核心思想
基于阅读理解中QA系统的样本中可能混有对抗样本的情况,在寻找答案时,首先筛选出可能包含答案的句子,再做进一步推断。
方法
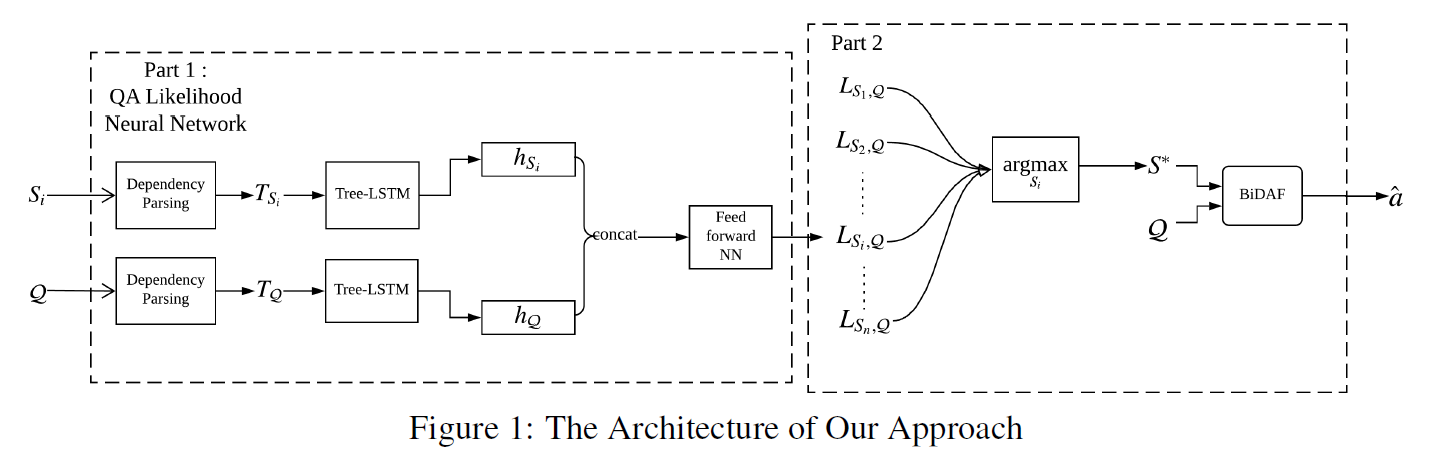
Part 1
given: 段落C query Q
段落切分成句子:![]()
每个句子和Q合并:![]()
使用依存句法分析得到表示:![]()
基于T Si T Q ,分别构建 Tree-LSTMSi Tree-LSTMQ
两个Tree-LSTMs的叶结点的输入都是GloVe word vectors
输出隐向量分别是 hSi hQ
hSi hQ连接起来并传递给一个前馈神经网络来计算出Si包含Q的答案的可能性
loss 和前馈神经网络follows语义相关性网络
有监督的训练时,si包含答案为1,否则为0。
Part 2
计算最可能答案:

L代表QA似然神经网络预测的似然
将一对句子S*和Q传递给预先训练好的单BiDAF(Seo et al., 2016),生成Q的答案a^。
实验
数据集:sampled from the training set of SQuAD v1.1
there are 87,599 queries of 18,896 paragraphs in the training set of SQuAD v1.1. While each query refers to one paragraph, a paragraph may refer to multiple queries.
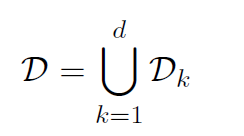
d=87,599 is the number of queries. The set D contains 440,135 sentence pairs, among which 87,306 are positive instances and 352,829 are negative instances.
positive instance: ![]() ,前者包含后者的答案。
,前者包含后者的答案。
两种采样方法: pair-level sampling ,paragraph-level sampling
1. In pair-level sampling, 45,000 positive instances and 45,000 negative instances are randomly selected from D as the training set.
2. paragraph-level sampling 首先随机选Qk,然后从Dk中随机采样出一个positive instance 和一个negative instance
Each set has 90,000 instances. The validation set with 3,000 instances are sampled through these two methods as well.
测试集:ADDANY adversarial dataset : 1,000 paragraphs and each paragraph refers to only one query. By splitting and combining, 6,154 sentence pairs are obtained.
实验设置:The dimension of GloVe word vectors (Pennington et al., 2014) is set as 300. The sentence scoring neural network is trained by Adagrad (Duchi et al., 2011) with a learning rate of 0.01 and a batch size of 25. Model parameters are regularized by a 10-4 strength of per-minibatch L2 regularization.
结果
评价标准:Macro-averaged F1 score (Rajpurkar et al., 2016; Jia and Liang, 2017).
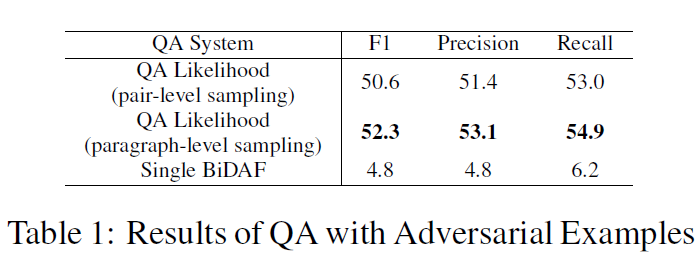
对于table2,可以理解为二分类问题。
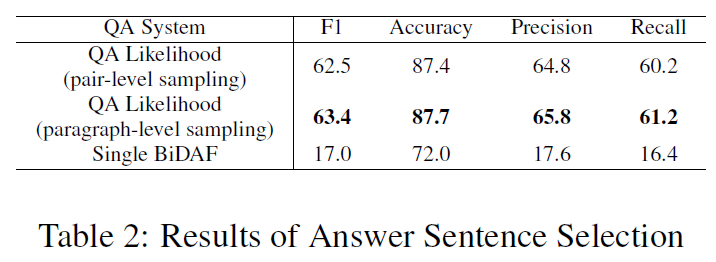
consider three types of sentences: adversarial sentences, answer sentences, and the sentences that include the answers returned by the single BiDAF system.
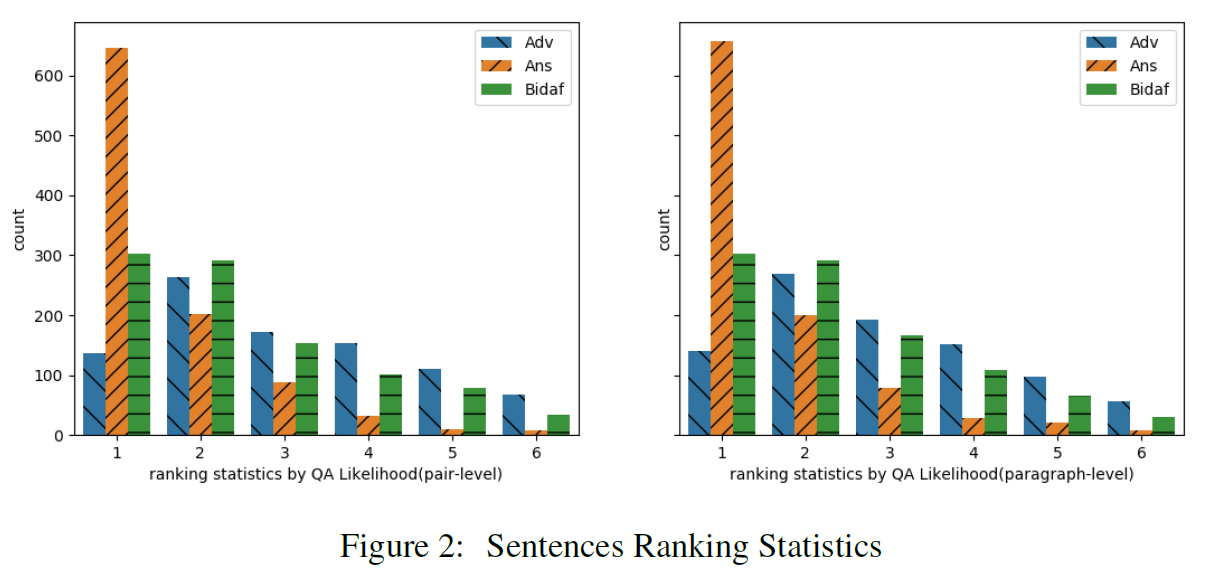
the x-axis denotes the ranked position for each sentence according to its likelihood score , while the y-axis is the number of sentences for each type ranked at this position.
It shows that among the 1,000 (C;Q) pairs, 647 and 657 answer sentences are selected by the QA Likelihood neural network based on pair-level sampling and paragraph-level sampling respectively, but only 136 and 141 adversarial sentences are selected by the QA Likelihood neural network.
结论
对于ADDSENT的没有做。