1.换行
每行不超过80个字符
圆括号,中括号,花括号会将行隐式连接,反斜杠也会进行隐式连接
反斜杠可以控制换行
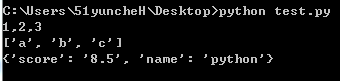
#python代码规范 def foo(argv1,argv2, argv3): print '%s,%s,%s'%(argv1,argv2,argv3) args=['a','b', 'c'] print args dictobj={'name':'python', 'score':'8.5'} print dictobj foo(1,2,3)
运行结果:
#python代码规范 obj="""sdfsdfsdfsdf 23424324234""" print obj obj2=('sdfsdfsdfsdf' '23424324234') print obj2 obj3=1+ 2 print obj3
运行结果:
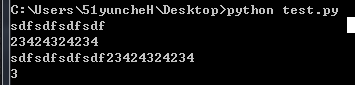
三个双引号,表示引号内的为一个字符串,
括号表示可以将两个字符串隐式连接成一个。
2.不要在返回语句,条件语句中使用括号
# #python代码规范 def func(foo): if foo: return 'yes' if not foo: return('no') print func(False)
3.缩进
不要使用tab缩进,使用空格
4.空格
1)#注释符后面加一个空格
2)list,dict,tuple,set中,:后面加空格
3)+-*/两端加空格
4)参数列表中的=,括号不需要加空格
# 列表 list1 = [1, 2, 3] # 字典 dict1 = {'a': '1', 'b': '2','c': '3'} # 元组不可更改,元素可重复 tup1 = ('a', 'a') # 集合元素不可重复 set1 = ('a', 'b') # 操作符两端加空格 val1 = val2 + val3 # 参数列表中的=两端不需要空格,括号两端不需要空格 def func1(a=1, b=2): return a+b
5.命名
Class类,使用紧凑双驼峰法,如MyClass
其余使用小写, 中间用下划线_连接,如:my_func,my_variable
6.导入import
1)import放在文件开头,导入顺序为
标准库
第三方库
本项目的package,module
2)不要使用from foo import *,使用from foo import func1,var1
3)不要使用隐式的相对导入,最好使用全路径导入
import sys import os from tornado.web import RequestHandler from mymessage import var1,var2
7.异常
1)只在可能异常的地方使用try/except
8.字符串
1)使用join拼接字符串
2)使用str类型方法,而不是string模块的方法
3)使用startswith和endswith比较前缀和后缀
4)使用format方法格式化字符串
9.比较
1)空的list,str,tuple,set,dict和0,0.0,None都是False
2)使用if some_list而不是if len(some_list)判断某个list是否为空
3)使用is,is not和单例(如None)进行比较,而不是==或!=
4)使用if a is not None而不是if not a is None
5)不要用==或!=和True或False比较
6)使用in操作,如key in dict而不是dict.has_key()
7)list的查找是线性的,复杂度为o(n),set底层是hashtable,复杂度为o(1),但比list占用更多内存空间
8)使用列表表达式,字典表达式,生成器
l=["egg%s"%i for i in range (100) if i >90 and i<95] print(l) dict1={'a': '1', 'b': '2'} l=[item for item in dict1] print l g = (x * x for x in range(10)) print g
运行结果:

9.dict的get方法可以指定默认值,[]可以抛出Keyerror
dict.get(key, default=None)
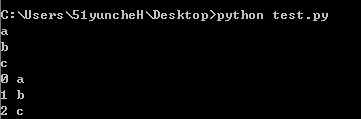
10.使用for item in list迭代list,for index,item in enumerate(list)迭代下标和lis
l=['a','b','c'] for item in l: print item for index,item in enumerate(l): print index,item
运行结果:
11.使用内建函数sorted和List.sort()进行排序
aList = [123, 'xyz', 'zara', 'abc', 'xyz'] print sorted(aList) aList.sort() print aList
运行结果:

List.sort()在原列表上进行排序
sorted()产生一个新的列表
12.使用lambda表达式
g=lambda x:x+1 print g(1)
运行结果:

lambda表达式相当于定义了一个匿名函数,参数为x,函数体为return x+1,如
def g(x): return x+1
13.使用defaultdict ,Counter等冷门但好用的数据结构
14.使用装饰器
装饰器一般提供和函数本身功能无关的功能,如插入日志等。
不带参数装饰器:
import datetime def mylog(func): def wrapper(*args, **kw): print "log %s"%datetime.datetime.now().strftime('%Y-%m-%d') return func(*args, **kw) return wrapper @mylog def add(a,b): print a+b add(1,2)
运行结果:

带参数装饰器:
import datetime def mylog(name): def decorator(func): def wrapper(*args, **kw): print "%s log %s"%(name,datetime.datetime.now().strftime('%Y-%m-%d')) return func(*args, **kw) return wrapper return decorator @mylog('process1') def add(a,b): print a+b add(1,2)
运行结果:

15.使用with处理上下文
16.有时候对类型不要做太过严格的限制,适当利用Python的鸭子类型(Duck Type)
17.使用logging记录日志,配置好格式和级别