Generating Fluent Adversarial Examples for Natural Languages ACL 2019
为自然语言生成流畅的对抗样本
摘要
有效地构建自然语言处理(NLP)任务的对抗性攻击者是一个真正的挑战。首先,由于句子空间是离散的。沿梯度方向做小扰动是困难的。其次,生成的样本的流畅性不能保证。在本文中,我们提出了MHA,它通过执行Metropolis-Hastings抽样来解决这两个问题,其建议是在梯度的指导下设计的。在IMDB和SNLI上的实验表明,我们提出的MHA在攻击能力上优于基线模型。使用MHA进行对抗性训练也会带来更好的健壮性和性能。
1 介绍
对抗性学习是深度学习中的一个热门话题。攻击者通过扰动样本生成对抗性样本,并利用这些样本欺骗深度神经网络(DNNs)。从防御的角度出发,将对抗性样本混合到训练集中,提高了受害者模型的性能和鲁棒性。然而,为NLP 模型(例如文本分类器)构建攻击者是非常困难的。首先,由于句子空间离散,基于梯度的微扰难以实现。然而,梯度信息是至关重要的,它导致最陡的方向,以更有效的样本。其次,对抗性的样本通常不是流利的句子。不流畅的样本在攻击中效果较差,因为受害者模型可以很容易地学会识别它们。同时,对它们进行对抗性训练通常效果不佳(详细分析见图1)。目前的方法不能很好地处理这两个问题。

易卜拉欣等(2018)(HotFlip)提出通过翻转一个字符来扰乱一个句子,并使用每个字符的梯度来指导样本的选择。但是简单的字符转换常常导致无意义的单词(例如。"mood”到“mooP”)。遗传攻击(Alzantot•et al., 2018)是一个基于种群的词替代攻击者,其目的是通过语言模型过滤掉不合理的句子,生成流畅的句子。但遗传攻击证明的样本生成的流畅性仍不理想,当梯度被丢弃时,它的效率较低。
针对上述问题,本文提出了基于MHA算法的算法。MHA是基于Metropolis- hastings (M-H)采样的对抗样本生成(Metropolis et al., 1953; HASTINGS, 1970; Chib and Greenberg, 1995).。M H采样是一种经典的MCMC采样方法,在许多NLP任务中得到了应用。
两种MHA变体: 黑盒 MHA 白盒MHA b-MHA w-MHA
具体来说,与以往的M-H语言生成模型相比,b-MHA的静态分布具有一个语言模型项和一个对抗攻击项。这两个术语使得对抗样本的生成流畅而有效。w-MHA甚至将对抗性梯度合并到提案分发(? proposal distributions)中,以加快对抗样本的生成。
我们的贡献包括提出了一个有效的方法来生成流畅的反例。IMDB (Maas et al., 2011)和SNLI (Bowman et al., 2015)的实验结果表明,与最先进的生成模型相比,MHA生成样本的速度更快,在专业上的成功率更高。同时,MHA的对抗性样本在经过对抗性训练后,不仅更加流畅,而且更加有效,提高了对抗性的鲁棒性和分类精度。
2 准备工作
victim models 受害者模型是单词级的,它接受标记化的句子并输出它们的标签。攻击者通过扰乱原句来生成句子,从而误导受害者模型犯错误。对抗攻击包括两类:(a)黑盒 (b) 白盒。对于对抗性训练,在包含对抗性样本的更新训练集上从零开始训练相同的受害者模型。
3 MHA
主要讲M-H抽样,以及如何使用M-H抽样有效地生成自然语言的对抗样本。
3.1 Metropolis-Hastings Sampling
M-H算法是一种经典的马尔可夫链蒙特卡罗抽样方法。考虑到最优分布(Π(x))和转换建议 transition proposal,M-H能够Π(x)生成理想的样本。具体地说,在每个迭代中,根据建议分布(g(x' | x))提出一个从x跳到x'的建议。建议获接纳的概率由接纳率 acceptance rate给出:
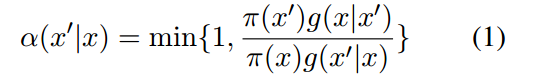
一旦接受,算法跳到x’,否则停留在x。
3.2 黑盒攻击
在黑盒攻击(b-MHA)中,我们期望样本满足三个要求:(a)具有较强的阅读能力;(b)能够愚弄分类器;(c)尽可能少地调用分类器。
平稳分布 Stationary distribution。为满足这些要求,平稳分布设计为:
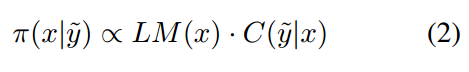
其中LM(x)为预训练语言模型(LM)给出的句子(x)的概率和C(y~ | x)为受害者模型给出的错误标签(y~)的概率。LM(x)保证流畅性,而C(y~|x)是攻击目标。
转换建议 Transition proposal。有三种字级转换操作——替换、插入和删除。遍历索引用于选择执行操作的单词。假设MHA在第t个proposal上选择第i个单词(wi),然后在(t + 1)-th proposal上,受影响的单词(w*)为: (下一个单词)

替换的过渡函数如式3所示,其中w m为被替换的选定单词,Q为预选候选集,待会解释。插入操作![]() 由两个步骤组成——将一个随机单词插入该位置,然后对其执行替换。删除操作相当简单。
由两个步骤组成——将一个随机单词插入该位置,然后对其执行替换。删除操作相当简单。![]() ,其中x-m为删除第m个单词(wm)后的句子,
,其中x-m为删除第m个单词(wm)后的句子,![]() 。
。
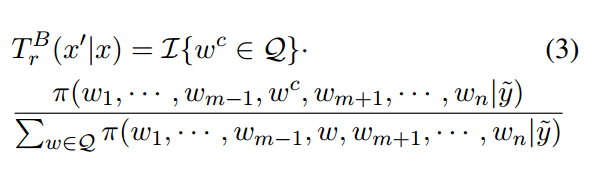
建议分布为过渡函数的加权和:

其中pr、pi、pa为操作的预定义概率。
预选。
预选器生成![]() 的候选集。它根据分数(SB (wlx))选择最可能的单词组成候选单词集Q,SB(wlx)表示为:
的候选集。它根据分数(SB (wlx))选择最可能的单词组成候选单词集Q,SB(wlx)表示为:
![]()
x (1: m - 1) = | w1 . .,w m-1}为句子的前缀,X m+1:nl为句子的后缀,LM为预先训练好的后向语言模型。如果没有预选,Q会将词汇表中的所有单词都隐藏起来,并且会反复调用分类器来计算公式3的分母,这是低效的。(有预选的话相当于这个概率就是确定的了,不用再计算概率了。但是这一有个缺点在于,如果单词特别多,可能需要LM生成大量结果)
3.3 白盒攻击
白盒攻击(wmha)和b-MHA的唯一区别在于预选器。
预选。在w-MHA中,梯度被引入预选分数(SW (w|x))。sW (wlx)表示为:

其中S为余弦相似函数,L~ =![]() 为目标标签上的损失函数,em和e为当前单词(wm)和替代(w)的嵌入。梯度
为目标标签上的损失函数,em和e为当前单词(wm)和替代(w)的嵌入。梯度![]() 会导致最大的方向,和em-e 是真实的改变方向(如果他们被em被e替换)。余弦相似性术语
会导致最大的方向,和em-e 是真实的改变方向(如果他们被em被e替换)。余弦相似性术语![]() 引导样本一起跳到梯度的方向,提出了C(y~ | C)和α (x' | x),甚至性使w-MHA更有效率。
引导样本一起跳到梯度的方向,提出了C(y~ | C)和α (x' | x),甚至性使w-MHA更有效率。
注意,插入和删除被排除在w-MHA中,因为很难计算它们的梯度。以插入操作为例。可以在b-MHA中应用类似的技术,首先插入一个随机的单词形成中间语句x*= {u1,,。, Wm, w*, Um+1,。, un},然后在x*上进行每个成形替换操作。计算![]() 很简单,但它不是实际的梯度。实际梯度的计算
很简单,但它不是实际的梯度。实际梯度的计算![]() 很难,因为从x到x*的变化是离散的、非微分的。
很难,因为从x到x*的变化是离散的、非微分的。
4 实验
数据集。在前面的工作中,我们对所提出的MHA在IMDB和SNLI数据集上的性能进行了测试。IMDB数据集包括25,000个训练样本和25,000个电影评论测试样本,并带有情感标签(正面或负面)。SNLI数据集包含55,000个训练样本、10,000个验证样本和10,000个测试样本。每个样本都包含一个前提、一个假设和一个推断标签(隐含、矛盾或中性)。我们在IMDB和SNLI上分别采用单层bi-LSTM和BiDAF模型(Seo et al., 2016)(该模型采用双向注意流机制捕捉句子对之间的关系)作为受害者模型。
基线遗传攻击者。我们采用最先进的基因攻击模型(Alzantot等。作为我们的基线,它使用了一个基于无梯度的种群算法。从直观上看,它主要是获得一个句子的总体,不考虑受害者模型,而是根据嵌入层距离进行词级替换,扰乱句子。然后,中间句是通过受害者分类器和一个语言模型得到了下一代。
Hyper-parameters。如苗等人的作品。(2018), MHA最多只能提出200次建议,每次迭代我们预先选择30个候选。MHA中包含了一些限制,以禁止对感情用事的词或否定词进行任何操作(例如。“great”或"not"。在IMDB使用感知网络(Esuli和Sebas tiani)进行实验。2006: Baccianella等。2010)。所有受害者模型中的LSTMs都有128个单元。受害者模型在IMDB和SNLI上的测试正确率分别达到83.1%和81.1%。这些都是可以接受的回答。附录中包含了更详细的超参数设置。
4.1 对抗攻击
为了验证攻击效率,我们分别从IMDB和SNLI测试集中随机抽取1000个和500个正确分类的样本。攻击成功率和调用时间(受害者模型)用于测试效率。如图3所示,我们提出的MHA曲线高于遗传基线,说明MHA的有效性。将梯度信息引入到方案分布中。随着曲线的快速上升,w-MHA甚至比b-MHA表现得更好。注意梯子的形状遗传方法的曲线是由它的脉动特性引起的。
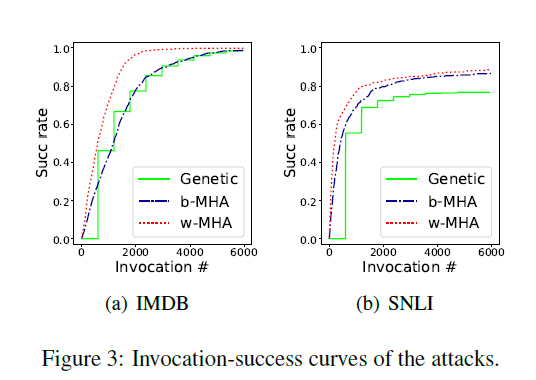
我们在表1中列出了详细的结果。通过调用受害者模型最多6000次,可以获得成功率。如图所示,模型之间的成功率差距不是很大,因为所有的模型都能给出相当高的成功率。然而,正如所料,我们提出的MHA提供了较低的perplexity (PPL) 1,这意味着MHA生成的样本更有可能出现在评估语言模型的语料库中。由于语料库足够大,用于评价的language模型足够强,所以在dicates中MHA生成的样本更有可能出现在自然语言空间中。它甚至能让你更流利。

还进行了人工评估。从这三种方法都成功攻击的样本中,我们在IMDB上取样了40个样本。三个志愿者被要求对生成的样本进行标记。使用受害者分类器的假标签和vol unteers的真标签的样本被视为实际的对抗性测试组。与之相对的样本比例的遗传。方法中,b-MHA和w-MHA分别为98.3%、99.2%和96.7%,说明生成的样本几乎都是对抗样本。卷测试者还被要求对生成的考试组在SNLI上的流利程度进行排名(“1”表示最流利,“3”表示最不流利)。上面提到的20个例子都是以同样的方式进行的。遗传方法、b-MHA和w-MHA的排序均值为1.93 1.80和2.03,表明b-MHA生成的样本最流畅。由W-MHA生成的样本不如遗传方法流畅。这可能是因为预选器中引入的梯度会影响句子的流畅性,从人的角度来看。
不同模型或SNLI的反例如表2所示。遗传方法可以用不同的时态来代替动词,也可以用不同的复数来代替名词,从而导致语法错误。(如例1),而MHA使用语言模型来表示平稳分布,以避免这种语法错误。MHA并没有限制单词替换应该具有简单的含义。MHA可能会用一些不相关的词来代替实体或动词,导致原句的意思发生变化(如:例2)。更多的案例包括在附录中。

4.2 对抗性训练
为了验证对抗性训练是否有助于提高受害者模型的对抗性鲁棒性或分类精度。将生成的样本混合到训练集中,从零开始训练新的模型。为了检验模型的抗对抗鲁棒性,我们在IMDB上采用了各种方法对新模型进行攻击。如表3所示,经过遗传逆向训练的新模型不能防御MHA。相反,采用b-MHA或w-MHA de进行对抗性训练会降低遗传攻击的成功率。它显示了来自MHA的反例可能比来自于genetic at tack的反例更有效,如图1所示。

为了检验新模型在对抗性训练后是否能达到精度的提高,我们对不同大小的训练数据进行了实验,这些数据都是SNLI训练集的子集,实验中对抗性样本的数量固定为250个。表4列出了不同方法对抗性训练后新模型的分类精度。使用w-MHA进行Adver sarial训练可以显著提高这三种设置的准确性(p值小于0.02)。W-MHA在10K和30K训练数据上优于遗传基线,并与100K训练数据得到了类似的改善。较少的训练数据导致较大的accu快速增益,而MIHA在较小的训练集上的性能明显优于遗传方法。
5 未来工作
当前的MHA在标签发生变化时返回样本,这可能导致句子的时态不完整,从人类的角度来看,句子时态并不流畅。诸如强制模型在返回前在句尾生成(EOS)之类的约束可能会解决这个问题。
此外,没有限制的实体和动词替换对NLI等任务的对抗的前几代有负面影响。在词的运算过程中,相似度的限制是解决这一问题的关键。诸如模仿嵌入距离之类的约束可能会有所帮助。另一种解决方法是在预选源中嵌入距离的逆。
6 结论
在本文中,我们提出了MHA,它采用MH抽样的方法,为自然语言生成对抗样本。实验结果表明,我们提出的MHA能够比生成基线更快地生成反例。从MHA中获得的对抗样本更流畅,对对抗性训练可能更有效。
思考:
1. 解决的问题
生成的对抗不流畅的问题
2. 解决的方法
MHA黑盒白盒
3. 优缺点
优点:流畅样本 攻击高效
缺点:抽样的准确性问题。替换的词偏差过大的问题。
找这篇文章的附录和其他 复现