IV字典表(类似字典,快速找汉字)
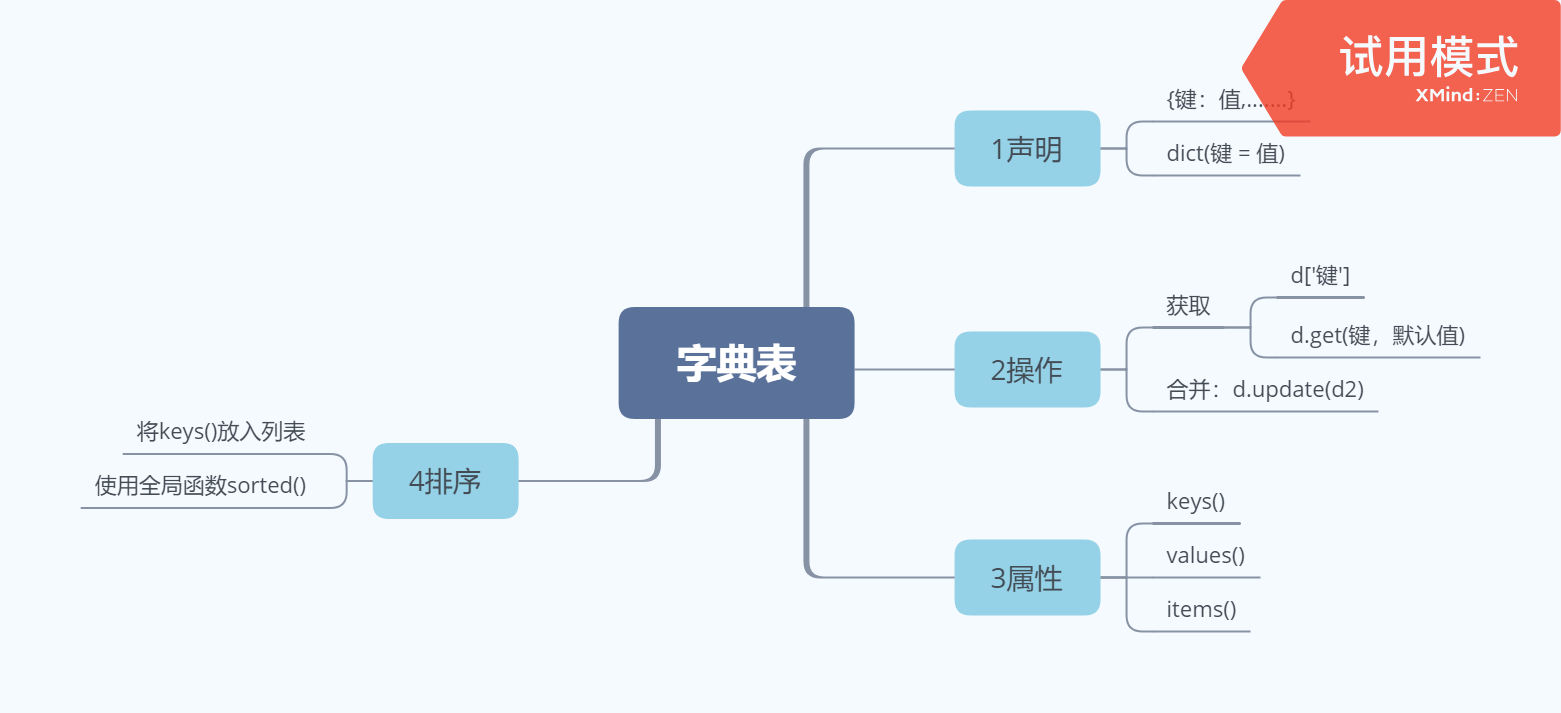
1声明:(1){键:值,...} (2)dict(键=值)
d = {'ISBN':'23412343','Title':'Python入门','price':39.00} #定义一个字典表有键有值
d['Title']
Out[3]: 'Python入门'
d['price']
Out[4]: 39.0
d['Author'] = 'Jerry' #把Jerry放进去
d
Out[6]: {'ISBN': '23412343', 'Title': 'Python入门', 'price': 39.0, 'Author': 'Jerry'} #list就不可以直接插入
检索功能
d Out[6]: {'ISBN': '23412343', 'Title': 'Python入门', 'price': 39.0, 'Author': 'Jerry'} d.get('price') Out[7]: 39.0 d.get('price') #搜索一下不存在的,发现得不到值也不会报异常 Out[8]: 39.0 d.get('Price',0.0) #表示得不到的值返回0.0 Out[10]: 0.0
emp = dict(name='mike',age=20,job='dev') #建立一个来描述员工信息字典表,值的分割用等于号做 emp Out[14]: {'name': 'mike', 'age': 20, 'job': 'dev'} len(emp) #字典表也可以测长度 Out[15]: 3
关于字典表的原位替换问题,它不可以像list一样l[0]=5可以直接替换
d['price'] = 99.00 emp Out[17]: {'name': 'mike', 'age': 20, 'job': 'dev'} dep = {'department':'技术部'} emp.update(dep) #合一块 emp Out[21]: {'name': 'mike', 'age': 20, 'job': 'dev', 'department': '技术部'}
弹出功能
Out[21]: {'name': 'mike', 'age': 20, 'job': 'dev', 'department': '技术部'}
emp.pop('age') #弹出
Out[22]: 20
emp
Out[23]: {'name': 'mike', 'job': 'dev', 'department': '技术部'}
keys() values()items()
emp.keys() #方法访问键 Out[26]: dict_keys(['name', 'job', 'department']) emp.values() #访问值 Out[27]: dict_values(['mike', 'dev', '技术部']) for k in emp.keys(): print(k) name job department for v in emp.values():print(v) mike dev 技术部 emp.items() #把键和值都放在里面 Out[30]: dict_items([('name', 'mike'), ('job', 'dev'), ('department', '技术部')])
In[32]: for k,v in emp.items(): ...: print('{}=> {}'.format(k,v)) ...: name=> mike job=> dev department=> 技术部
In[33]: emp Out[33]: {'name': 'mike', 'job': 'dev', 'department': '技术部'} In[34]: emp.get('name') Out[34]: 'mike'
字典表不可直接排序
In[36]: d = {'a':1,'b':2,'c':3,'d':4}
In[37]: d
Out[37]: {'a': 1, 'b': 2, 'c': 3, 'd': 4} 发现是乱序的
In[39]: ks = d.keys() #找键
In[40]: ks
Out[40]: dict_keys(['a', 'b', 'c', 'd'])
In[41]: ks = list(d.keys()) #把所有键取出变个列表
In[42]: ks.sort()
In[43]: ks
Out[43]: ['a', 'b', 'c', 'd']
In[44]: for k in ks:
...: print(d.get(k)) #全局函数
...:
1
2
3
4
In[48]: ks = d.keys() #等于keys所有键
In[49]: ks
Out[49]: dict_keys(['a', 'b', 'c', 'd'])
In[50]: for k in sorted(ks): #排序
...: print(k, d.get(k)) # 获取
...:
a 1
b 2
c 3
d 4
V 元组
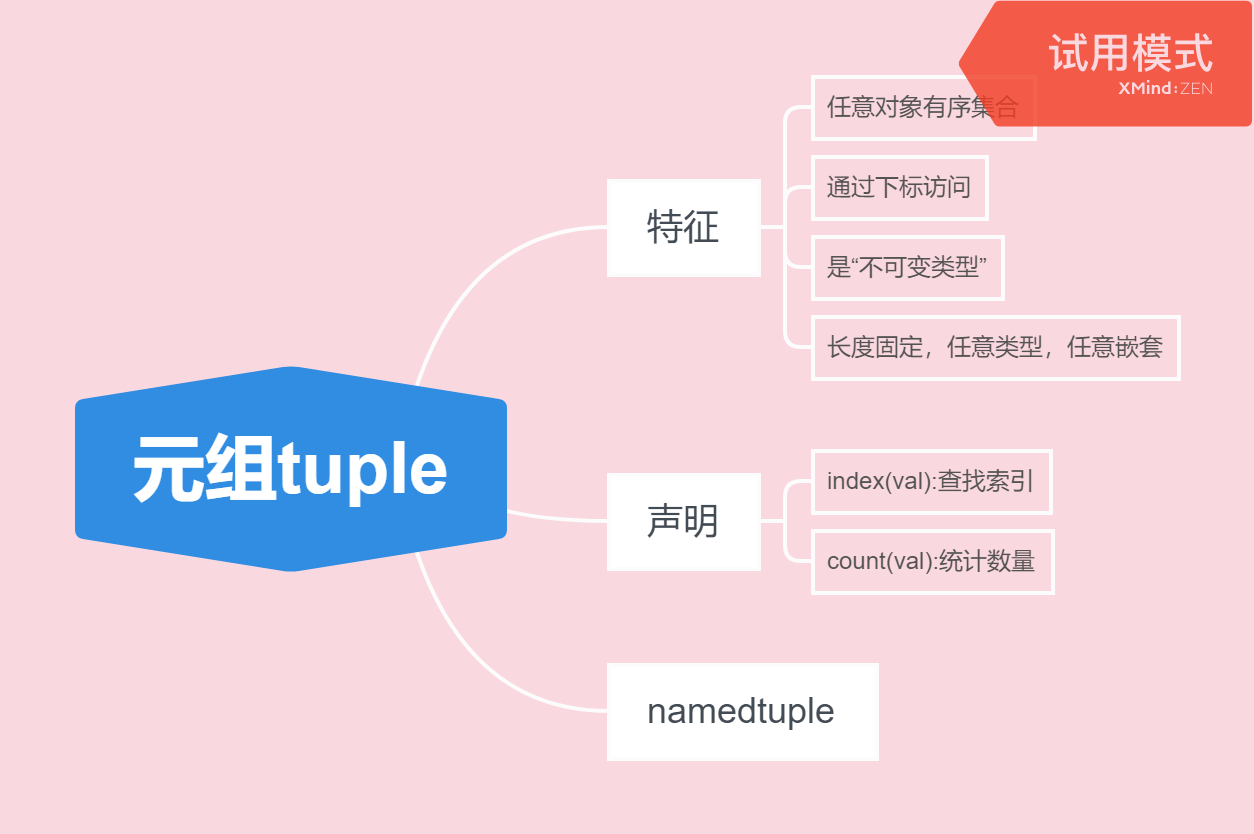
In[2]: (1,2) + (3,4) Out[2]: (1, 2, 3, 4) In[3]: 1,2 #括号可省略 Out[3]: (1, 2) In[4]: x = 40 #普通int变量不是元组 In[5]: x = (40) #普通int变量不是元组 In[6]: x = (40) #元组 In[7]: x Out[7]: 40 In[8]: x = (40,) #都是元组 In[9]: x Out[9]: (40,) In[10]: x = 40, In[11]: x Out[11]: (40,) In[12]: len(x) Out[12]: 1 In[13]: x=5 In[14]: y=10 In[15]: x,y = 5,10 In[16]: x Out[16]: 5 In[17]: y Out[17]: 10 In[18]: x,y = y,x #交换 In[19]: x Out[19]: 10 In[20]: y Out[20]: 5 In[21]: t = (1,2,3,4,5) In[22]: t[0] = 99 #元组不支持给某个赋值 Traceback (most recent call last): File "D:Anaconda3libsite-packagesIPythoncoreinteractiveshell.py", line 3296, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-22-5220ce0d9897>", line 1, in <module> t[0] = 99 #元组不支持给某个赋值 TypeError: 'tuple' object does not support item assignment In[27]: for x in t: ...: print(x**2) ...: 1 4 9 16 25 In[28]: res = [] #申空列表 In[29]: for x in t: ...: res .append(x**2) #追加 ...: res Out[29]: [1, 4, 9, 16, 25] In[30]: res = [x**2 for x in t] #用推导实现,[]代表返回,在元组里找单个元素取得平方值放入list In[31]: res Out[31]: [1, 4, 9, 16, 25] In[32]: t.index(3) #找位置 Out[32]: 2 In[33]: t.count(3) #统计有几个3 Out[33]: 1
namedtuple:定义对象模板实现类,例子是定义员工情况
In[35]: from collections import namedtuple #从集合命名空间导入新类型 Employee = namedtuple('Employee',['name','age',''department','salary']) Jerry = Employee('Jerry',age=30,department='财务部',salary=9000.00)
VI 文件
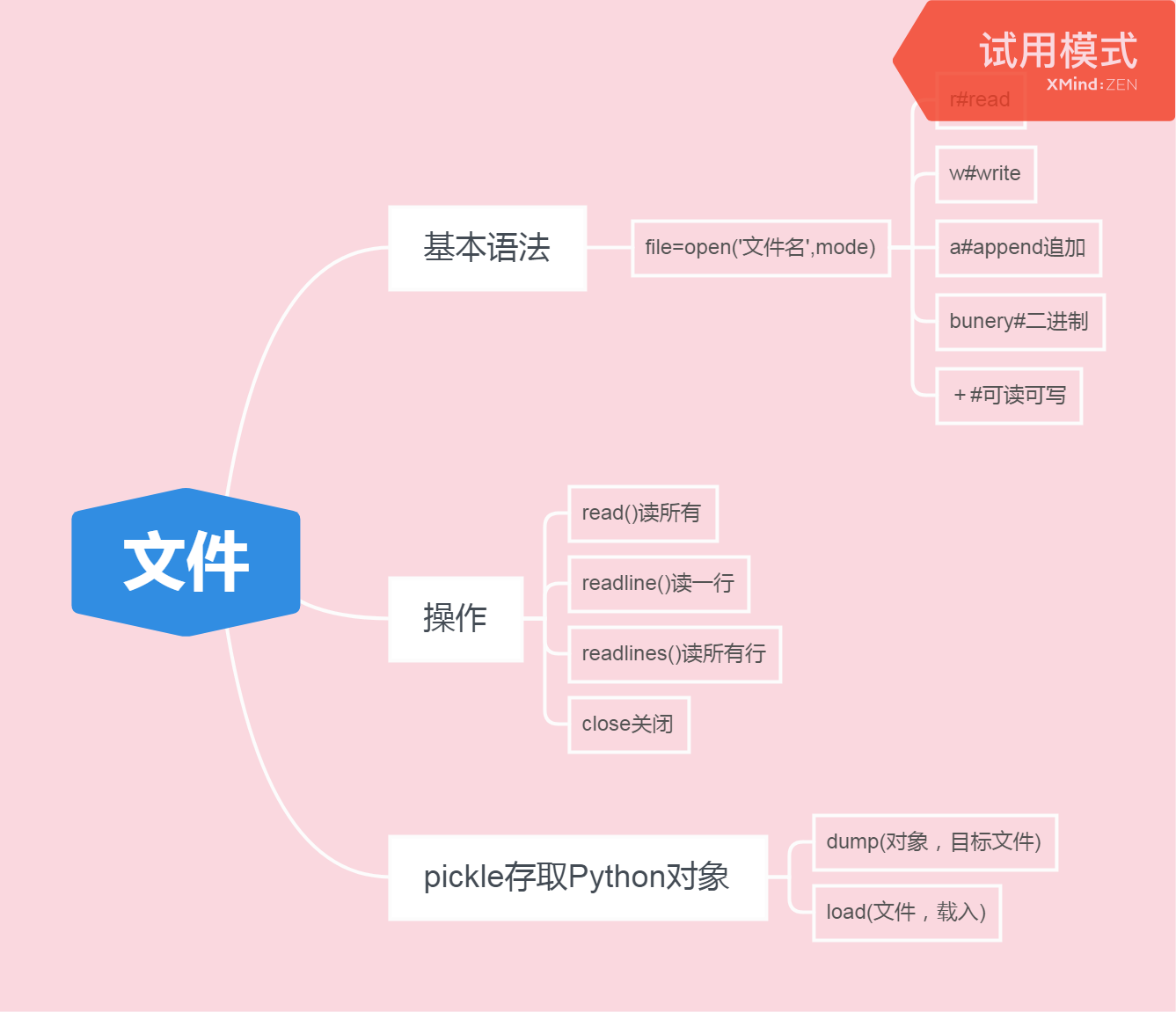
pycharm console创建一个txt
myfile = open('hello.txt,'w') #创建文件,w是写
然后用pycharm运行:demo 右键Syochronize'demo'同步demo
myfile.write('优品课堂 ') #/n换行符,在文件夹里写东西 5 #5个字符 myfile.write('Hello world! ') #再写,查看txt文件 13 #13个字符 f= open('hello.txt','r') #r是读取 f.read() #列出信息read相当于指针内存容器用read一次相当于指针移到某位置 #读取文件 f = open('hello.txt') f.radline() #读取行一次读出来 l = open('hello.txt') #来源于txt文件 l = open('hello.txt').readlines() #加这个返回类行读所有行 做一个for循环 for line in l: print(line) ##空两行是 /n回车 print默认 共空两行 f = open('course.txt','w',ending='utf8') #utf8是编码 f.write('优品课堂 python教程 ') f.count(www.codeclassroom.cn) f.close() #关闭当前文件
也可读取二进制文件 f = open('data.bin','rb').read() #rb是读取写binery 假如有两个变量, x,y,z = 1,2,3 l = [1,2,3] x z l type(x) f = open(‘datafile.txt’,'w')#把上面信息存入文本文件,w是写 f.write('{},{},{}'.format(x,y,z)) #format是放,格式化按顺序放变量 f.write(str()) f.close() chars = open('datafile.txt').read() #读所有信息 chars d = {'a':1,'b':2} #a存1 b存2 f = open('datafile.pkl','wb') #创建二进制 import pickle pickle .dump(d.f) #pickle存储读取本地Python对象,把d塞入f f.close() 看文件啥样 open('datafile.pkl','rb').read() f = open('datafile.pkl','rb') #以read方式读二进制 data = pickle.load(f) #文件载入原样还原 data data['a'] data.get('b') 逐行打印,打印完关闭 f = open('course.txt') l = f.readlines() l for line in l: print (line) with open('course.txt') as f: #打开临时文件取名 放在上下文 注意代码的缩进 for line in f.read lines(): print(line) #每找一项输入一项自动放入资源
python数据里有类型,往文本文件存可能会造成数据类型丢失