偶然看到一篇文章,不仅有Python的应用可视化创建新库,又有机器学习,感觉开源的世界真是很牛...
GItHub官方为:https://github.com/streamlit/streamlit/
Streamlit 网站:https://streamlit.io/
如果你用的是Anaconda3大礼包,你要用conda 安装:streamlit
$ pip install --upgrade streamlit opencv-python $ streamlit run https://raw.githubusercontent.com/streamlit/demo-self- driving/master/app.py
也可下载app.py,我这里是write.py。
其中有个用YOLO V3的特别好
# -*- coding: utf-8 -*-
# Copyright 2018-2019 Streamlit Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This demo lets you to explore the Udacity self-driving car image dataset.
# More info: https://github.com/streamlit/demo-self-driving
import streamlit as st
import altair as alt
import pandas as pd
import numpy as np
import os, urllib, cv2
# Streamlit encourages well-structured code, like starting execution in a main() function.
def main():
# Render the readme as markdown using st.markdown.
readme_text = st.markdown(get_file_content_as_string("instructions.md"))
# Download external dependencies.
for filename in EXTERNAL_DEPENDENCIES.keys():
download_file(filename)
# Once we have the dependencies, add a selector for the app mode on the sidebar.
st.sidebar.title("What to do")
app_mode = st.sidebar.selectbox("Choose the app mode",
["Show instructions", "Run the app", "Show the source code"])
if app_mode == "Show instructions":
st.sidebar.success('To continue select "Run the app".')
elif app_mode == "Show the source code":
readme_text.empty()
st.code(get_file_content_as_string("streamlit_app.py"))
elif app_mode == "Run the app":
readme_text.empty()
run_the_app()
# This file downloader demonstrates Streamlit animation.
def download_file(file_path):
# Don't download the file twice. (If possible, verify the download using the file length.)
if os.path.exists(file_path):
if "size" not in EXTERNAL_DEPENDENCIES[file_path]:
return
elif os.path.getsize(file_path) == EXTERNAL_DEPENDENCIES[file_path]["size"]:
return
# These are handles to two visual elements to animate.
weights_warning, progress_bar = None, None
try:
weights_warning = st.warning("Downloading %s..." % file_path)
progress_bar = st.progress(0)
with open(file_path, "wb") as output_file:
with urllib.request.urlopen(EXTERNAL_DEPENDENCIES[file_path]["url"]) as response:
length = int(response.info()["Content-Length"])
counter = 0.0
MEGABYTES = 2.0 ** 20.0
while True:
data = response.read(8192)
if not data:
break
counter += len(data)
output_file.write(data)
# We perform animation by overwriting the elements.
weights_warning.warning("Downloading %s... (%6.2f/%6.2f MB)" %
(file_path, counter / MEGABYTES, length / MEGABYTES))
progress_bar.progress(min(counter / length, 1.0))
# Finally, we remove these visual elements by calling .empty().
finally:
if weights_warning is not None:
weights_warning.empty()
if progress_bar is not None:
progress_bar.empty()
# This is the main app app itself, which appears when the user selects "Run the app".
def run_the_app():
# To make Streamlit fast, st.cache allows us to reuse computation across runs.
# In this common pattern, we download data from an endpoint only once.
@st.cache
def load_metadata(url):
return pd.read_csv(url)
# This function uses some Pandas magic to summarize the metadata Dataframe.
@st.cache
def create_summary(metadata):
one_hot_encoded = pd.get_dummies(metadata[["frame", "label"]], columns=["label"])
summary = one_hot_encoded.groupby(["frame"]).sum().rename(columns={
"label_biker": "biker",
"label_car": "car",
"label_pedestrian": "pedestrian",
"label_trafficLight": "traffic light",
"label_truck": "truck"
})
return summary
# An amazing property of st.cached functions is that you can pipe them into
# one another to form a computation DAG (directed acyclic graph). Streamlit
# recomputes only whatever subset is required to get the right answer!
metadata = load_metadata(os.path.join(DATA_URL_ROOT, "labels.csv.gz"))
summary = create_summary(metadata)
# Uncomment these lines to peek at these DataFrames.
# st.write('## Metadata', metadata[:1000], '## Summary', summary[:1000])
# Draw the UI elements to search for objects (pedestrians, cars, etc.)
selected_frame_index, selected_frame = frame_selector_ui(summary)
if selected_frame_index == None:
st.error("No frames fit the criteria. Please select different label or number.")
return
# Draw the UI element to select parameters for the YOLO object detector.
confidence_threshold, overlap_threshold = object_detector_ui()
# Load the image from S3.
image_url = os.path.join(DATA_URL_ROOT, selected_frame)
image = load_image(image_url)
# Add boxes for objects on the image. These are the boxes for the ground image.
boxes = metadata[metadata.frame == selected_frame].drop(columns=["frame"])
draw_image_with_boxes(image, boxes, "Ground Truth",
"**Human-annotated data** (frame `%i`)" % selected_frame_index)
# Get the boxes for the objects detected by YOLO by running the YOLO model.
yolo_boxes = yolo_v3(image, confidence_threshold, overlap_threshold)
draw_image_with_boxes(image, yolo_boxes, "Real-time Computer Vision",
"**YOLO v3 Model** (overlap `%3.1f`) (confidence `%3.1f`)" % (overlap_threshold, confidence_threshold))
# This sidebar UI is a little search engine to find certain object types.
def frame_selector_ui(summary):
st.sidebar.markdown("# Frame")
# The user can pick which type of object to search for.
object_type = st.sidebar.selectbox("Search for which objects?", summary.columns, 2)
# The user can select a range for how many of the selected objecgt should be present.
min_elts, max_elts = st.sidebar.slider("How many %ss (select a range)?" % object_type, 0, 25, [10, 20])
selected_frames = get_selected_frames(summary, object_type, min_elts, max_elts)
if len(selected_frames) < 1:
return None, None
# Choose a frame out of the selected frames.
selected_frame_index = st.sidebar.slider("Choose a frame (index)", 0, len(selected_frames) - 1, 0)
# Draw an altair chart in the sidebar with information on the frame.
objects_per_frame = summary.loc[selected_frames, object_type].reset_index(drop=True).reset_index()
chart = alt.Chart(objects_per_frame, height=120).mark_area().encode(
alt.X("index:Q", scale=alt.Scale(nice=False)),
alt.Y("%s:Q" % object_type))
selected_frame_df = pd.DataFrame({"selected_frame": [selected_frame_index]})
vline = alt.Chart(selected_frame_df).mark_rule(color="red").encode(x = "selected_frame")
st.sidebar.altair_chart(alt.layer(chart, vline))
selected_frame = selected_frames[selected_frame_index]
return selected_frame_index, selected_frame
# Select frames based on the selection in the sidebar
@st.cache(hash_funcs={np.ufunc: str})
def get_selected_frames(summary, label, min_elts, max_elts):
return summary[np.logical_and(summary[label] >= min_elts, summary[label] <= max_elts)].index
# This sidebar UI lets the user select parameters for the YOLO object detector.
def object_detector_ui():
st.sidebar.markdown("# Model")
confidence_threshold = st.sidebar.slider("Confidence threshold", 0.0, 1.0, 0.5, 0.01)
overlap_threshold = st.sidebar.slider("Overlap threshold", 0.0, 1.0, 0.3, 0.01)
return confidence_threshold, overlap_threshold
# Draws an image with boxes overlayed to indicate the presence of cars, pedestrians etc.
def draw_image_with_boxes(image, boxes, header, description):
# Superpose the semi-transparent object detection boxes. # Colors for the boxes
LABEL_COLORS = {
"car": [255, 0, 0],
"pedestrian": [0, 255, 0],
"truck": [0, 0, 255],
"trafficLight": [255, 255, 0],
"biker": [255, 0, 255],
}
image_with_boxes = image.astype(np.float64)
for _, (xmin, ymin, xmax, ymax, label) in boxes.iterrows():
image_with_boxes[int(ymin):int(ymax),int(xmin):int(xmax),:] += LABEL_COLORS[label]
image_with_boxes[int(ymin):int(ymax),int(xmin):int(xmax),:] /= 2
# Draw the header and image.
st.subheader(header)
st.markdown(description)
st.image(image_with_boxes.astype(np.uint8), use_column_width=True)
# Download a single file and make its content available as a string.
@st.cache(show_spinner=False)
def get_file_content_as_string(path):
url = 'https://raw.githubusercontent.com/streamlit/demo-self-driving/master/' + path
response = urllib.request.urlopen(url)
return response.read().decode("utf-8")
# This function loads an image from Streamlit public repo on S3. We use st.cache on this
# function as well, so we can reuse the images across runs.
@st.cache(show_spinner=False)
def load_image(url):
with urllib.request.urlopen(url) as response:
image = np.asarray(bytearray(response.read()), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
image = image[:, :, [2, 1, 0]] # BGR -> RGB
return image
# Run the YOLO model to detect objects.
def yolo_v3(image, confidence_threshold, overlap_threshold):
# Load the network. Because this is cached it will only happen once.
@st.cache(allow_output_mutation=True)
def load_network(config_path, weights_path):
net = cv2.dnn.readNetFromDarknet(config_path, weights_path)
output_layer_names = net.getLayerNames()
output_layer_names = [output_layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
return net, output_layer_names
net, output_layer_names = load_network("yolov3.cfg", "yolov3.weights")
# Run the YOLO neural net.
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
layer_outputs = net.forward(output_layer_names)
# Supress detections in case of too low confidence or too much overlap.
boxes, confidences, class_IDs = [], [], []
H, W = image.shape[:2]
for output in layer_outputs:
for detection in output:
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
if confidence > confidence_threshold:
box = detection[0:4] * np.array([W, H, W, H])
centerX, centerY, width, height = box.astype("int")
x, y = int(centerX - (width / 2)), int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
class_IDs.append(classID)
indices = cv2.dnn.NMSBoxes(boxes, confidences, confidence_threshold, overlap_threshold)
# Map from YOLO labels to Udacity labels.
UDACITY_LABELS = {
0: 'pedestrian',
1: 'biker',
2: 'car',
3: 'biker',
5: 'truck',
7: 'truck',
9: 'trafficLight'
}
xmin, xmax, ymin, ymax, labels = [], [], [], [], []
if len(indices) > 0:
# loop over the indexes we are keeping
for i in indices.flatten():
label = UDACITY_LABELS.get(class_IDs[i], None)
if label is None:
continue
# extract the bounding box coordinates
x, y, w, h = boxes[i][0], boxes[i][1], boxes[i][2], boxes[i][3]
xmin.append(x)
ymin.append(y)
xmax.append(x+w)
ymax.append(y+h)
labels.append(label)
boxes = pd.DataFrame({"xmin": xmin, "ymin": ymin, "xmax": xmax, "ymax": ymax, "labels": labels})
return boxes[["xmin", "ymin", "xmax", "ymax", "labels"]]
# Path to the Streamlit public S3 bucket
DATA_URL_ROOT = "https://streamlit-self-driving.s3-us-west-2.amazonaws.com/"
# External files to download.
EXTERNAL_DEPENDENCIES = {
"yolov3.weights": {
"url": "https://pjreddie.com/media/files/yolov3.weights",
"size": 248007048
},
"yolov3.cfg": {
"url": "https://raw.githubusercontent.com/pjreddie/darknet/master/cfg/yolov3.cfg",
"size": 8342
}
}
if __name__ == "__main__":
main()
如果代码执行不了,下载streamlit_app.py
会等会儿:
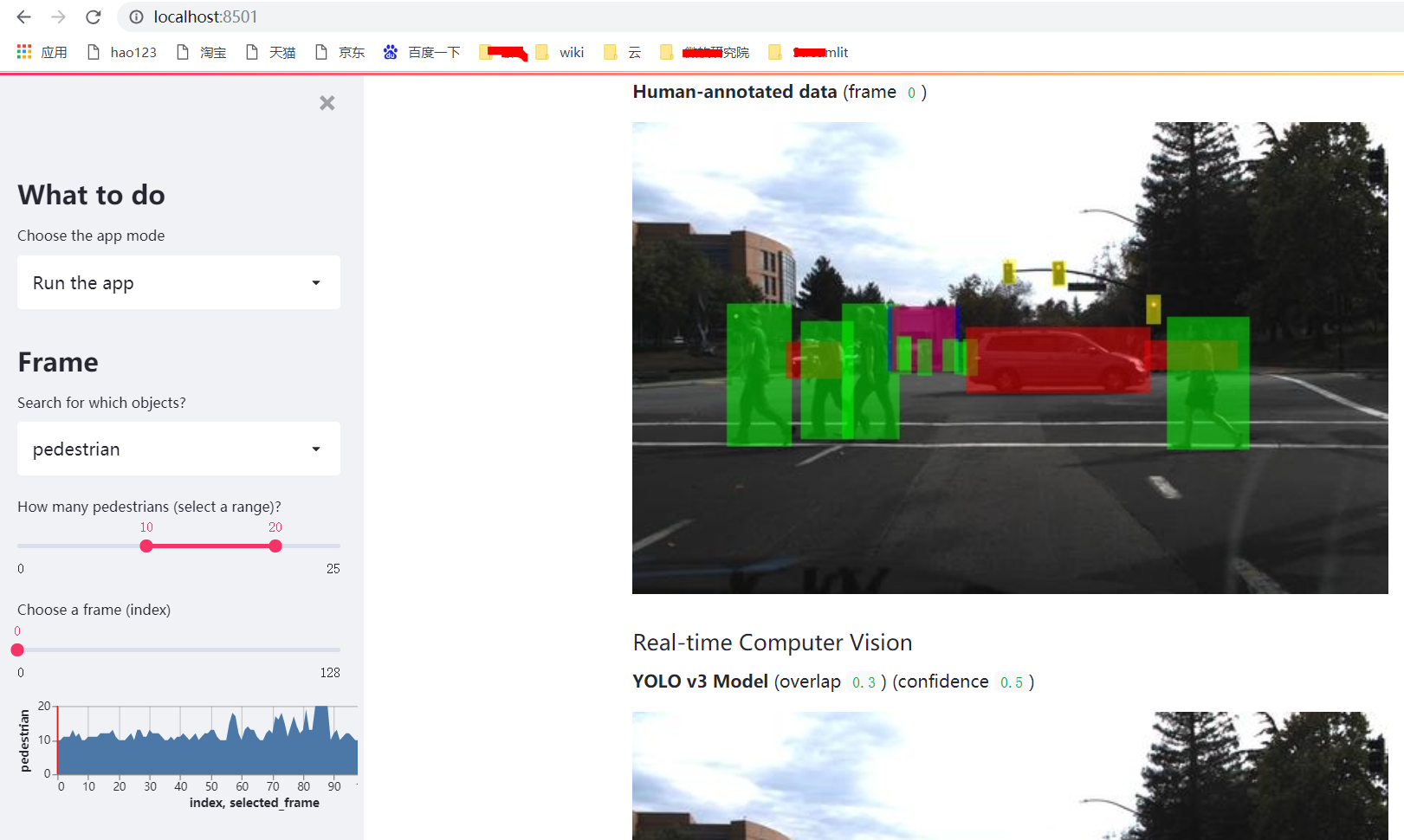
效果很好,对于学习云、python、深度学习,可以“一用打尽”。
https://docs.streamlit.io/en/stable/tutorial/create_a_data_explorer_app.html#create-an-app