1. 梯度:对于一元函数,梯度是导数/斜率;对于多元函数,梯度是由偏导数组成的向量
梯度的方向:是函数在给定点上升最快的方向
梯度的反方向:是函数在给定点下降最快的方向
多元函数的梯度:(偏导)
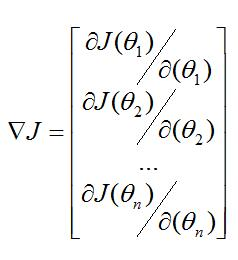

2. 梯度下降:对于给定目标函数f(x),我们需要找到一组参数x,使得f(x)的值最小。
函数在某一点处沿着梯度的反方向逐步迭代,求出函数的局部最小值的过程。我们的最终目的是找到最小值点x(参数),而非最小值(函数值)。
通过梯度下降,一直寻找损失函数的局部最小值,最后得到一个最小值点。无论采取哪一种损失函数,损失函数都与真实标签Y和其他标签Y_ j的分数有关,而分数都与函数f(W, b , xi)有关,因此而权值矩阵W是损失函数的影响因素之一。而梯度下降就是为了寻找损失函数最小值所对应的权值矩阵W,就是要找到使得损失值(目标值)最小的权值矩阵W。也就是,我们想知道参数W取何值时,损失值(目标值)才能最小。梯度下降是让梯度中所有偏导函数都下降到最低点的过程。
在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。
梯度下降:逐步迭代,寻找最小值点的过程
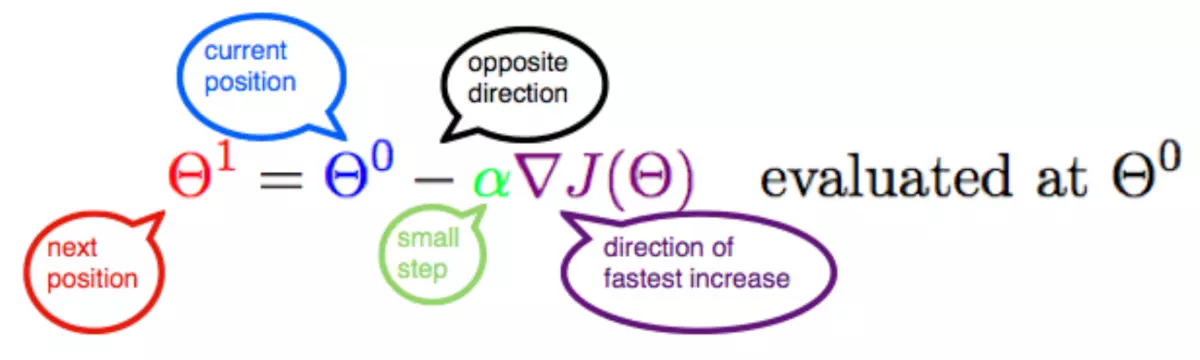
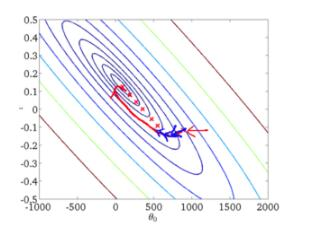
3. 梯度下降的公式:
![]()
参数:下一个位置点、当前位置点、学习率(步长)、函数
为什么用负号?因为是梯度下降,沿着梯度的反方向进行的
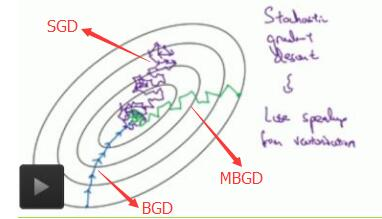
4. 梯度下降的分类:
一般训练时,有n个样本,将n个样本分为m个batch,每个batch包含k个样本;因为分批次训练收敛速度比较快,所以将所有的样本分为m个batch
①批量梯度下降(BGD)/ Batch Gradient Descent:是指在每一次迭代时使用所有样本(m个batch)来进行梯度的更新
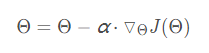
(1)一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
(3)当样本数目 m 很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
批量梯度下降法:
②小批量梯度下降(MBGD)/ Min-Batch Gradient Descent:每次迭代选择k个batch来对参数进行更新
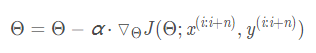
(1)通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。
(2)每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
(3)可实现并行化。
(4)batch_size的不当选择可能会带来一些问题。
③随机梯度下降 (SGD)/ Stochastic Gradient Descent:每次迭代使用一个batch来对参数进行更新

(1)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
(2)准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
(3)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(4)不易于并行实现。
随机梯度下降法:
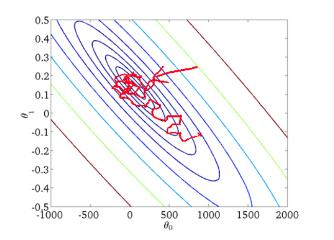
附:三种梯度下降法的对比