1.原始版本
最早的卷积方式还没有任何骚套路,那就也没什么好说的了。
见下图,原始的conv操作可以看做一个2D版本的无隐层神经网络。
附上一个卷积详细流程:
【TensorFlow】tf.nn.conv2d是怎样实现卷积的? - CSDN博客

代表模型:
LeNet:最早使用stack单卷积+单池化结构的方式,卷积层来做特征提取,池化来做空间下采样
AlexNet:后来发现单卷积提取到的特征不是很丰富,于是开始stack多卷积+单池化的结构
VGG([1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition):结构没怎么变,只是更深了
2.多隐层非线性版本
这个版本是一个较大的改进,融合了Network In Network的增加隐层提升非线性表达的思想,于是有了这种先用1*1的卷积映射到隐空间,再在隐空间做卷积的结构。同时考虑了多尺度,在单层卷积层中用多个不同大小的卷积核来卷积,再把结果concat起来。
这一结构,被称之为“Inception”

代表模型:
Inception-v1([1409.4842] Going Deeper with Convolutions):stack以上这种Inception结构
Inception-v2(Accelerating Deep Network Training by Reducing Internal Covariate Shift):加了BatchNormalization正则,去除5*5卷积,用两个3*3代替
Inception-v3([1512.00567] Rethinking the Inception Architecture for Computer Vision):7*7卷积又拆成7*1+1*7
Inception-v4([1602.07261] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning):加入了残差结构
3.空洞卷积
Dilation卷积,通常译作空洞卷积或者卷积核膨胀操作,它是解决pixel-wise输出模型的一种常用的卷积方式。一种普遍的认识是,pooling下采样操作导致的信息丢失是不可逆的,通常的分类识别模型,只需要预测每一类的概率,所以我们不需要考虑pooling会导致损失图像细节信息的问题,但是做像素级的预测时(譬如语义分割),就要考虑到这个问题了。
所以就要有一种卷积代替pooling的作用(成倍的增加感受野),而空洞卷积就是为了做这个的。通过卷积核插“0”的方式,它可以比普通的卷积获得更大的感受野,这个idea的motivation就介绍到这里。具体实现方法和原理可以参考如下链接:
如何理解空洞卷积(dilated convolution)?
膨胀卷积--Multi-scale context aggregation by dilated convolutions
我在博客里面又做了一个空洞卷积小demo方便大家理解
【Tensorflow】tf.nn.atrous_conv2d如何实现空洞卷积? - CSDN博客
代表模型:
FCN([1411.4038] Fully Convolutional Networks for Semantic Segmentation):Fully convolutional networks,顾名思义,整个网络就只有卷积组成,在语义分割的任务中,因为卷积输出的feature map是有spatial信息的,所以最后的全连接层全部替换成了卷积层。
Wavenet(WaveNet: A Generative Model for Raw Audio):用于语音合成。
4.深度可分离卷积
Depthwise Separable Convolution,目前已被CVPR2017收录,这个工作可以说是Inception的延续,它是Inception结构的极限版本。
为了更好的解释,让我们重新回顾一下Inception结构(简化版本):

上面的简化版本,我们又可以看做,把一整个输入做1*1卷积,然后切成三段,分别3*3卷积后相连,如下图,这两个形式是等价的,即Inception的简化版本又可以用如下形式表达:

OK,现在我们想,如果不是分成三段,而是分成5段或者更多,那模型的表达能力是不是更强呢?于是我们就切更多段,切到不能再切了,正好是Output channels的数量(极限版本):

于是,就有了深度卷积(depthwise convolution),深度卷积是对输入的每一个channel独立的用对应channel的所有卷积核去卷积,假设卷积核的shape是[filter_height, filter_width, in_channels, channel_multiplier],那么每个in_channel会输出channel_multiplier那么多个通道,最后的feature map就会有in_channels * channel_multiplier个通道了。反观普通的卷积,输出的feature map一般就只有channel_multiplier那么多个通道。
具体的过程可参见我的demo:
【Tensorflow】tf.nn.depthwise_conv2d如何实现深度卷积? - CSDN博客
既然叫深度可分离卷积,光做depthwise convolution肯定是不够的,原文在深度卷积后面又加了pointwise convolution,这个pointwise convolution就是1*1的卷积,可以看做是对那么多分离的通道做了个融合。
这两个过程合起来,就称为Depthwise Separable Convolution了:
【Tensorflow】tf.nn.separable_conv2d如何实现深度可分卷积? - CSDN博客
代表模型:Xception(Xception: Deep Learning with Depthwise Separable Convolutions)
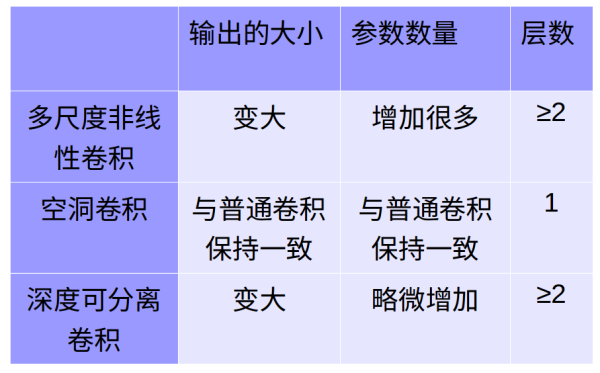
5.比较
转载:https://zhuanlan.zhihu.com/p/29367273?utm_source=qq&utm_medium=social