摘要: 这篇文章将会手把手教你安装hadoop,只要你细心按照文章中的步骤操作,hadoop肯定能正确安装,绝对不会让你崩溃
博主福利 给大家赠送一套hadoop视频课程
授课老师是百度 hadoop 核心架构师
内容包括hadoop入门、hadoop生态架构以及大型hadoop商业实战案例。
讲的很细致, MapReduce 就讲了 15 个小时。
学完后可以胜任 hadoop 的开发工作,很多人学的这个课程找到的工作。
(包括指导书、练习代码、和用到的软件都打包了)
先到先得先学习。联系老师微信ganshiyu1026,备注OSchina。即可免费领取
部分视频截图展示

如果你看了我的上一篇文章,那此时你对hadoop已经有了一个大概的了解,那接下来这篇文章就教大家怎么安装hadoop环境,只要你用心,仔细的跟着文章中讲到的做,肯定能正确安装。
安装hadoop环境
由于大家在学习hadoop时候,主要以Hadoop 1.0环境为主学习就可以,所以这主要介绍如何搭建Hadoop 1.0分布式环境。
整个分布式环境运行在带有linux操作系统的虚拟机上,至于虚拟机和linux系统的安装这里暂不做过多介绍。
安装Hadoop分布式环境:
1) 下载Hadoop安装包:
百度网盘下载地址:点击下载 中可以找到hadoop-1.2.1-bin.tar.gz文件
使用securtCRT的rz功能上传hadoop-1.2.1-bin.tar.gz这个文件到虚拟机的系统中。
同样在securtcrt中ll时,能得到
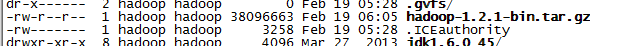
2) 安装Hadoop安装包:
l 首先将安装包解压缩:
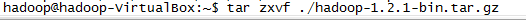
l Linux终端执行cd进入相应目录:

l 新增tmp目录,mkdir /home/hadoop/hadoop-1.2.1/tmp
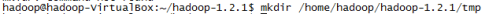
3) 配置Hadoop:
l 使用vim修改master文件内容:

将localhost修改成master:
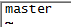
最后保存退出。
l 修改slaves文件
注意,这里准备设置几台slave机器,就写几个,因为当前分布式环境有四个虚拟机,一台做master,三台做slave,所以这里写成了三个slave

l 修改core-site.xml文件:
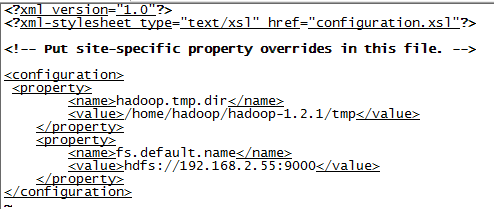
【注意】中间的ip地址,不要输入192.168.2.55,根据自己的情况设置。
l 修改mapred-site.xml文件:
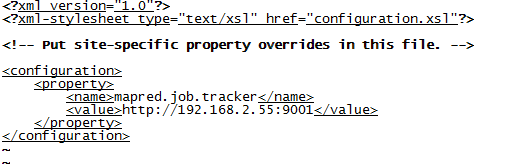
【注意】记得value的内容要以http开头。
l 修改hdfs-site.xml文件:

其中,<value>3</value>视情况修改,如果有三台slave机器,这里设置成3,如果只有1台或2台,修改成对应的值即可。
l 修改hadoo-env.sh文件
在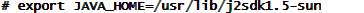
下新增export JAVA_HOME=/home/hadoop/jdk1.6.0_45/

l 修改本地网络配置:编辑/etc/hosts文件
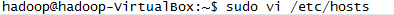
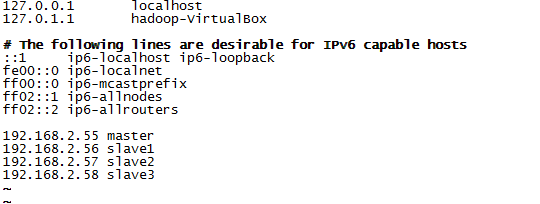
【注意】Ip地址根据具体的情况要进行修改。
4) 复制虚拟机
l 关闭当前虚拟机,并复制多份
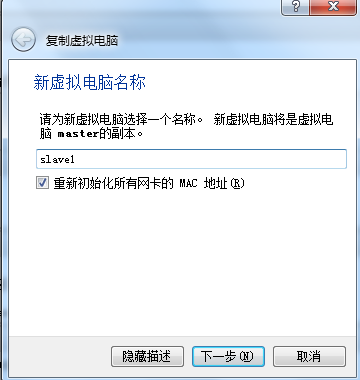
【注意】要选择初始化所有网卡的mac地址
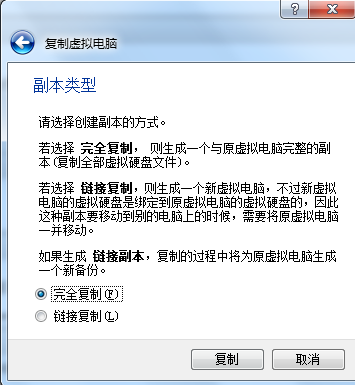
根据自己需求,复制2到3台虚拟机作为slave,同样要确认网络连接方式为桥接。
l 设置所有机器的IP地址
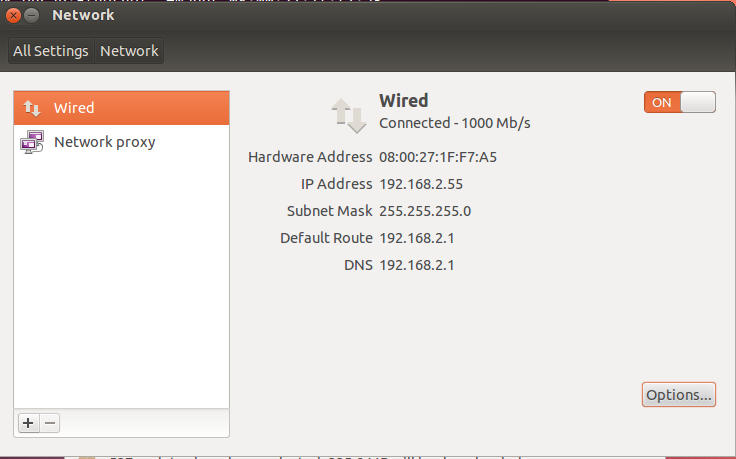
分别启动虚拟机,修改机器的ip 地址,在虚拟机的图形界面里,选择设置 单击打开,在弹出来的窗口里,选择
单击打开,在弹出来的窗口里,选择
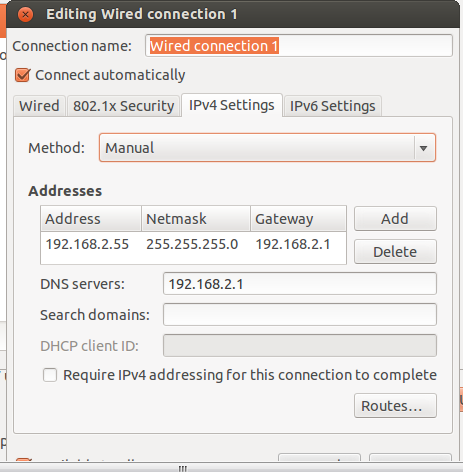
打开 ,修改成如下的形式,选择ipv4 ,分配方式选择成manual。
,修改成如下的形式,选择ipv4 ,分配方式选择成manual。
【注意】具体的ip地址,根据实际的情况来设置,因为培训教室里都是192.168.2.x的网段,所以我这里设置成了192.168.2.x,每个人选择自己的一个ip地址范围,注意不要和其它人冲突了。
5) 建立互信关系
l 生成公私钥,在master机器的虚拟机命令行下输入ssh-keygen,一路回车,全默认

l 复制公钥
复制一份master的公钥文件,cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

同样,在所有的slave机器上,也在命令行中输入ssh-keygen,一路回车,全默认
在所有的salve机器上,从master机器上复制master的公钥文件:

l 测试连接
在master机器上分别向所有的slave机器发起联接请求:
如:ssh slave1
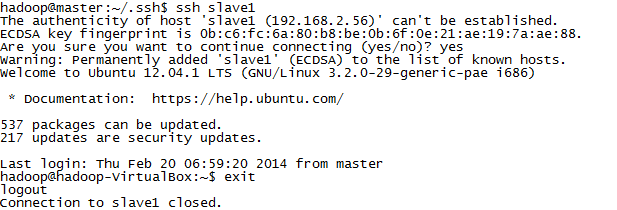
【注意】记得一旦联接上,所有的操作,就视同在对应的slave上操作,所以一定要记得使用exit退出联接。
6) 启动Hadoop:
l 初始化:在master机器上,进入/home/hadoop/hadoop-1.2.1/bin目录
在安装包根目录下运行./hadoop namenode –format来初始化hadoop的文件系统。

l 启动
执行./start-all.sh,如果中间过程提示要判断是否,需要输入yes

输入jps,查看进程是否都正常启动。
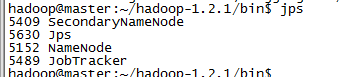
如果一切正常,应当有如上的一些进程存在。
7) 测试系统
输入./hadoop fs –ls /
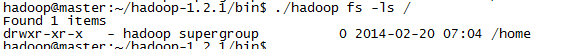
能正常显示文件系统。
如此,hadoop系统搭建完成。否则,可以去/home/hadoop/hadoop-1.2.1/logs目录下,查看缺少的进程中,对应的出错日志。