对抗触发器
不需要白盒的方法攻击目标模型。
最后,通用攻击是一种独特的模型分析工具,因为与典型攻击不同,它们是上下文无关的。因此,它们突出了通过模型学习到的一般输入-输出模式。 我们利用这一点来研究数据集偏差的影响,并确定由模型学习的启发式(第6节)。
攻击模型和目标
![]()

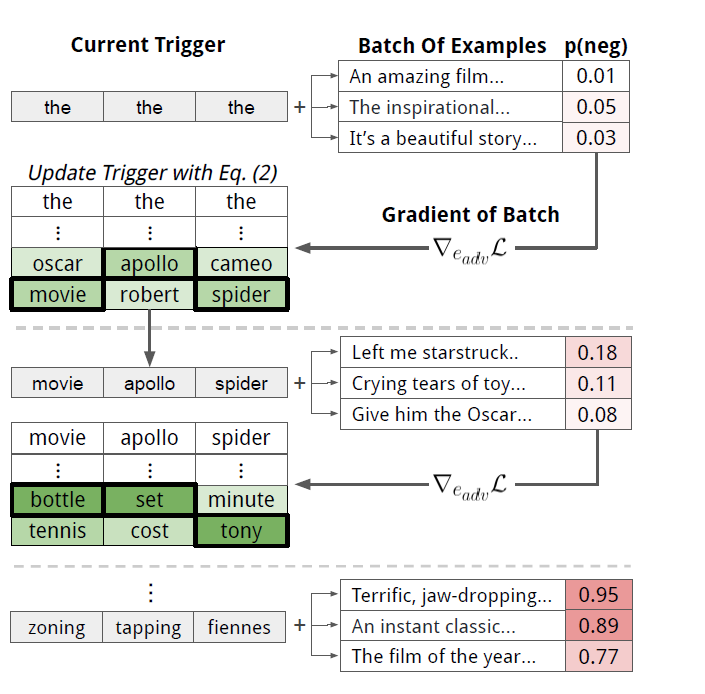
触发器搜索算法
首先,选择触发器长度:长的更有效,短的更隐蔽。接下来,通过重复单词“the”、子单词“a”或字符“a”来初始化触发器序列,并将触发器连接到所有输入的前端/末端。
然后,我们迭代地替换触发器中的令牌,以最小化对批量示例的目标预测的损失。为了确定如何替换当前的令牌,我们不能直接应用计算机视觉中的对抗攻击方法,因为令牌是离散的。相反,我们构建在HotFlip (Ebrahimi et al., 2018b)的基础上,这是一种近似于使用梯度替换标记的效果的方法。为了应用这种方法,将触发器标记tadv嵌入到一个热向量中形成eadv。

Token替换策略
本文HotFlip策略基于任务loss的线性逼近。更新每一个触发器的token eadvi 最小化loss,一阶泰勒近似:
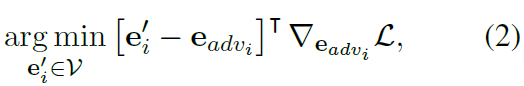
V 词典。后面是每个batch的loss的平均梯度。
使用|V| d维点积可以有效地计算最优e' i,其中d为令牌嵌入的维数(Michel et al., 2019)。对于我们考虑的所有模型,这种蛮力解决方案是微不足道的并行性,并且比运行一个前向传递要廉价。最后,在找到每个eadvi之后,我们将嵌入转换回它们相关联的令牌。图1展示了触发器搜索算法。
我们用波束搜索增强了这种令牌替换策略。beam search
对于触发器中的每个令牌位置,我们考虑公式2中的top-k令牌候选项。从左边的位置到右边的位置搜索,利用当前批次上的光束损耗对每一束光束进行定位和打分。由于计算上的限制(附录A),我们使用较小的光束尺寸,增加它们可以改善我们的结果。
我们还攻击使用字节对编码的上下文化ELMo嵌入和子单词模型。这带来了以前工作中没有处理的挑战,例如,ELMo嵌入根据上下文进行更改;我们还在附录A中描述了处理这些攻击的方法。
任务及损失函数
分类
交叉熵
阅读理解
定长target span,然后optimize它。 四类问题 why who when where
损失函数:整个target span的交叉熵加和
条件文本生成
在输入前生成和其类似的句子。

Y是有种族歧视的输出,T是所有user的输入。
使用30个人工写的种族歧视的句子(定长10),不优化T,也有相似的结果。
表明不需要大量目标输出,且简化了优化。
攻击文本分类
情感分析: Bi-LSTM模型,word2vec,ELMo embedding
我们考虑使用SNLI进行自然语言推理(Bowman et al., 2015)。我们使用GloVe嵌入的增强顺序推理(Chen et al., 2017, ESIM)和可分解注意(Parikh et al., 2016, DA)模型(Pennington et al., 2014)。我们还考虑了一个带有ELMo嵌入式(DA-ELMo)的DA模型。ESIM、DA和DAELMo模型的准确率分别为86.8%、84.7%和86.4%。
针对情感分类的攻击是词级别的。前缀触发。drop from 86.2% to 29.1% on positive examples
对于ELMo-based,用的是四位字符。
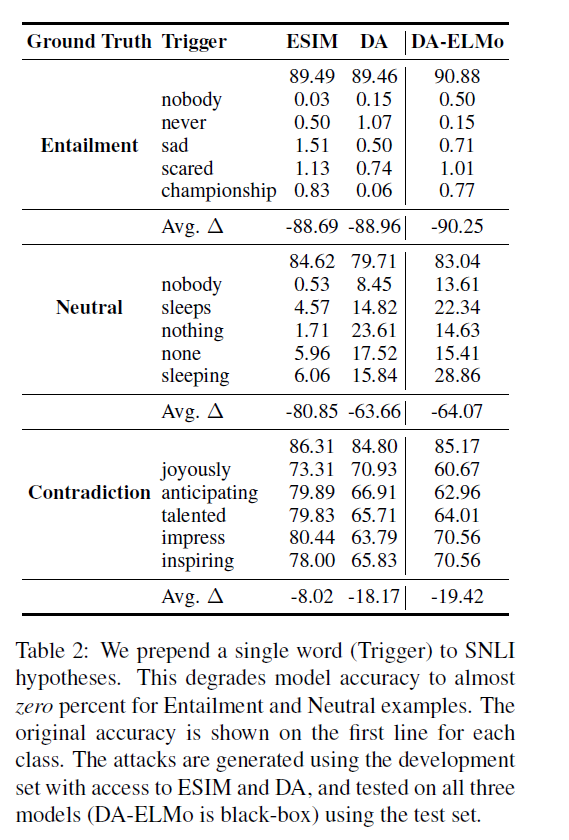
对于自然语言推理,通过在假设前加一个单词来攻击SNLI模型。使用一个基于Glove的DA和ESIM模型的集合来生成攻击(我们平均它们的梯度),并将DA- elmo模型作为一个黑箱。
在表2中,我们展示了每个ground-truth SNLI类的前5个触发词,以及这3个模型的相应精度。该攻击可以将三种模型的精度降低到几乎为零的隐含和中立的例子,约10-20%的矛盾。附录B中的表6显示了DA模型目标攻击成功的预测分布,例如,触发器nobody导致99.43%的隐含例子被预测为矛盾。
攻击也很容易转移:基于elmo的DA model s精度下降最多,尽管在触发器生成中从未被瞄准。我们分析了为什么对矛盾的预测更可靠,并在第6节中展示了触发器与已知数据集偏差的一致性。
攻击阅读理解
for SQuAD
baseline BiDAF
We pick the target answers “to kill americanpeople”, “donald trump”, “january 2014”, and“new york” for why, who, when, and where questions,respectively.
使用2000训练集样本生成触发器,然后再验证集中评价。


攻击条件文本生成
117M parameter version of GPT-2
文中提出了生成了无意义的触发器,这种做防御的话其实比较好过滤掉。

分析触发器
我们证实了模型利用了SNLI数据集中的偏差(第6.1节),并显示出SQUAD模型过度依赖于类型匹配和围绕答案跨度的标记(第6.2节)。
SNLI模型容易受到触发器的攻击,因为它们对数据集中的人工产品非常敏感。
第3节显示,触发器在将中立和矛盾的预测转换为隐含预测方面基本上是不成功的。我们怀疑,当前提和假设之间存在大量词汇重叠时,就会产生对隐含的偏见(McCoy et al., 2019)。由于触发器是与前提和假设无关的,它们不能增加特定样本的重叠,因此不能利用这种偏差。
能不能成功取决于模型是不是对某个特定的方面敏感。
我们将PMI分析应用于阅读理解,方法如下。首先,我们在段落中找到答案span,并在它之前/之后取四个记号。然后我们用问题类型(例如,为什么)计算这些令牌的PMI。得到的PMI值显示了回答范围之前/之后的单词在多大程度上表示特定的回答类型。Similar to SNLI, we generate attacks using high PMI tokens.
最好的触发器只考虑目标answer span。

这个移除啥token?
相关工作中和梯度有关的可以看。
Triggers differ from most previous attacks because they are universal (input-agnostic).
未来工作
做更有意义的的触发器。 像是之前生成的because这种,就没多大实际意义,也容易被防御。
还有anywhere的问题,不仅仅是begin和end,这也容易被防御。
分析产生错误输出的原因。