1.准备工作:
网址:https://lishi.tianqi.com/xian/index.html
爬虫类库:PyQuery,requests
2.网页分析:

红线部分可更改为需要爬取的城市名,如:beijing

红框选中部分即为我们所需要爬取的每个月份的信息. 目测应该是ui li,使用Chrome F12 查看下源代码
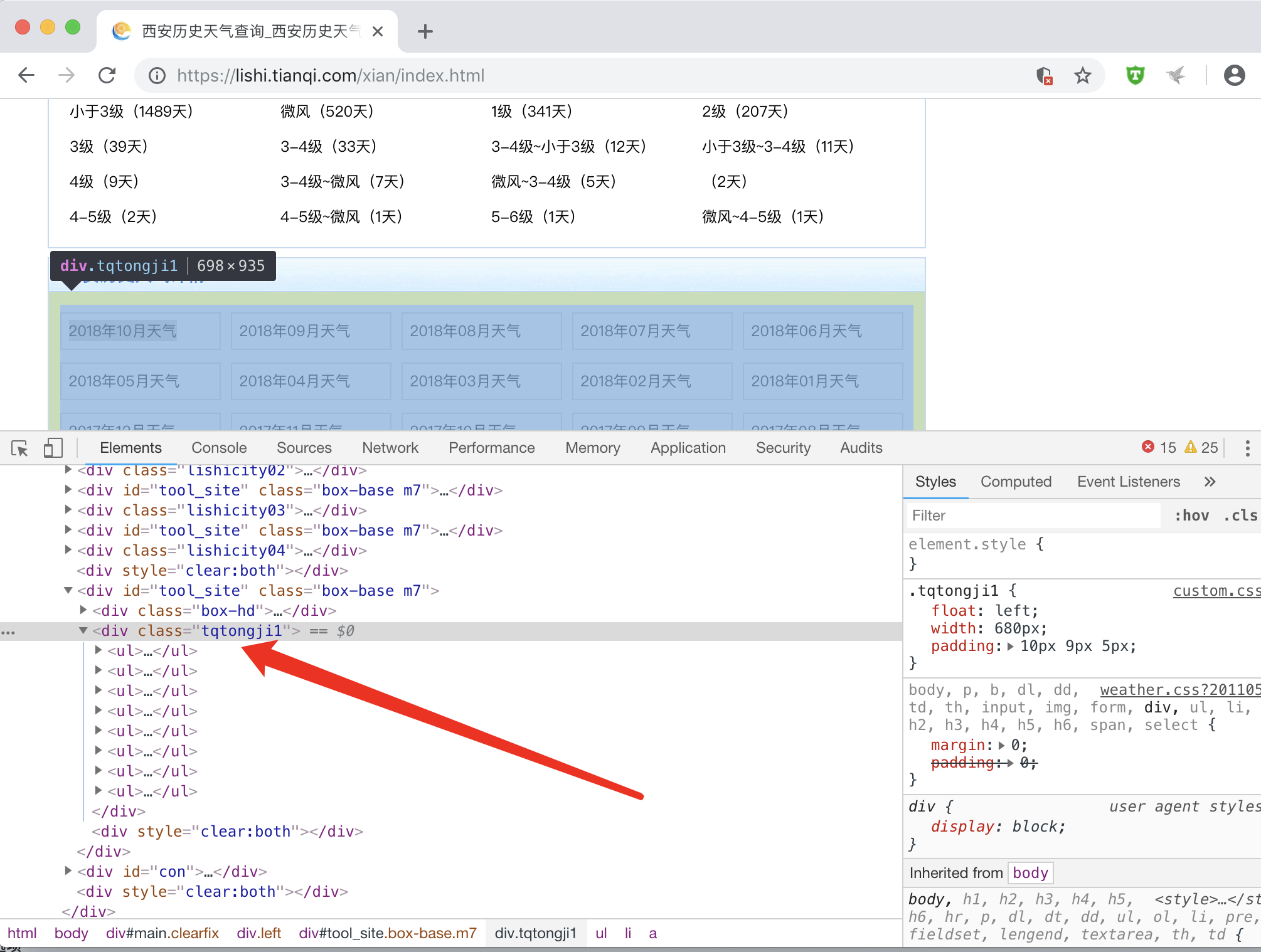
PyQuery的css 选择器可以起床了..
莫慌莫慌。在瞅瞅具体月份点击进入后的页面效果
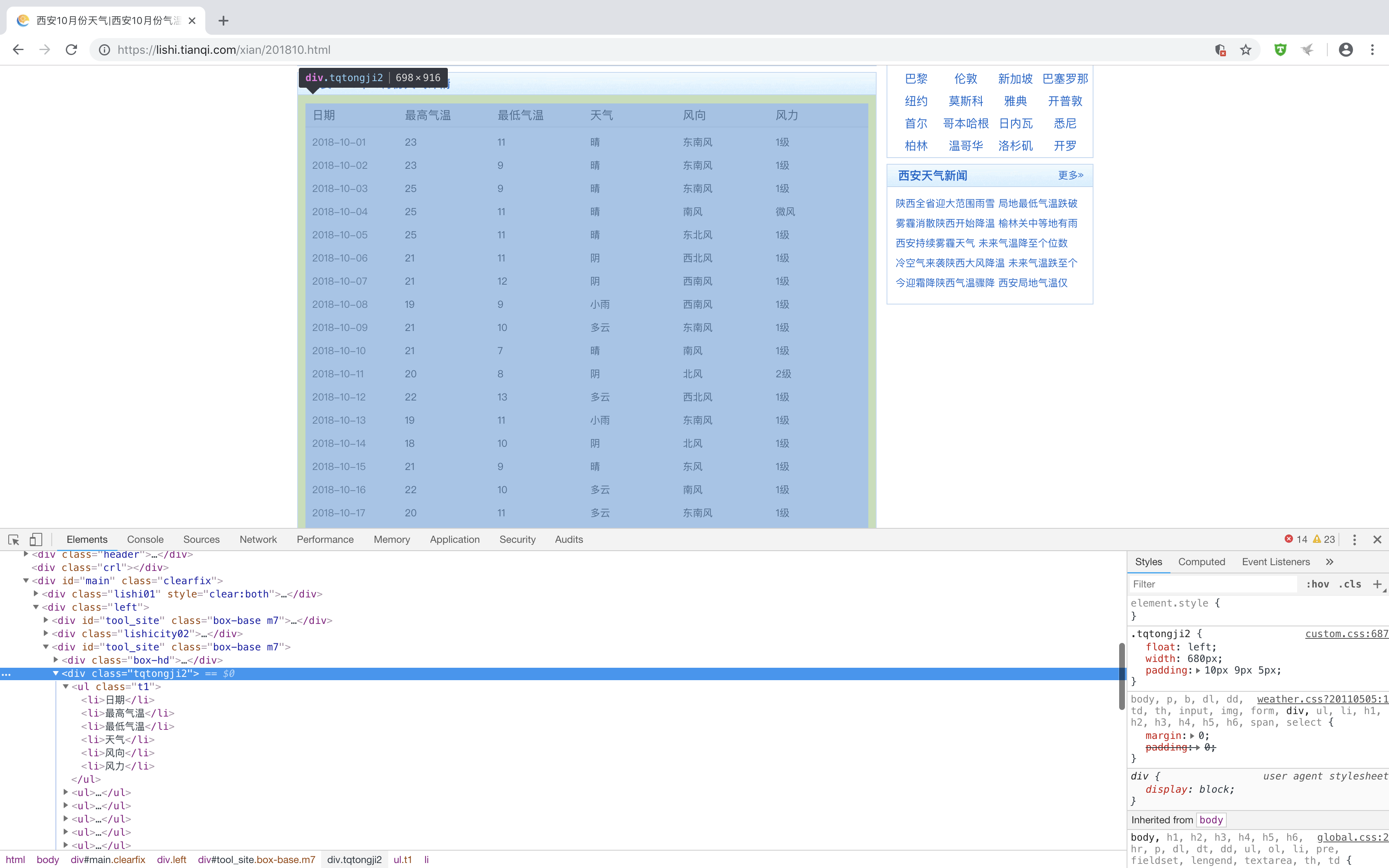
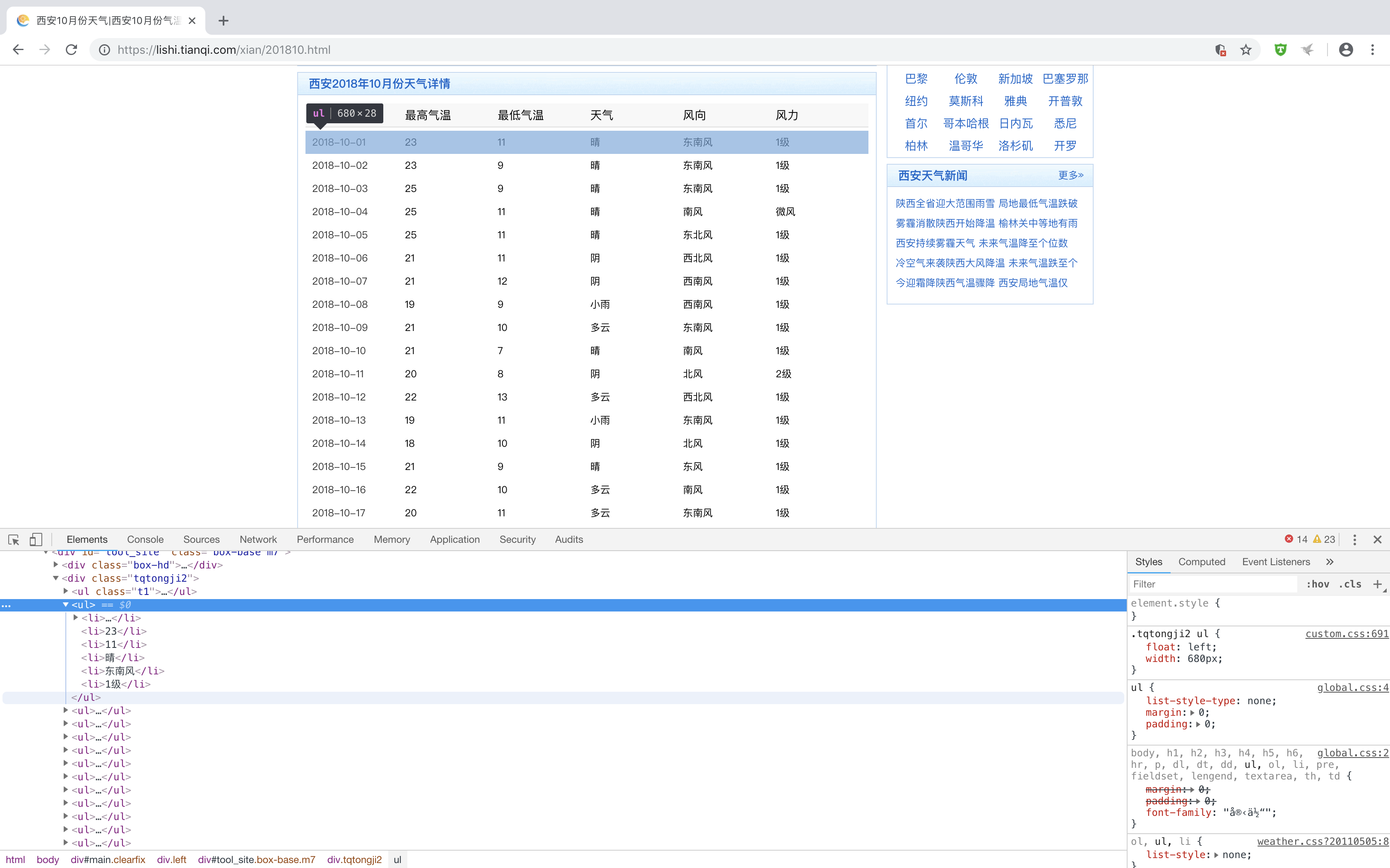
所有的具体每一天的天气信息都被包裹在ul li..
PyQuery.. 开工..
1 # 获取所有的月份的a标签连接。 2 def get_html(): 3 links = [] 4 url = 'https://lishi.tianqi.com/xian/index.html' 5 r1 = requests.get(url,headers) 6 html_doc = pq(r1.text) 7 ul = html_doc('.tqtongji1 > ul:nth-child(1)') 8 lis = ul('li').items() 9 for li in lis: 10 a = li('a') 11 links.append(a.attr('href')) 12 return links
# 获取详细页的具体天气信息 def get_detail(url): r1 = requests.get(url,headers) html_doc = pq(r1.text) uls = html_doc('.tqtongji2').find('ul') lis = uls.items('li') list = [] l = '.'.join(li.text() for li in lis).split('.') # 由于标题信息只有['日期', '最高气温', '最低气温', '天气', '风向', '风力']所以需要字符串截取 for i in range(len(l)): if i%6 == 0: temp = l[i:i+5] list.append(temp) return list
1 # 保存至weather.csv 2 def save_to_csv(data): 3 with open('weather.csv','a') as csv_file: 4 writer = csv.writer(csv_file) 5 for row in data: 6 writer.writerow(row)
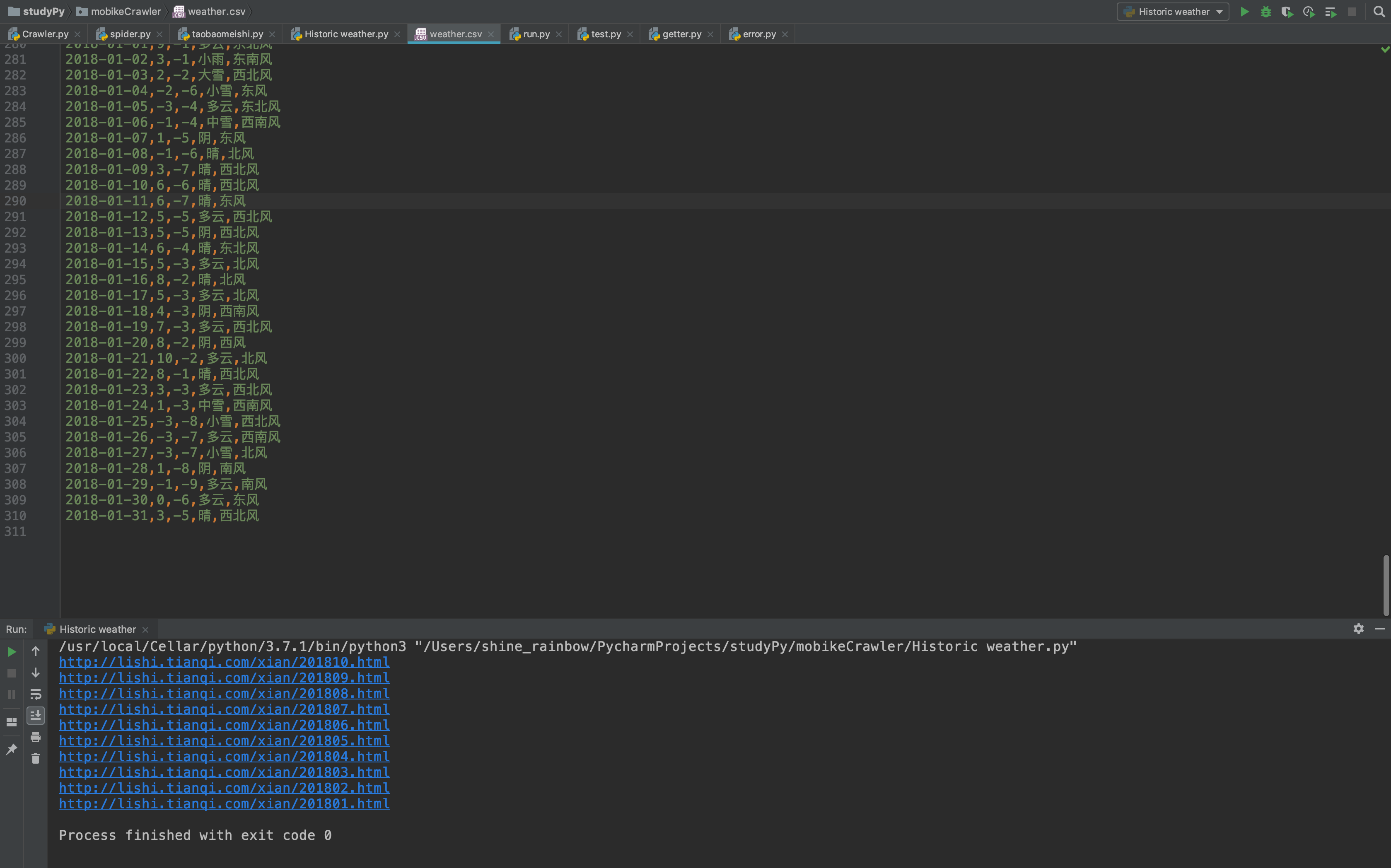
考虑到需要源代码的小伙伴, 已上传至github.. https://github.com/shinefairy/spider/
git clone https://github.com/shinefairy/spider
end~