Spark StandAlone模式和On Yarn模式搭建
Spark StandAlone模式
上传并解压
tar -zxvf spark-3.0.2-bin-hadoop3.2.tgz -C /data/soft/
修改配置文件
# 进入conf文件夹目录
cd /data/soft/spark-3.0.2-bin-hadoop3.2/conf
- spark-env.sh
# 修改文件名
mv spark-env.sh.template spark-env.sh
# 修改spark-env.sh
vi spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8
export SPARK_MASTER_HOST=bigdata01
- slaves
mv slaves.template slaves
vi slaves
# 配置bigdata02/bigdata03为从节点
bigdata02
bigdata03
分发
scp -r /data/soft/spark-3.0.2-bin-hadoop3.2/ root@bigdata02:/data/soft/
启动集群
sbin/start-all.sh
启动完毕后, 使用jps命令,在主节点bigdata01上可以看到master进程,在从节点bigdata02/bigdata03上可以看到worker进程。
Web UI测试
Spark Web UI http://bigdata01:8080/
测试
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://bigdata01:7077 examples/jars/spark-examples_2.12-3.0.2.jar 2
停止集群
sbin/stop-all.sh
Spark on Yarn 模式
上传并解压
tar -zxvf spark-3.0.2-bin-hadoop3.2.tgz -C /data/soft/
修改配置文件
# 进入conf文件夹目录
cd /data/soft/spark-3.0.2-bin-hadoop3.2/conf
- Spark-env.sh
# 修改文件名
mv spark-env.sh.template spark-env.sh
# 修改spark-env.sh
vi spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8
export HADOOP_CONF_DIR=/data/soft/hadoop-3.2.0/etc/hadoop
测试
- 提交测试任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.12-3.0.2.jar 2
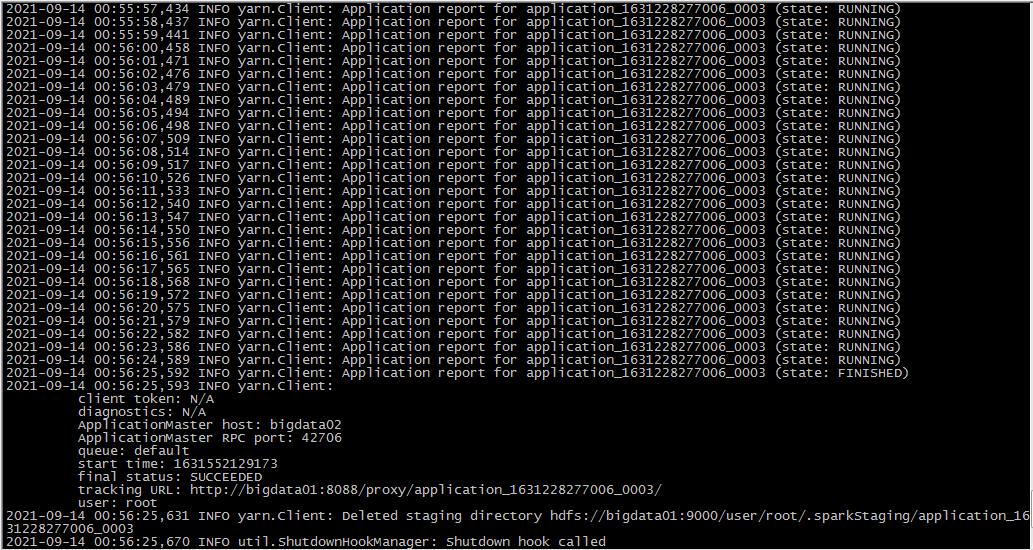
去Yarn上查看任务状态
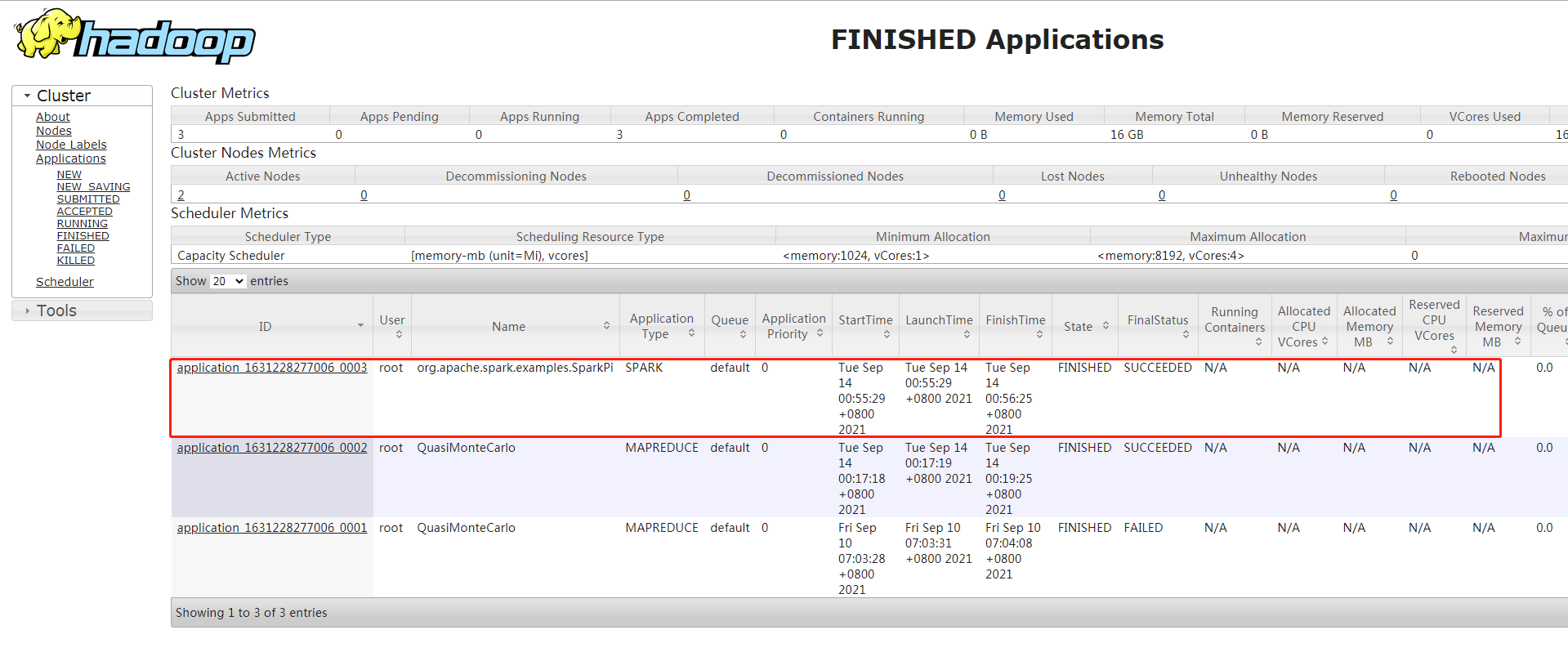
总结
Standalone:独立集群模式适合学习过程。
On Yarn 共用Hadoop集群资源推荐使用