使用python进行网络爬虫
非结构画数据 转为 结构化数据。需要借助ETL(数据抽取,转换,存储)进行。
非结构化数据蕴含着丰富的价值。需要借助ETL进行转换成结构化数据,才能变成有价值的数据。比如下边的网页,信息是非结构化的,我们需要把他们转为结构化的数据,才会变成有价值的信息。

再例如搜索引擎,就是利用网络爬虫技术,去各个网站爬虫数据,然后做成索引,然后供我们查找。为什么今天的爬虫技术这么热呢?因为我们需要的数据好多都不在自己的数据库上,所以只能通过网络爬虫的技术去网络上爬取。
一 网络爬虫架构
一般网络爬虫架构如下:
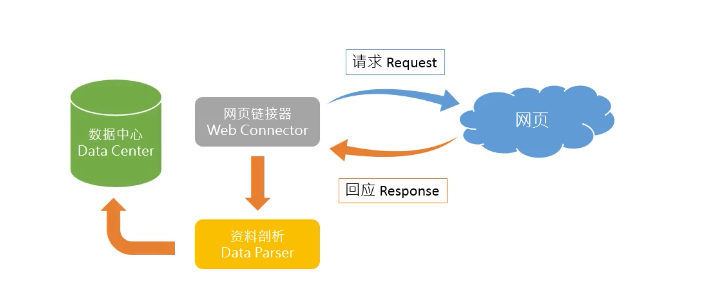
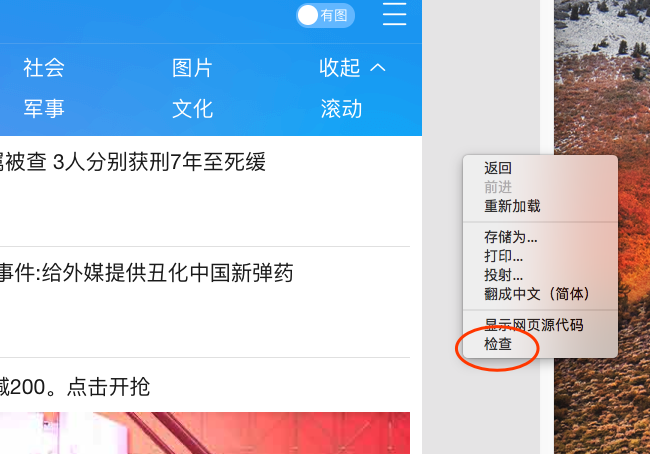
首先我们要有一个网页链接器,然后去网站的服务器进行请求,然后服务器给我们反应。我们可以又键鼠标,然后选择检查
然后选择Network选项,然后点击左上角的刷新按钮,发现左下角有67个请求。
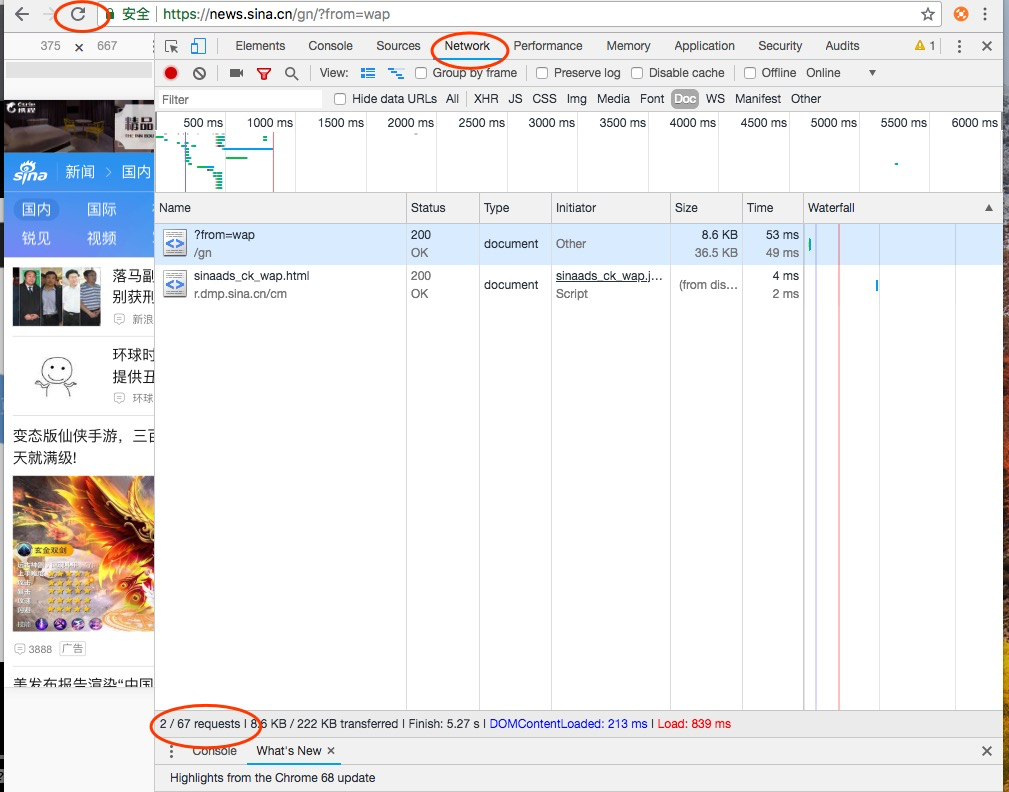
这些功能原本是给网页开发人员使用的,但network也可以给我们轻松使用,分析得到什么样的请求,得到了什么回应。
我们点击左上角的漏斗行的按钮,发现得到很多信息。
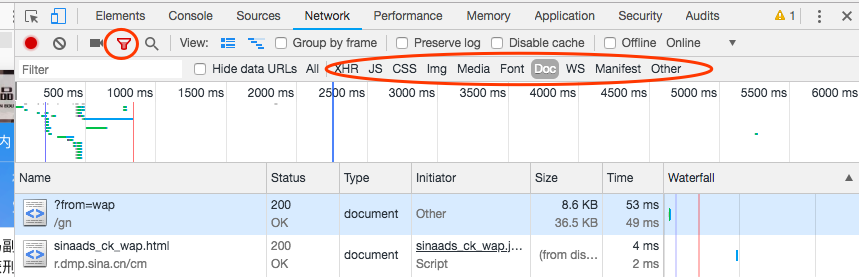
XHR:网站回应的内容
JS:和网页互动
CSS:网站的化妆品,呈现颜色等
Img:图片
Media:多媒体资料,如视频
Font:文字
Doc:网页资料
WS:是websocket
Manifest:宣告
Other:其他
我们的新闻内容一般就是放在了Doc里边了,点击Doc按钮,选择第一个页面的Response。
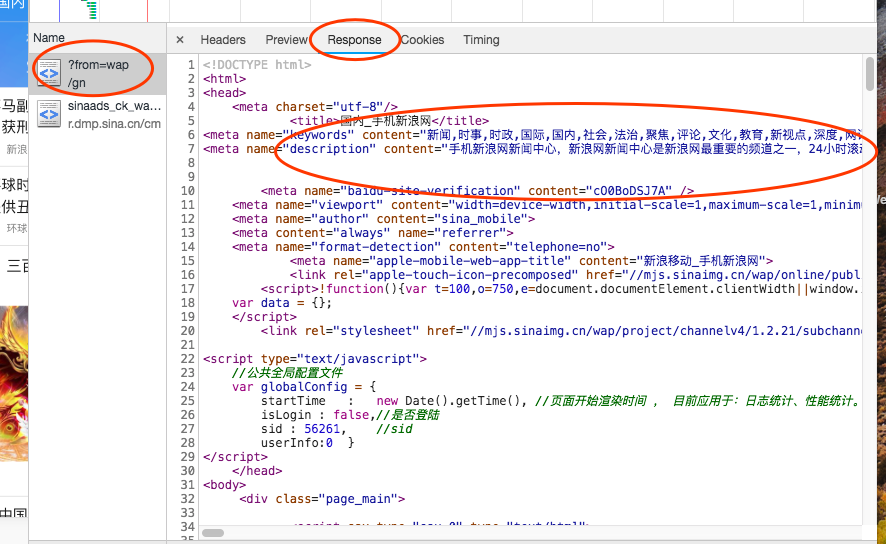
通过比较我们的网站内容和html,发现很像,那么这些资料很有可能就是我们需要的资料。
二 网络爬虫背后的秘密
如何观察一个网页,然后把有用的内容抓取下来?
首先我们可以用开发人员工具,右键选择检查,然后选择Doc,在选择第一个链接。
为什么可以在Doc里边找到呢?因为每一个网站都需要被搜索引擎爬虫到的需求,百分之九十的都会在Doc里边找到。如何判断这个链接就是我们需要抓取的内容呢?我们可以通过比较html内容和网页内容来判断。
我们选择Headers内容:
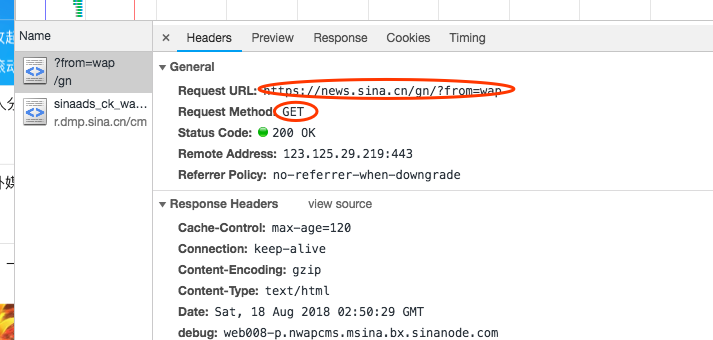
什么是get方法呢?
我们可以把get方法想象成一个明信片,我们通过get方法来访问服务器,当服务器收到我们的get之后,知道了我们的来意,就可以把相应的回应返回给我们。
通过pip安装套件:
pip insatll requests
pip install BeautifulSoup4
三 编写第一个网络爬虫
使用Request进行操作,(不实用Urllib2,因为它用起来非常的麻烦)。
回到新浪页面,既然可以用get得到这个页面,那么就用这个网址进行获取这个页面。

import requests res=requests.get('https://news.sina.cn/gn/?from=wap') print(res)
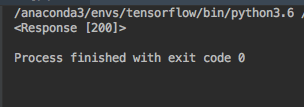
import requests res=requests.get('https://news.sina.cn/gn/?from=wap') print(res.text)

乱码是因为解码的问题,python误认为是其他的编码方式,
可以用encoding查看编码形式
import requests res=requests.get('https://news.sina.cn/gn/?from=wap') print(res.encoding)

修改代码如下:
import requests res=requests.get('https://news.sina.cn/gn/?from=wap') res.encoding='utf-8' print(res.text)
此时不会再乱码了

但是现在的信息依然存在html中,如何把这些信息转成结构化信息呢?
我们可以使用DOM的方法,即Document Object Model,这是一组API,可以用来和网页元素进行互动,

我们可以看到这么一棵树,最上边是html,然后下边是body。
# import requests # # res=requests.get('https://news.sina.cn/gn/?from=wap') # res.encoding='utf-8' # print(res.text) from bs4 import BeautifulSoup html_samp=" <html> <body> <h1 id='title'>hello world</h1> <a href='#' class ='link'>this is link1</a> <a href='# link2' class='link'>this is link2</a> </body> </html>" soup=BeautifulSoup(html_samp) print(soup.text)
运行得到:
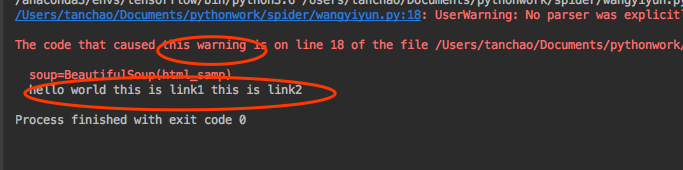
输出了内容,但是有一个警告,因为我们没有指定一个剖析器,此时程序会给我们一个默认的。我们也可以指定一个剖析器,避免这个警告。
改写语句:
soup=BeautifulSoup(html_samp,'html.parser')
我们要抓取的内容也许是在特殊的标签之中,那么如何从特殊的标签和节点之中找到我们需要的数据呢?
我们可以用select方法,把含有特定标签的数据取出来

from bs4 import BeautifulSoup html_samp=" <html> <body> <h1 id='title'>hello world</h1> <a href='#' class ='link'>this is link1</a> <a href='# link2' class='link'>this is link2</a> </body> </html>" soup=BeautifulSoup(html_samp,'html.parser') header=soup.select('h1') #因为soup中可能会有很多的h1标签,所以上边的header是一个list,所以header[0]表示第一个h1标签 print(header[0])
输出为:

如果要输出其中的内容的画,可以用header[0].text得到其中的内容。
css是网页化妆品,当我们取用里边的词,当里边的id为title时,必须要加上‘#’,才可以存取,如果为class的话,必须要加上‘.’才可以存取。
from bs4 import BeautifulSoup html_samp=" <html> <body> <h1 id='title'>hello world</h1> <a href='#' class ='link'>this is link1</a> <a href='# link2' class='link'>this is link2</a> </body> </html>" soup=BeautifulSoup(html_samp,'html.parser') #为title的要加上'#' alink=soup.select('#title') print(alink) #为class的,要加上'.' for link in soup.select('.link'): print(link)
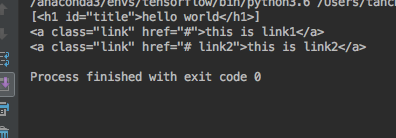
最后,还有一个需求,在网页的链接上,我们会用a tag去联系到不同的网页,a tag里边有一个特殊的属性href,使用href才可以联系到其他的网页。

from bs4 import BeautifulSoup html_samp=" <html> <body> <h1 id='title'>hello world</h1> <a href='#' class ='link'>this is link1</a> <a href='# link2' class='link'>this is link2</a> </body> </html>" soup=BeautifulSoup(html_samp,'html.parser') alinks=soup.select('a') for link in alinks: print(link) #之所以我们会用link['href']这样的写法,是因为其中的存取是使用了字典的形式 print(link['href'])

四 抓取新浪新闻内容
我们已经知道,1.使用requests.get取得页面内容;使用beautifulsoup4把内容剖析出来。
那我们应该怎么对新浪新闻的标题,时间,链接等取出来呢?