hibernate书籍(建议:深入浅出hibernate,hibernate in action[hibernate实战])
在学习hibernate之前老师带我理解的ORM:
ORM是什么?ORM的主要用于做什么?
使用JDBC遇到的问题就是每次都得自己写实体类的Dao,每条SQL语句都得自己手动的书写,没有什么难度。完全就是浪费时间,因此需要使用框架
之所以存在这种ORM(Object Relation Mapping)对象关系映射框架是由于当前开发环境中支持的语言和数据库来决定的。
现在开发使用的语言是OOP
使用的数据库是关系型数据库,要将一个对象保存到关系型数据库中,则在关系型数据库中要存在对应的一张实体类的表,表中的字段对应对象中的属性。在保存对象的时候,将一个对象作为关系型数据库中的一条记录存进去。
ORM框架存在的意义就是为了解决存储数据的时候对象和数据库之间的问题

ORM衍生出来的框架(Hibernate、mybatis、openJPA) 能为我们做些什么
减少乏味的代码
不用每次进行数据库操作的时候写乏味的SQL语句
更加面向对象的设计
在对数据库进行相应的增删改查操作的时候直接使用方法就可以搞定
更好的性能
Hibernate的性能是可以的,不然的话就没有人用这个东西了。如果一个框架的性能很差,那么这个框架是不会这么流行的。
更好的移植性
当切换到不同的数据库的时候,只用更改一下配置文件中的数据库方言部分就可以了。切换数据库的成本很低。
Hibernate使用:
Hibernate官网
hibernate.org
1.加入Hibernate的jar包
使用maven加入hibernate的所有jar包。在导入hibernate核心jar包的时候选择4.2.0版本,4.3版本又废除了一些4.2.0版本中存在的一些常用的方法
2.创建持久化类(pojo)
将之前创建实体类的包包名改成pojo,在这个包中创建实体类,并生成相应的get和set方法
3.创建映射文件(xxx.hbm.xml)
在创建持久化类的包里面创建映射文件。创建实体类和数据库中的表相对应的一个映射文件文件名以实体类的名字开头,后面跟.hbm.xml代表具体的哪个类的映射文件。开始的时候写xml文件的声明部分。然后写入dtd的验证文件,验证文件的文档类型可以从hibernate的核心包中的子包中的一个hibernate-mapping.dtd文件中拷贝过来。在这个时候在文档中按alt+?就会出现提示,首先创建配置文件的根节点<hibernate-mapping>,根节点有一个package属性,用来定义当前pojo类的包的包名例如com.kaishengit.pojo。然后再根节点中定义class节点,class节点中有两个和苏醒name属性和table属性,name属性值是当前pojo类的名字例如User,这个名字是实体类的名字因此首字母大写,table属性值是要告诉hibernate要映射数据库中的哪张表例如user这张表。由于表中有很多字段,最特殊的字段就是主键列这个字段。在class节点中配置id节点用来定义主键列id节点中有两个属性name属性和column属性,name属性用来定义实体类中的属性名称,column属性用来定义user表中的字段名称。id节点中还有generator节点用来定义主键的生成策略,generator节点中具有class属性。目前这张表的主键的生成策略是自动增长。因此节点中的class值是native,用来告诉hibernate这个主键生成策略是自动增长的。在id节点后面配置其他字段的属性值。
property节点用来定义非主键的属性值。
property节点具有name属性和column属性,name属性对应对象中的属性,column对应数据库中的字段名称。当name属性和column属性的值一样的时候,可以只用写name属性值就可以了。
4.创建Hibernate配置文件(hibernate.cfg.xml)
在main.java.resource下面创建hibernate的配置文件,用来告诉hibernate我们使用的是什么数据库,什么样的数据库连接池,数据库驱动、方言等信息。文件的名字是hibernate.cfg.xml.创建好之后引入xml的文档声明部分。引入之后,引入hibernate配置的dtd验证文件。dtd验证文件从hibernate的核心包中找到。创建一个根节点<hibernate-configuration>在根节点中创建session-factory节点,在session-factory节点中创建多个property节点,用来告诉hibernate项目运行的时候所需要的一些数据库和连接池的环境。具体配置的属性可以从hibernate官网下载的源代码包中找到project目录下的etc目录下的hibernate.properties文件,代开就可以看到要配置的所有属性信息。要配置的属性信息有数据库连接的一些信息,数据库方言、在执行数据库操作的时候打印出hibernate自动生成的SQL语句,为每一个thread配置一个session对象。加入pojo的配置文件(Mapping)
5.运行
持久化类:
pojo:Plain Ordinary Java Object(无格式的Java对象)
Hibernate对pojo的要求:
属性要有对应的get和set方法
要有无参数的默认构造方法
不要使用final进行修饰
使用hibernate
首先创建一个configuration对象
Configuration configuration = new Configuration().configure();
创建ServiceRegistry对象
ServiceRegistry serviceRegistry= new
ServiceRegistryBuilder().applySettings(cfg.getProperties()).buildServiceRegistry();
创建sessionFactory对象
SessionFactoryfactory = cfg.buildSessionFactory(serviceRegistry)
获得session对象(此session非彼session)
Session session = factory.getCurrentSession();
在执行数据库操作的时候,hibernate要求要先开启一个事务
//开启事务
session.beginTransaction()
业务逻辑代码写在这里。
//提交事务
session.getTransaction().commit();
//回滚事务
session.getTransaction().rollback();
数据操作
保存一个对象
//开启一个事务
session.beginTransaction();
User user = newUser();
user.setUsername("aa");
user.setPassword("123");
//保存user对象
session.save(user);
session.getTransaction().commit();
根据逐渐来查找到指定对象
session.beginTransaction();
User user = (User) session.get(User.class, 1);
System.out.println(user.getUsername());
session.getTransaction().commit();
修改对象
Session session = factory.getCurrentSession();
session.beginTransaction();
User user = (User) session.get(User.class, 1);
user.setUsername("Alex");
session.getTransaction().commit();
删除对象
Session session = factory.getCurrentSession();
session.beginTransaction();
User user = (User) session.get(User.class, 1);
session.delete(user);
session.getTransaction().commit();
获取所有对象
Session session = factory.getCurrentSession();
session.beginTransaction();
Query query = session.createQuery("from User");
List<User> userList= query.list();
System.out.println(userList.size());
session.getTransaction().commit();
考虑到创建sessionfactory对象的时候只用创建出一个工厂对象,不需要每次运行的时候都创建出一个对象,因此将创建sessionfactory对象写成一个单例模式。
public class HibernateUtil{
private HibernateUtil(){}
public static SessionFactory factory= builderSessionFactory();
private static SessionFactory builderSessionFactory() {
Configuration cfg= newConfiguration().configure();
ServiceRegistry serviceRegistry= new ServiceRegistryBuilder().applySettings(cfg.getProperties()).buildServiceRegistry();
SessionFactoryfactory = cfg.buildSessionFactory(serviceRegistry);
returnfactory;
}
public staticSession getSession() {
return factory.getCurrentSession();
}
}
在获得工厂类对象的时候可以将获得工厂类对象的代码写在一个静态块中,也可以将器写成一个使用private访问修饰符修饰的,静态的方法中。两种方法都可以。
持久化对象:
持久化对象的生命周期
持久化对象的三个状态
自由态(瞬态)
持久态
游离态(托管态)
自由态:
持久化对象的自由态,指的是对象在内存中存在,但是在数据库中并没有数据与其关联。比如Student student = new Student(),这里的student对象就是一个自由态的持久化对象。
持久态:
持久态指的是持久化对象处于由Hibernate管理的状态,这种状态下持久化对象的变化将会被同步到数据库中
游离态:
处于持久态的对象,在其对应的Session实例关闭后,此时对象进入游离态。也就是说Session实例是持久态对象的宿主环境,一旦宿主环境失效,那么持久态对象进入游离状态
游离态和自由态的区别:
游离态对象可以再次与Session进行关联而成为持久态对象。
自由态对象在数据库中没有数据与其对应,但是游离态对象在数据库中有数据与其对应,只不过当前对象不在Session环境中而已。从对象的是否有主键值可以做简单的判断。

Object可以通过new关键字转成自由态。自由态的持久化对象可以通过save、saveOrUpdate、persist方法从自由态转成持久态。通过delete方法转成自由态。Object也可以通过get方法和load方法将通过主键获得的对象转成持久态。持久态对象可以通过close和clear方法从持久态转到游离态,游离态可以通过将当前的持久化对象和session通过update和saveOrUpdate方法建立关联转成持久态。通过delete方法直接转换成自由态。当内存不够的时候处于自由态和游离态的对象将被Java的垃圾回收机制给回收了。
get方法和load方法的区别和联系:
get和load方法都是利用对象的主键值获取相应的对象,并可以使对象处于持久状态。
load方法获取对象时不会立即执行查询操作,而是在第一次使用对象是再去执行查询操作。如果查询的对象在数据库中不存在,load方法返回值不会为null,在第一次使用时抛出org.hibernate.ObjectNotFoundException异常。
使用get方法获取对象时会立即执行查询操作,并且对象在数据库中不存在时返回null值。
save方法和persist方法的区别:
save和persist方法都是将持久化对象保存到数据库中
save方法成功执行后,返回持久化对象的ID
persist方法成功执行后,不会返回持久化对象的ID,persist方法是JPA中推荐使用的方法
save和update方法的区别:
save方法是将自由态的对象进行保存
update方法是将游离态的对象进行保存
update和saveOrUpdate方法的区别:
如果一个对象是游离态或持久态,对其执行update方法后会将对象的修改同步到数据库中,如果该对象是自由态,则执行update方法是没有作用的
在执行saveOrUpdate方法时该方法会自动判断对象的状态,如果为自由态则执行save操作,如果为游离态或持久态则执行update操作
update方法和merge方法:
如果持久化对象在数据库中存在,使用merge操作时进行同步操作。如果对象在数据库不存在,merge对象则进行保存操作
如果对象是游离状态,经过update操作后,对象转换为持久态。但是经过merge操作后,对象状态依然是游离态
saveOrUpdate和merge方法:
saveOrUpdate方法和merge方法的区别在于如果session中存在两个主键值相同的对象,进行saveOrUpdate操作
时会有异常抛出。这时必须使用merge进行操作。
session.beginTransaction();
User user = newUser();
user.setId(120);
user.setUserName("aaaaaaaa");
user.setUserPwd("123123");
User user2 = (User)session.get(User.class, 120);
session.saveOrUpdate(user);//ERROR
session.getTransaction().commit();
clear和flush方法
clear方法是将Session中对象全部清除,当前在Session中的对象由持久态转换为游离态。flush方法则是将持久态对象的更改同步到数据库中。
HQL(Hibernate Query Language)提供了丰富灵活的查询方式,使用HQL进行查询也是Hibernate官方推荐使用的查询方式。
HQL在语法结构上和SQL语句十分的相同,所以可以很快的上手进行使用。使用HQL需要用到Hibernate中的Query对象,该对象专门执行HQL方式的操作。
查找所有
session.beginTransaction();
String hql= "from User";
Query query = session.createQuery(hql);
List<User> userList= query.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
session.beginTransaction();
String hql= "from User where userName= 'James'";
Query query = session.createQuery(hql);
List<User> userList= query.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
在HQL中where语句中使用的是持久化对象的属性名,比如上面示例
中的userName。当然在HQL中也可以使用别名:
String hql = "fromUser as u whereu.userName= 'James'";
过滤条件
在where语句中还可以使用各种过滤条件,如:=、<>、<、>、>=、<=、between、not between、in、not in、
is、like、and、or等。
from Student whereage> 20;
from Student whereagebetween 20 and30;
from Student wherename is null;
from Student wherename like ‘小%’;
from Student wherename like ‘小%’ and age < 30
获取一个不完整对象
session.beginTransaction();
String hql= "select userNamefrom User";
Query query = session.createQuery(hql);
List nameList= query.list();
for(Object obj:nameList){
System.out.println(obj);
}
session.getTransaction().commit();
session.beginTransaction();
String hql= "select userName,userPwdfrom User";
Query query = session.createQuery(hql);
List nameList= query.list();
for(Object obj:nameList){
Object[] array = (Object[]) obj;
System.out.println("name:"+ array[0]);
System.out.println("pwd:"+ array[1]);
}
session.getTransaction().commit();
统计和分组查询
session.beginTransaction();
String hql= "select count( ),max(id) from User";
Query query = session.createQuery(hql);
List nameList= query.list();
for(Object obj:nameList){
Object[] array = (Object[]) obj;
System.out.println("count:"+ array[0]);
System.out.println("max:"+ array[1]);
}
session.getTransaction().commit();
select distinct name from Student;
select max(age) from Student;
select count(age),age from Student groupby age;
from Student orderby age;
占位符
session.beginTransaction();
String hql= "from User where userName= ?";
Query query = session.createQuery(hql);
query.setString(0, "James");
List<User> userList= query.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
引用占位符
session.beginTransaction();
String hql= "from User where userName= :name";
Query query = session.createQuery(hql);
query.setParameter("name", "James");
List<User> userList= query.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
HQL分页
session.beginTransaction();
String hql= "from User";
Query query = session.createQuery(hql);
query.setFirstResult(0);
query.setMaxResults(2);
List<User> userList= query.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
Criteria查询
Criteria对象提供了一种面向对象的方式查询数据库。Criteria对象需要使用Session对象来获得一个Criteria对象表示对一个持久化类的查询
查询所有
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
List<User> userList= c.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
Where条件限制
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
c.add(Restrictions.eq("userName", "James"));
List<User> userList= c.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
List<User> userList= c.list();
Restriction对象

session.beginTransaction();
Criteria c = session.createCriteria(User.class);
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
c.add(Restrictions.like("userName", "J"));
c.add(Restrictions.eq("id", 120));
List<User> userList= c.list();
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
c.add(Restrictions.or(Restrictions.eq("userName", "James"),
Restrictions.eq("userName", "Alex")));
List<User> userList= c.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
获取唯一的记录
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
c.add(Restrictions.eq("id", 120));
User user = (User) c.uniqueResult();
System.out.println(user.getUserName());
session.getTransaction().commit();
分页
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
c.setFirstResult(0);
c.setMaxResults(5);
List<User> userList= c.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
分组统计
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
session.beginTransaction();
Criteria c = session.createCriteria(User.class);
c.setProjection(Projections.sum("id"));
Object obj= c.uniqueResult();
System.out.println(obj);
session.getTransaction().commit();
Projections对象

多个分组与统计
Criteria c = session.createCriteria(User.class);
c.addOrder(Order.desc("id"));
List<User> list = c.list();
for(User user : list){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
Object obj= c.uniqueResult();
System.out.println(obj);
session.getTransaction().commit();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
List<User> userList= c.list();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
for(User user:userList){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
原生SQL
使用原生SQL查询会丧失很多hibernate本身提供的很多功能。比如不在具有数据库的移植性,不能再加入缓存等等。
什么时候要使用原生的SQL来查询呢。当查询关联的表很多的时候,使用Criteria查询或HQL查询效率很低的时候,就可以使用原生的SQL查询。
session.beginTransaction();
String sql= "select id,username,userpwd from t_user";
List list = session.createSQLQuery(sql).list();
for(Object item : list){
Object[] rows = (Object[]) item;
System.out.println("id:"+ rows[0] + "username:"
+ rows[1] + "userpwd:"+ rows[2]);
}
session.getTransaction().commit();
将查询到的结果封装成一个对象
session.beginTransaction();
String sql= "select id,username,userpwd from t_user";
SQLQueryquery = session.createSQLQuery(sql).addEntity(User.class);
List<User> list = query.list();
for(User user : list){
System.out.println(user.getUserName());
}
session.getTransaction().commit();
查询单个的结果
session.beginTransaction();
String sql= "select id,username,userpwd from t_user where id = 2";
SQLQueryquery = session.createSQLQuery(sql).addEntity(User.class);
User user = (User) query.uniqueResult();
System.out.println(user.getUserName());
session.getTransaction().commit();
数据关系映射
一对多、多对一

当两个Pojo类之间的关系是一对多的时候,要在多的这一段存放一的这一段的外键,在声明pojo类的时候,在多的这一端需要声明一的着一段段额外键。在一的这一端存放多的这一端的set集合。
映射文件
User映射文件和Address映射文件
在映射文件中表示两者之间的关系。User这一段有一个存放Address的set,Address这一段有User类的属性。在User的映射文件中,从User这一段来看,user这一端有一个set集合,因此需要配置一个set节点,节点具有name属性,用来定义在User实体类中的set集合的属性的名字。在User这一段,一个user对应多个Address,因此具有一个one-to-many这样的关系映射。在这里面具有class属性,用来定义这个集合中存放的Address实体类。class的属性值,要和package中的属性值共同组成类的完全限定名。除此之外还要具有key这个键,这个键用来定义column属性,用来定义address对应表中的外键名字。
<set name="addressSet">
<key column="userid"/>
<one-to-many class="Address"/>
</set>
set里面的name属性存放在user类中的set属性名,one-to-many用来定义user和address之间的关系,其中的class属性用来定义这个set集合中存放的具体的实体类的类名。key中的column用来定义user在Address对应address表里面的外键的名字
在address映射文件中
address与user之间的关系是many-to-one,name属性用来指定address实体类中use的属性名,class用来定义其相应的类名。column用来定义外键名。
在存地址的时候告诉它这个地址是哪个用户的。
a1.setUser(user);就代表a1我这个新地址是属于a1的。
在一对多的情况下,当多的这一段的外键不允许为null的时候,则先存取一的这一端,再存取多的这一端。因为多的这一端需要获取一的这一端的值作为外键。
放宽约束政策。允许adderss表中设置的外键列的名字允许为null。保存address对象和user对象的时候,先保存address对象,然后在保存user对象。
session.save(a1);
session.save(a2);
session.save(user);
保存a1,a2到数据库中,这时候外键列还是null,因为a1和user虽然建立关系了,但是还没有user的主键id,当保存user对象的时候就会有userid,这是Hibernate就会知道a1和a2相应的user对象有主键值了,自动产生两条update语句来维护address和user之间的关系。之所以自动产生两条update语句,是因为a1.setUser(user);设置了两者的关联关系。
更复杂的一种情况。
在建立关系的时候,可以让多的这一端建立于一的这一端的关系。
Set<Address> set = new HashSet<Address>();
set.add(a1);
set.add(a2);
user.setAddressSet(set);
这个时候保存的时候,先保存user,在保存Address,当user存进去的时候会产生userid,再存a1和a2,这个时候是有外键值的,最后两条update就是完全没有必要的。先保存user对象,a1,a2是自由态,保存之后是持久态,状态发生改变。user和Address之间有关联,要将这种改变同步到数据库中。
效率最低的情况
两者对来维护这个关系。并且先存多的这一端。再存一的这一端。
为了防止一的这一端来维护两者之间的关系。在一的这一端放弃关系的维护。在set中设置inverse=“true",表示要放弃维护关系。
查询:
查询user对象的视乎,当要使用Address集合的时候,以面向对象的方式来获得存放Address的set集合。以延迟加载的方式来获得数据。提高性能。但是有时候确实需要在获得user对象的时候就获得Address,不需要再执行一条select再获得address集合。可以在set中配置fetch属性,属性值为join,表示在查询user的 时候,就把该user对应的所有address集合都查询出来。
也可以通过Address来查找到该Address对应的user。
删除:
删除子表问题不大。
删除主表数据的时候,是主表关联的子表自动删除。在user这有端的set中配置cascade的属性值为delete表示删除主表的时候,先删除子表的数据,然后在删除主表的数据。
使用这个功能的时候,要看看具体的业务在决定是否要配置这个属性。
一对一
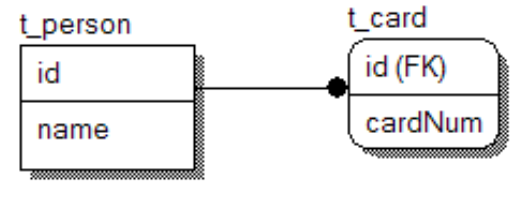
关系描述:
一个Person只能有一个card对象,一个card也只能对应一个Person对象,card表中的主键既充当主键又充当外键。
新建pojo实体类、生成get和set方法。一对一,两个怎么存,Person中有唯一的card对象,card中有唯一的Person对象,生成get和set方法。创建映射文件。Person表中的主键自动增长。card主键生成策略是foreign,代表这个主键生成是通过外键来获得的,这个外键所关联的表需要通过另一个表的引用来获得。告诉card对象这个card对象是属于哪个人的。当前的主键id是一个外建类型的主键生成器,这个外键值从person里面来,这个person是card里面的一个属性,这个属性对应这张表。
<id name="id" column="id">
<generator name="foreign">
<param name="property">person</param>
</generator>
</id>
person还有card属性,他们两个之间到关系也是一对一
<one-to-one name="card" class="Card"/>
person中有card属性,对应的class属性值为Card的类名
card中有person,两者之间的关系依然是一对一。
<one-to-one name="person" class="Person"/>
在hibernate配置文件中添加映射文件
在Test中创建person对象和card对象,保存的时候会报主键生成异常。这是因为在保存Card对象的时候,保存的主键生成策略是foreign,需要通过另一个对象person的主键值来定义自己的主键值同时也是外键,因此在保存Card对象的时候设置它的主键值来自于哪个person对象,因此在save之后,card.setPerson(person);用来关联card对象和person对象之间的关系。
在保存person对象和Card对象的时候,先保存person再保存card对象,当先保存card在保存person的时候,hibernate会自动纠错。
另外一种关系维护的情况
在新建person和card对象,让person来维护关系,只保存person对象的时候只会插入一条insert person这一条记录。hibernate不会自动保存card对象,也不报错。在person的映射文件中设置one-to-one节点的cascade属性为save-update表示在保存person的时候可以级联保存card对象,依然报主键生成异常,这事使用c.setPerson(person)来维护两者之间的关系保存就可以正常了。
查询person对象的时候会自动加载card对象,不能通过配置来设置懒加载,把fetch属性设置为select,会再执行一条单独的select,当只要card对象的时候,同样的也会自动加载person。
更新操作:
更新person的名字的时候,card对象不会更新,p.setCard(null)的时候hibernate会自动忽略这句话。
级联删除:person不在的时候,card对象的存在也就没有意义,配置cascade属性为all,表示person更新的时候card对象也进行更新。
一对一外键关联
这种一对一(唯一关联外键)实际上是多对一的一个变种
t_person t_card
id(PK) id(PK)
name cardnum
cardid(FK,unique) pid(FK,unique)
这种设计的好处是懒加载
创建pojo类,在多的这段一端放一的对象(每个pojo类都是多)
card中的映射配置
<many-to-one name="post" class="Post" column="pid" unique="true">
在映射文件中加unique属性,表示唯一的,在进行保存操作的时候两者都来维护关系。
查询:好处就是可以懒加载
删除数据的时候执行了5条SQL语句:
两条insert语句:
一条update语句
两条delete语句
根据get方法查询到执行的person对象,根据person对象查询到card对象,设置card对象的pid为null,这个时候指定的person对象就没有再被card对象引用就可以删除。然后再删除card对象。
多对多
老师和学生的关系:
创建pojo类,每个类都有一个对应的set集合,存放关系映射的对象。关系表不需要设置pojo类。
映射文件
<set name="students" table="关系表的名字">
<key column="teacher对象在关系表中的外键名"/>
<many-to-many class="student" column="Student对象在关系表中的外键名"/>
</set>
缓存
一级缓存(内置缓存)
一级缓存在Session中实现,当Session关闭时一级缓存就失效了。
一级缓存是在session中的,作用范围就是整个session,当查询的时候首先从一级缓存中拿,如果一级缓存中没有数据的话从二级缓存中找,如果二级缓存中也没有的话就从数据库中查找。一级缓存中的内容只在这个session中有作用,如果session关闭或者除了这个session的作用范围就没有作用
session.beginTransaction();
User user= (User) session.get(User.class, 2);
User user2 = (User) session.get(User.class, 2);
session.getTransaction().commit();
判断对象是否存在于一级缓存中
session.beginTransaction();
User user= (User) session.get(User.class, 2);
System.out.println(session.contains(user));
User user2 = (User) session.get(User.class, 2);
System.out.println(session.contains(user2));
session.getTransaction().commit();
clear方法和evit方法
clear方法用于将所有对象从一级缓存中清除
evict方法用于将指定对象从一级缓存中清除
session.beginTransaction();
User user= (User) session.get(User.class, 2);
session.evict(user);
User user2 = (User) session.get(User.class, 2);
session.getTransaction().commit();
二级缓存
在Hibernate中二级缓存在SessionFactory中实现,由一个SessionFactory的所有Session实例所共享。Session在查找一个对象时,会首先在自己的一级缓存中进行查找,如果没有找到,则进入二级缓存中进行查找,如果二级缓存中存在,则将对象返回,如果二级缓存中也不存在,则从数据库中获得。
Hibernate并未提供对二级缓存的产品化实现,而是为第三方缓存组件的使用提供了接口,当前Hibernate支持的第
三方二级缓存的实现如下:
EHCache
Proxool
OSCache
SwarmCache
JBossCache
Ehcache使用步骤:
1、导入jar包
2、在Hibernate配置文件中开启二级缓存,配置文件开启的选项从hibernate.properties文件中找到
设置二级缓存的工厂类(官方给的是错误的,从ehcache的jar包中找)
ehcache配置文件
<ehcache>
<!-- 当内存不够的时候将缓存的内容放到硬盘上 -->
<diskStore path="java.io.tmpdir"/>
<defaultCache
maxElementsInMemory=“10000“ →缓存中最大允许保存的对象数量
eternal=“false“ →缓存中数据是否为常量
timeToIdleSeconds=“120“ →缓存数据钝化时间,单位为秒
timeToLiveSeconds=“120“ →缓存数据生存时间,单位为秒
overflowToDisk=“true“ →内存不足时,是否启用磁盘缓存
/>
开启二级缓存

</ehcache>
3、在实体类的映射文件中设置缓存和缓存策略
缓存策略:

将指定对象从二级缓存中清除

并发:
当用户A在对一个userA这个对象进行更新操作的时候,还没有进行事务提交,这个时候用户B也对userA进行了修改操作,将用户名修改为tom,然后提交,用户A将UserA的用户名修改成了Jack,这个时候提交,用户名最终是Jack,但是用户B发现结果就不对了,这个时候并发问题就产生了。并发问题产生的原因就是多个事务并行的同时对数据库表中的一条记录进行操作。
并发问题的产生是源于对同一个对象进行操作。
这个事务读到了另一个事务中还没有提交的事务中的数据叫做脏读。
这个事务读取两次的内容不一致叫做非重复读
这个事务读到了其他事务提交过后的数据叫做幻读
最高级别:串行事务
为了防止并发问题
解决这种问题的两种办法:
1、乐观锁
在对数据进行更新操作的时候,首先在表中建立一个字段用来记录当前这个数据的版本号,或者采用时间戳的方式来记录当前记录最后的更新时间,时间为1970年以后的毫秒值(尽量不要采用这种方式来记录,因为并发问题产生的时间片也就在那几毫秒内 ,使用JVM返回的1970年以后的毫秒值可能不准),最好的方式在表中加上version这样的字段用来记录记录修改的版本号是多少,当事务每对这个记录进行了一次操作的时候都更新这个版本号。当事务获取这条记录的时候同时也获取当前记录的版本号,当提交的 时候比对事务之前获得的版本号和当前数据库中的版本号是否一致,如果数据库中当前的版本号大于事务中获得的版本号,则说明在事务处理这一端时间,已经有别的事务对该事务进行了操作。因此会抛出异常,当抛出异常的时候我们回滚事务。当数据库中的版本号和事务中的版本号相同的时候,就可以进行更行操作
实现方式:
在数据库中相应的持久化类的表中新建一个字段用来记录数据的版本号或者最后修改该数据的时间戳(由于JVM生成的时间毫秒数会有误差,而数据并发问题就是产生在几毫秒之内,因此不建议使用)。在持久化类中新建version属性,生成get和set方法。在持久化类的映射文件中配置该字段产生方式为version
<version name="version"/>
这个版本号在用户get方式获取的时候这个版本号不能为null,否则会出现NullPointerException,当保存持久化对象的时候可以默认的版本号从0开始,
当每对这个数据进行更改一次,数据的版本就会自动加一。
2、悲观锁
使用悲观锁是在session在使用get方法获得对象的时候,给这个get方法传入一个参数,这个参数就是用来给这个记录加上一个锁,表示在这个事务还没有提交之前,任何事务都不能对这条记录进行操作。从而使之前的并发问题回到了串行上面。使用这个方法效率会很低,是否使用这个方法可以根据具体的业务级别来定,金融方面的会使用这个来控制数据安全。
User user = sessioin.get(User.class,4,LockOptions.UPGRADE);
编程式事务
当事务提交的时候无论是否发生异常都try...catch一下,当发生异常的时候让这个事务回滚。这是一种最标准的做法。
annotation
hibernatepojo


每一个持久化POJO类都是一个实体bean,这可以通过在类的定义中使用@Entity注解来进行声明: 通过@Entity注解将一个类声明为一个实体bean(即一个持久化POJO类), @Id注解则声明了该实体bean的标识属性. 其他的映射定义是隐式的.这种以隐式映射为主体,以显式映射为例外的配置方式在新的EJ3规范中处于非常重要的位置, 和以前的版本相比有了质的飞跃. 在上面这段代码中:Flight类映射到Flight表,并使用id列作为主键列.
@Table是类一级的注解, 通过@Table注解可以为实体bean映射指定表(table),目录(catalog)和schema的名字. 如果没有定义@Table,那么系统自动使用默认值:实体的短类名(不附带包名).@Table元素包括了一个schema 和一个 catalog属性,如果需要可以指定相应的值. 结合使用@UniqueConstraint注解可以定义表的唯一约束(unique constraint) (对于绑定到单列的唯一约束,请参考@Column注解)
@org.hibernate.annotations.Cache定义了缓存策略及给定的二级缓存的范围. 此注解适用于根实体(非子实体),还有集合.
(1) usage: 给定缓存的并发策略(NONE, READ_ONLY, NONSTRICT_READ_WRITE, READ_WRITE, TRANSACTIONAL)
(2) region (可选的):缓存范围(默认为类的全限定类名或是集合的全限定角色名)
(3) include (可选的):值为all时包括了所有的属性(proterty), 为non-lazy时仅含非延迟属性(默认值为all)
使用@Id注解可以将实体bean中的某个属性定义为标识符(identifier). 该属性的值可以通过应用自身进行设置, 也可以通过Hiberante生成(推荐). 使用 @GeneratedValue注解可以定义该标识符的生成策略:
AUTO - 可以是identity column类型,或者sequence类型或者table类型,取决于不同的底层数据库.
TABLE - 使用表保存id值
IDENTITY - identity column
SEQUENCE - sequence
使用 @Column 注解可将属性映射到列. 使用该注解来覆盖默认值
(1) name 可选,列名(默认值是属性名)
(2) unique 可选,是否在该列上设置唯一约束(默认值false)
(3) nullable 可选,是否设置该列的值可以为空(默认值false)
(4) insertable 可选,该列是否作为生成的insert语句中的一个列(默认值true)
(5) updatable 可选,该列是否作为生成的update语句中的一个列(默认值true)
(6) columnDefinition 可选: 为这个特定列覆盖SQL DDL片段 (这可能导致无法在不同数据库间移植)
(7) table 可选,定义对应的表(默认为主表)
(8) length 可选,列长度(默认值255)
(8) precision 可选,列十进制精度(decimal precision)(默认值0)
(10) scale 可选,如果列十进制数值范围(decimal scale)可用,在此设置(默认值0)
onetomany
在属性级使用 @OneToMany注解可定义一对多关联.一对多关联可以是双向关联.而一对多这端的关联注解为@OneToMany( mappedBy=... )
onetoone
使用@OneToOne注解可以建立实体bean之间的一对一的关联. 一对一关联有三种情况: 一是关联的实体都共享同样的主键, 二是其中一个实体通过外键关联到另一个实体的主键 (注意要模拟一对一关联必须在外键列上添加唯一约束). 三是通过关联表来保存两个实体之间的连接关系 (注意要模拟一对一关联必须在每一个外键上添加唯一约束).
manytoone
在实体属性一级使用@ManyToOne注解来定义多对一关联:
@manytomany
@joincolumn
@jointable
@primarykeyjoincolumn
@transient
@Genericgenerator
@orderby("id desc")
级联查询
当级联查询(主要用于搜索的时候需要根据多个条件来进行搜索,并且这些条件来自多个表)的时候就需要使用Hibernate查询的高级查询。在BaseDao中重载BuildCriteriaByFilterList方法,重载后的方法中传入一个Criteria对象,这个对象从调用这个方法的调用方获得,例如从findPageByPageNoAndFilterListAndOrderBy();中获得,将原来的方法重载,然后在新的重载后的方法中加入Criteria参数。这个参数从BaseDao中的子类Dao中获得,子类Dao中通过继承父类中BuildCriteria的方法来创建出Criteria对象,并根据创建爱你后的Criteria对象来create出一个别名,别名的名字是多表联查的时候需要的标明,例如在查询就诊记录的时候需要根据病人的名字和电话来找到相应的病情记录。因此别名的命名就是病人档案实体类pojo的名字----patient,在查询条件的后面加上要查询条件对应的属性名就可以了。例如根据病人的名字来查询出相应的病情信息,表单中name属性值为q_eq_s_patient.username这样就可以在查询的时候直接使用Hibernate提供的级联查询来查询出相应的病情记录。