插入排序
算法分析
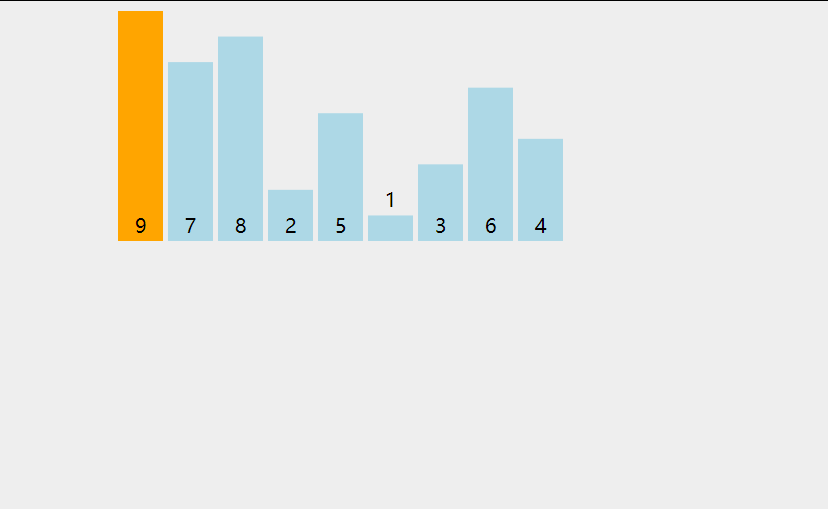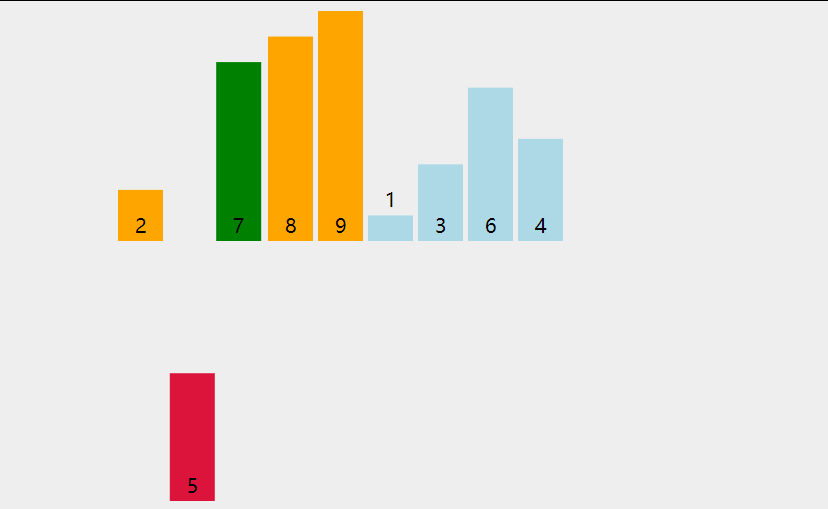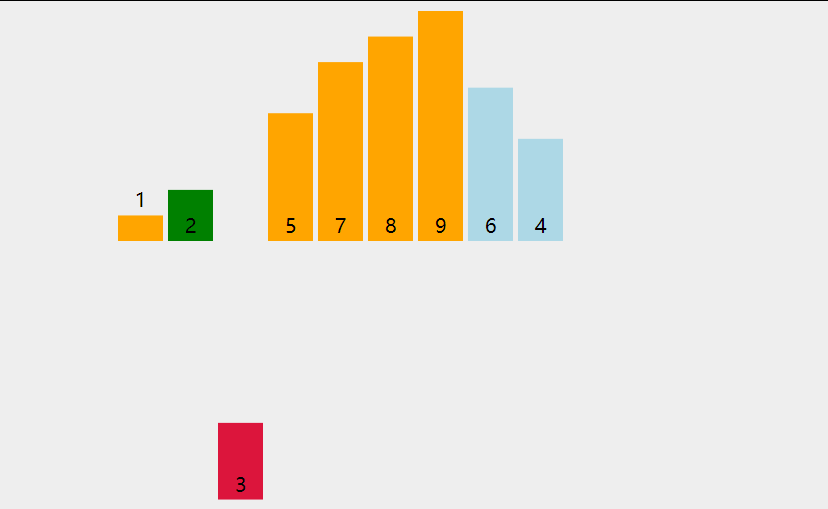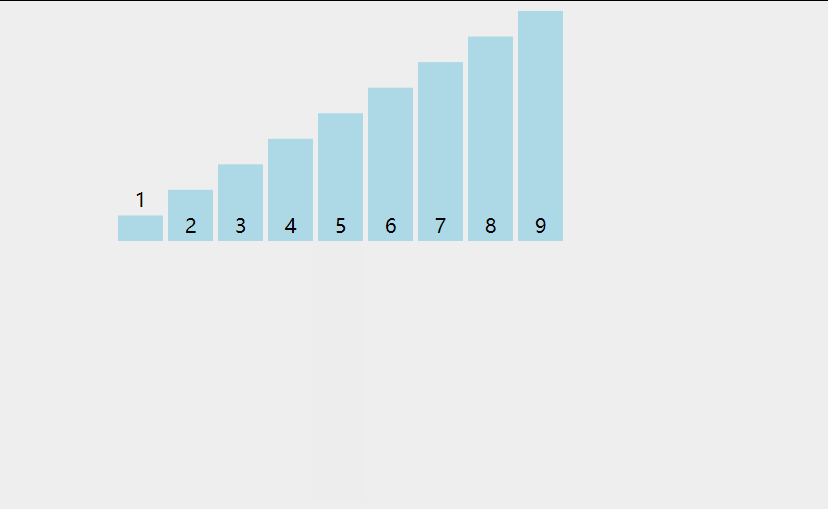
两次循环, 大循环对队列中的每一个元素拿出来作为小循环的裁定对象
小循环对堆当前循环对象在有序队列中寻找插入的位置
性能参数
空间复杂度 O(1)
时间复杂度 O(n^2)
详细代码解读
import random def func(l): # 外层循环: 对应遍历所有的无序数据 for i in range(1, len(l)): # 备份 取出数据 temp = l[i] # 记录取出来的下标值 pos = i # 内层循环: 对应从后往前扫描所有有序数据 """ i - 1 > 从最后一个有序数据开始, 即无序数据前一位 -1 > 扫描到下标 0 为止, 要包括第一个, 因此设置 -1 往后推一位 -1 > 从后往前扫描 """ for j in range(i - 1, -1, -1): # 若有序数据 大于 取出数据 if l[j] > temp: # 有序数据后移 l[j + 1] = l[j] # 更新数据的插入位置 pos = j # 对应所有有序数据比取出数据大的情况 # 若有序数据 小于/等于 取出数据 else: pos = j + 1 break # 在指定位置插入数据 l[pos] = temp if __name__ == '__main__': l = list(range(1, 13)) random.shuffle(l) func(l) print(l)
简单实例
import random def foo(l): for i in range(1, len(l)): temp = l[i] pos = i for j in range(i - 1, -1, -1): if temp < l[j]: l[j + 1] = l[j] pos = j else: pos = j + 1 break l[pos] = temp return l if __name__ == '__main__': l = list(range(13)) random.shuffle(l) print(l) # [12, 0, 4, 5, 6, 2, 11, 10, 8, 7, 3, 1, 9] print(foo(l)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
冒泡排序
算法分析
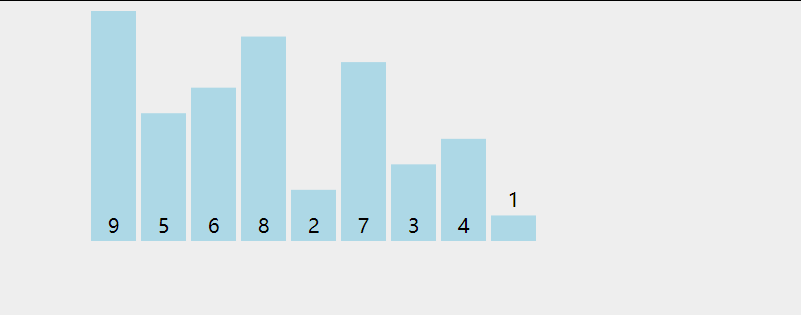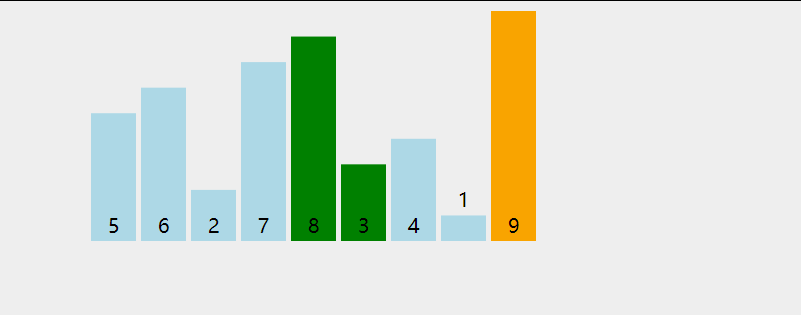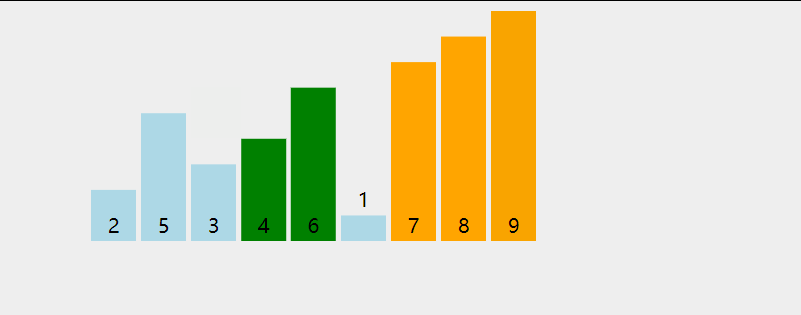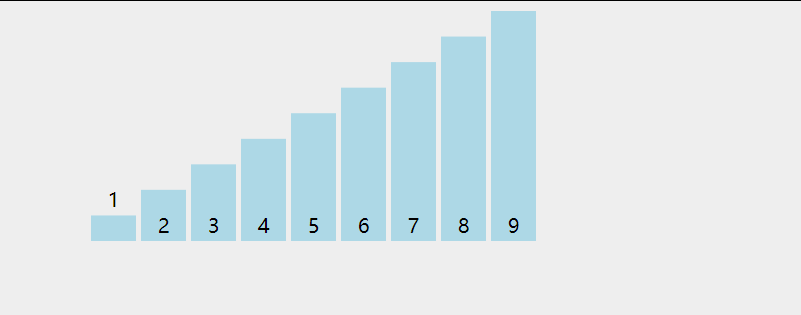
两两比较, 每次比较出一个未排序队列的最大值,让只在队列右侧排列
两次循环, 大循环每次输出一个当前最大值.
小循环进行具体的数值比对
性能参数
空间复杂度 O(1)
时间复杂度 O(n^2)
详细代码
""" 入学后, 第一次上体育课, 体育老师要求大家排队, 按照身高从低到高排队 获取全班 10 名同学的身高 """ """ 外层循环 大循环控制总循环次数 内层循环 小循环控制如歌得出这个最大值 计算大小, 然后彼此交换 """ import random """ 基础版 """ def func(l): # 外层循环: 走访数据的次数 for i in range(len(l) - 1): # 内层循环: 每次走访数据时, 相邻对比次数 for j in range(len(l) - i - 1): # 要求从低到高 # 如次序有误就交换 if l[j] > l[j + 1]: l[j], l[j + 1] = l[j + 1], l[j] # 遍历次数 print("走访次数:", i + 1) """ 升级版 """ def foo(l): # 外层循环: 走访数据的次数 for i in range(len(l) - 1): # 设置是否交换标志位 flag = False # 内层循环: 每次走访数据时, 相邻对比次数 for j in range(len(l) - i - 1): # 要求从低到高 # 如次序有误就交换 if l[j] > l[j + 1]: l[j], l[j + 1] = l[j + 1], l[j] # 发生了数据交换 flag = True # 如果未发生交换数据, 则说明后续数据均有序 if flag == False: break # 跳出数据走访 # 遍历次数 print("走访次数:", i + 1) if __name__ == '__main__': l = list(range(1, 11)) random.shuffle(l) print("排序前:", l) # func(l) foo(l) print("排序后:", l)
简单代码
import random def foo(l): for i in range(len(l) - 1): for j in range(len(l) - i - 1): if l[j] > l[j + 1] and j != len(l): l[j], l[j + 1] = l[j + 1], l[j] return l if __name__ == '__main__': l = list(range(13)) random.shuffle(l) print(l) # [2, 3, 0, 7, 8, 11, 10, 6, 4, 5, 12, 1, 9] print(foo(l)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
升级版代码
import random def foo(l): for i in range(len(l) - 1): flag = 1 for j in range(len(l) - i - 1): if l[j] > l[j + 1] and j != len(l): l[j], l[j + 1] = l[j + 1], l[j] flag = 0 if flag: break return l if __name__ == '__main__': l = list(range(13)) random.shuffle(l) print(l) # [0, 9, 1, 3, 8, 12, 6, 5, 2, 7, 10, 11, 4] print(foo(l)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
快速排序
算法分析


首先任意取一个元素作为关键数据 ( 通常取首元素
然后将所有比他小的数据源放在其前面, 所有比它大的放在他后面
通过一次排序将要排序的数据分为独立的两部分
然后按照该方法再递归对两部分数据进行快速排序
性能参数
时间复杂度 O(nlogn)
空间复杂度 O(logn)
稳定性 不稳定
详细代码
# 快速排序 import random def quick(l): # 递归退出条件 # 仅剩一个元素无需继续分组 if len(l) < 2: return l # 设置关键数据 a = l[0] # 找出所有比 a 大的数据 big = [x for x in l if x > a] # 找出所有比 a 小的数据 small = [x for x in l if x < a] # 找出所有与 a 相等的数据 same = [x for x in l if x == a] # 拼接数据排序的结果 return quick(small) + same + quick(big) if __name__ == '__main__': l = list(range(1, 25)) random.shuffle(l) l = quick(l) print(l)
二分查找
算法分析
只能对有序队列进行查找, 利用和中间值进行对比, 然后基于判断将队列丢弃一半的方式
性能参数
时间复杂度 O(log2 n)
空间复杂度 O(1)
详细代码
""" 1. 切分成两部分,取中间值来判断 2. 如何定义下一次的范围: 大于中间值, 在左侧找 小于中间值, 在右侧找 3. 查找失败情况: 中间值 小于左端 或者 中间值 大于 右端 """ """ 扑克牌 只取 黑桃 13 张, 用 1-13 表示, 将牌从小到大排序, 反面向上排成一排, 找到黑桃 6 的位置 """ """ l 原始数据 k 待查找数据 left 首元素下标值 right 尾元素下标值 """ """ 递归方式实现 """ def func(l, k, left, right): # 递归退出条件 if left > right: # 查找结束 return -1 # 获取中间元素对应下标值 middle = (left + right) // 2 # 对比中间元素 和 查找元素 if l[middle] == k: return middle elif l[middle] > k: # 中间值 大于 查找值 # 查找范围是 中分后的 左边部分 # 左侧下标值不变, 右侧下标值变为 middle 前一位 right = middle - 1 return func(l, k, left, right) else: # 中间值 小于 查找值 # 查找范围是 中分后的 右边部分 # 左侧下标值变为 middle 后一位, 右侧下标值不变 left = middle + 1 return func(l, k, left, right) """ 循环方式实现 """ def foo(l, k): left = 0 right = len(l) - 1 while left <= right: mid = (left + right) // 2 if l[mid] > k: right = mid - 1 elif l[mid] < k: left = mid + 1 elif l[mid] == k: return midreturn -1 if __name__ == '__main__': # l = list(range(1, 14)) # k = 8 # right = len(l) - 1 # res = func(l, k, 0, right) l = list(range(1, 14)) k = 10 right = len(l) - 1 res = foo(l, k) if res == -1: print("查找失败") else: print("查找成功, 第 %d 张拿到" % res)
简单代码
def foo(l, k): left = 0 right = len(l) - 1 while left <= right: mid = (left + right) // 2 if l[mid] > k: right = mid - 1 elif l[mid] < k: left = mid + 1 elif l[mid] == k: return mid return -1 if __name__ == '__main__': l = list(range(13)) print(l) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] print(foo(l, 8)) # 8
总结
冒泡排序
重复走访所有要排序的数据,
依次比较每两个相邻的元素,
如果两者次序错误就交换
重复上面过程 直到没有需要被调换的内容为止
插入排序
将数据插入到已经有序的数据中, 从而得到一个新的有序数据
默认首元素自然有序, 取出下一个元素, 对已经有序的数据从后向前扫描
若扫描的有序数据大于取出数据, 则该有序数据后移
若扫描的有序数据小于取出数据, 则在该有序数据后插入取出数据
若扫描的所有的有序数据大于取出数据, 则在有序数据的首位插入取出数据
特点
数据只移动不交换, 优于冒泡
快速排序
首先任意取一个元素作为关键数据 ( 通常取首元素 )
然后将所有比他小的数据源放在其前面
(从小到大)所有比它大的放在他后面
通过一次排序将要排序的数据分为独立的两部分
然后按照该方法再递归对两部分数据进行快速排序
特点
每次若能均匀分组则排序速度最快, 但是不稳定